

이제 막 Python을 접하기 시작했는데, 그리고 많은 사람들이 크롤러를 가지고 노는 것을 보았습니다. 검색해 보니 많은 사람들이 웹 크롤러를 사용하여 가장 먼저 하는 일은 로그인을 더 어렵게 하기 위해 로그인을 시뮬레이션한 다음 데이터를 얻는 것입니다. , 로그인을 시뮬레이션할 수 있는 Python 3.x 데모는 인터넷에 거의 없습니다. 참고로 저는 Html을 잘 모르기 때문에 처음 Python 크롤러를 작성하는 것은 매우 어려웠지만 최종 결과는 만족스러웠습니다. 이번에는 학습 과정을 종료합니다. >브라우저:
Chrome
를 클릭하고 공개 계정 비밀번호를 입력하여 입력한 다음 마지막으로 관련 정보를 입력하여 점수 양식을 얻으세요. 여기서 로그인에는
인증 코드개발자 패널여기서 우리 학교 교학처 문의 시스템의 비밀번호는 public jwc, 즉 병음의 약어를 입력하고 로그인을 합니다. POST 요청에 주목하세요.
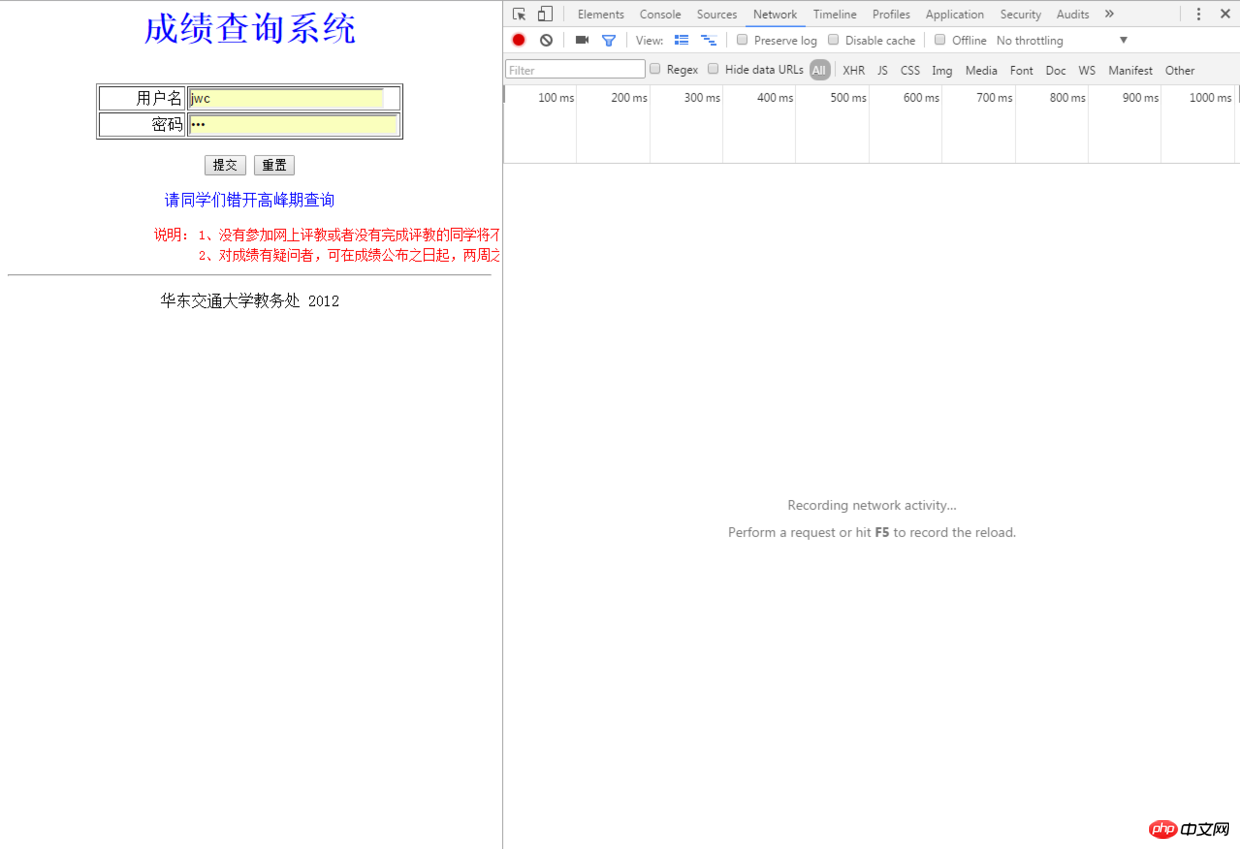
게시 양식 데이터 가져오기 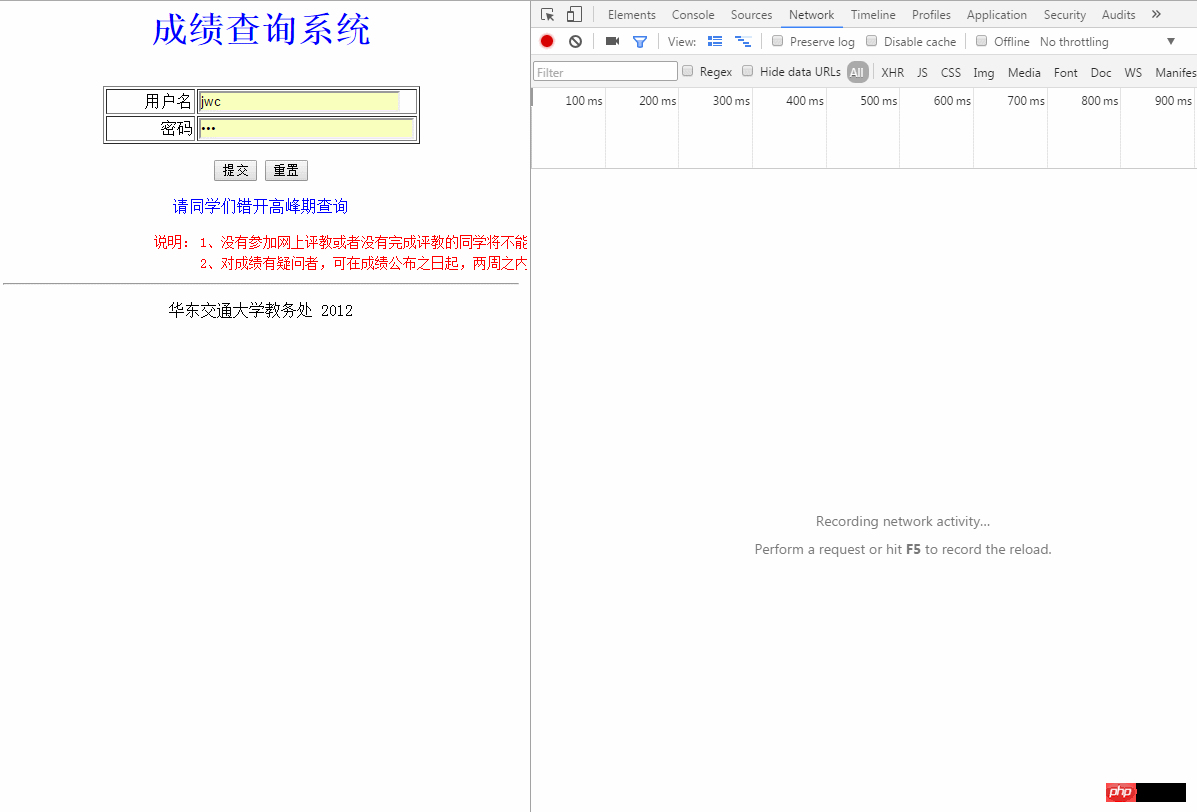
이런 방법으로 양식 데이터를 전달할 수 있습니다. 로그인할 때 브라우저를 통해 서버에 연결합니다. 이 양식을 살펴보세요.
양식 데이터 보기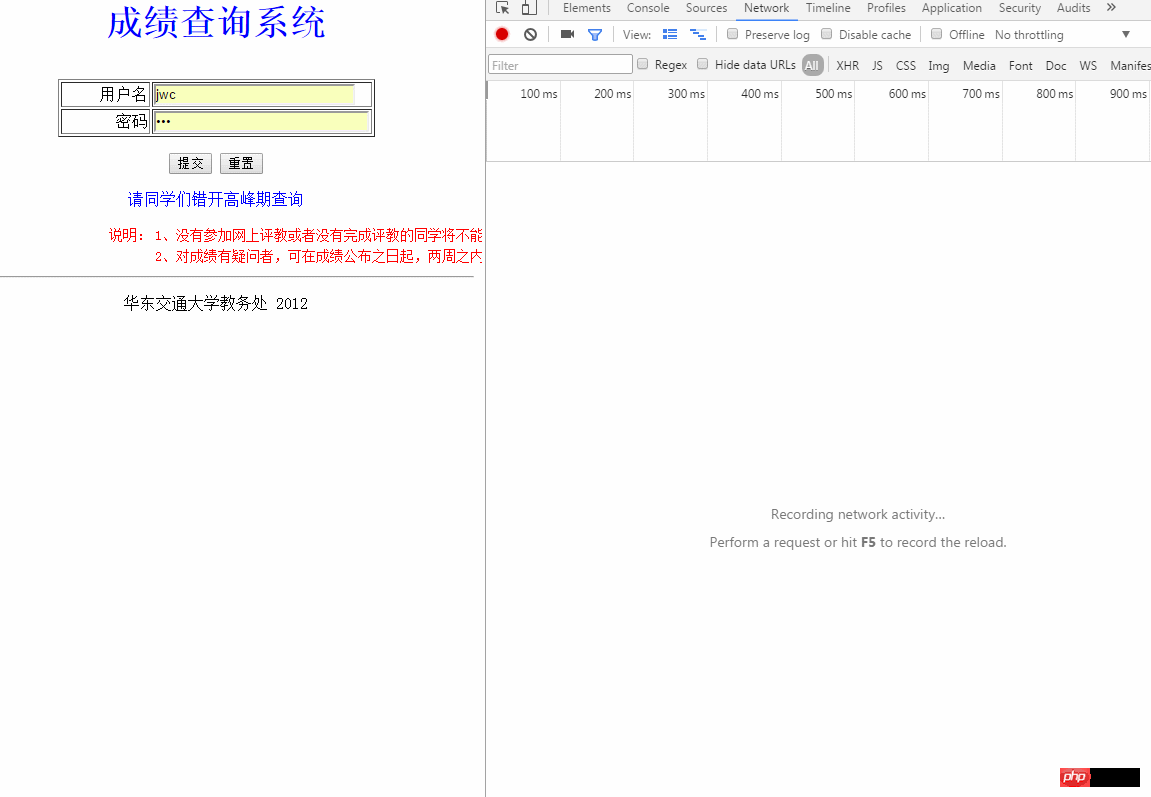
여기 있습니다. 세 가지 매개변수, 즉 user, pass, Submit을 전달해야 합니다. 이 아이디어를 사용하면 이 코드의 첫 번째 단계를 작성할 수 있습니다.
코드로 직접 이동:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests
url = 'http://jwc.ecjtu.jx.cn/mis_o/login.php'
datas = {'user': 'jwc',
'pass': 'jwc',
'Submit': '%CC%E1%BD%BB'
}
headers = {'Referer': 'http://jwc.ecjtu.jx.cn/mis_o/login.htm',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
sessions = requests.session()
response = sessions.post(url, headers=headers, data=datas)
print(response.status_code)코드 출력:
200
는 여기서 시뮬레이션된 로그인이 성공했음을 보여줍니다. 이를 사용하려면 중국어 문서를 확인할 수 있습니다. HTTP 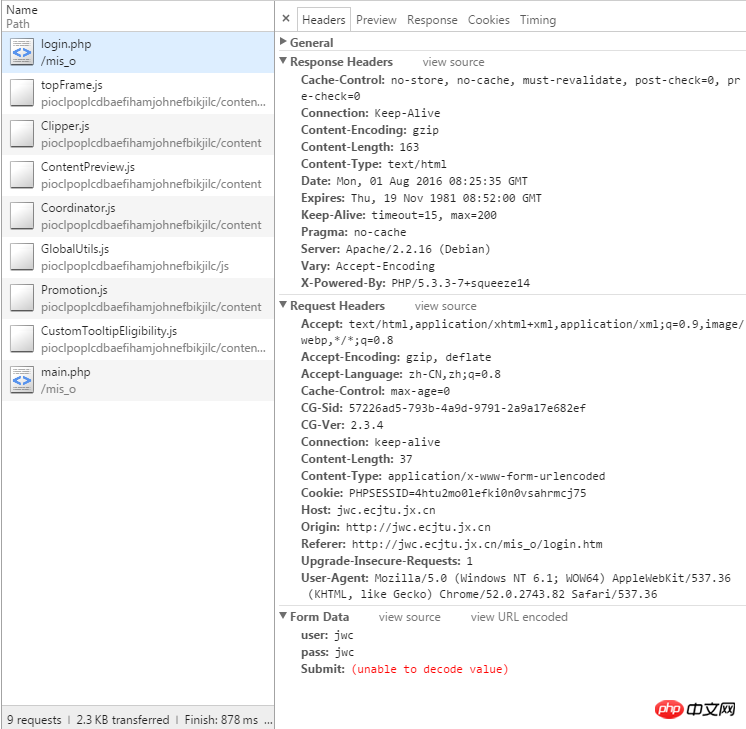 for
for
사용하기 쉽고 사용하기 쉽기 때문에 URL 주소를 전달하고 요청 헤더를 구성하기만 하면 됩니다. , 브라우저 로그인을 시뮬레이션하기 위해 post 메소드에 필요한 데이터를 전달합니다. 추가 결과를 얻기 위한 작업이 있으므로 여기에서는 연결 유지가 사용됩니다. 여기에서 최종 반환 코드만 보면 성공합니다. 다음 단계에 따라 다릅니다.
캡처 패킷
여기서 코드를 단순화하기 위해 다음을 입력하도록 설정했습니다. 학생 번호를 사용하여 모든 점수를 쿼리하고 다른 판단도 줄입니다.
예 게시물 데이터 캡처 
또한 확인하세요. 게시물 데이터 :
게시물 보기
여기서는 학번이 분석되는 상황이라 나머지는 다 비어있어서 쓸 수 있어요 점수 조회 코드:
score_healders = {'Connection': 'keep-alive',
'User - Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Content - Type': 'application / x - www - form - urlencoded',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Content - Length': '69',
'Host': 'jwc.ecjtu.jx.cn',
'Referer': 'http: // jwc.ecjtu.jx.cn / mis_o / main.php',
'Upgrade - Insecure - Requests': '1',
'Accept - Language': 'zh - CN, zh;q = 0.8'
}
score_url = 'http://jwc.ecjtu.jx.cn/mis_o/query.php?start=' + str(
pagenum) + '&job=see&=&Name=&Course=&ClassID=&Term=&StuID=' + num
score_data = {'Name': '',
'StuID': num,
'Course': '',
'Term': '',
'ClassID': '',
'Submit': '%B2%E9%D1%AF'
}
score_response = sessions.post(score_url, data=score_data, headers=score_healders)
content = score_response.content这里解释一下上面的代码,上面的score_url 并不是浏览器上显示的地址,我们要获取真正的地址,在Chrome下右键--查看网页源代码,找到这么一行:
a href=query.php?start=1&job=see&=&Name=&Course=&ClassID=&Term=&StuID=xxxxxxx
这个才是真正的地址,点击这个地址转入的才是真正的界面,因为这里成绩数据较多,所以这里采用了分页显示,这个start=1说明是第一页,这个参数是可变的需要我们传入,还有StuID后面的是我们输入的学号,这样我们就可以拼接出Url地址:
score_url = 'http://jwc.ecjtu.jx.cn/mis_o/query.php?start=' + str(pagenum) + '&job=see&=&Name=&Course=&ClassID=&Term=&StuID=' + num
同样使用Post方法传递数据并获取响应的内容:
score_response = sessions.post(score_url, data=score_data,headers=score_healders) content = score_response.content
这里采用Beautiful Soup 4.2.0来解析返回的响应内容,因为我们要获取的是成绩,这里到教务处成绩查询界面,查看获取到的成绩在网页中是以表格的形式存在:
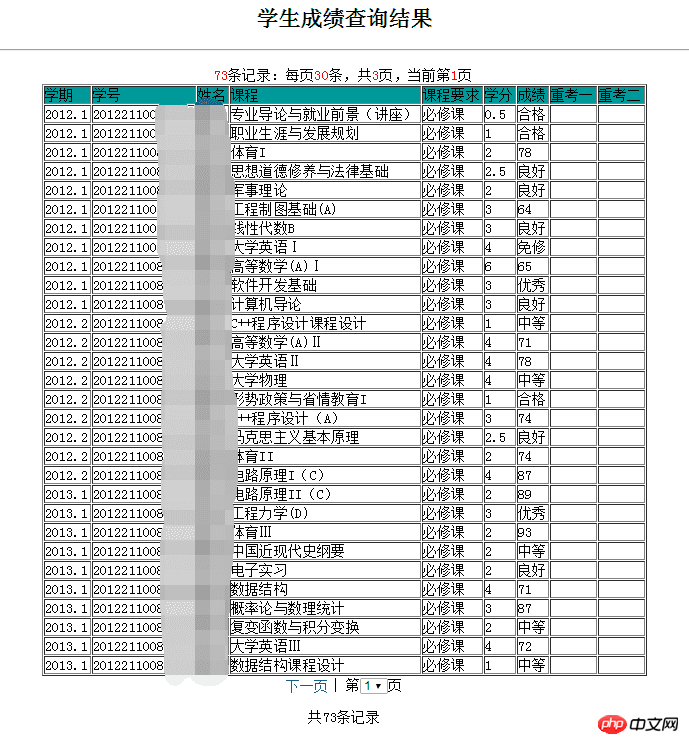
网页源代码
观察表格的网页源代码:
<table align=center border=1> <tr><td bgcolor=009999>学期</td> <td bgcolor=009999>学号</td> <td bgcolor=009999>姓名</td> <td bgcolor=009999>课程</td> <td bgcolor=009999>课程要求</td> <td bgcolor=009999>学分</td> <td bgcolor=009999>成绩</td> <td bgcolor=009999>重考一</td> <td bgcolor=009999>重考二</td></tr> ... ... </tr></table>
这里拿出第一行举例,虽然我不太懂Html但是从这里可以看出来<tr> 代表的是一行,而<td>应该是代表这一行中的每一列,这样就好办了,取出每一行然后分解出每一列,打印输出就可以得到我们要的结果:
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, 'html.parser')
# 找到每一行
target = soup.findAll('tr')这里分解每一列的时候要小心,因为这里表格分成了三页显示,每页最多显示30条数据,这里因为只是收集已经毕业的学生的成绩数据所以不对其他数据量不足的学生成绩的情况做统计,默认收集的都是大四毕业的学生成绩数据。这里采用两个变量i和j分别代表行和列:
# 注:这里的print单纯是我为了验证结果打印在PyCharm的控制台上而已
i=0, j=0
for tag in target[1:]:
tds = tag.findAll('td')
# 每一次都是从列头开始获取
j = 0
# 学期
semester = str(tds[0].string)
if semester == 'None':
break
else:
print(semester.ljust(6) + '\t\t\t', end='')
# 学号
studentid = tds[1].string
print(studentid.ljust(14) + '\t\t\t', end='')
j += 1
# 姓名
name = tds[2].string
print(name.ljust(3) + '\t\t\t', end='')
j += 1
# 课程
course = tds[3].string
print(course.ljust(20, ' ') + '\t\t\t', end='')
j += 1
# 课程要求
requirments = tds[4].string
print(requirments.ljust(10, ' ') + '\t\t', end='')
j += 1
# 学分
scredit = tds[5].string
print(scredit.ljust(2, ' ') + '\t\t', end='')
j += 1
# 成绩
achievement = tds[6].string
print(achievement.ljust(2) + '\t\t', end='')
j += 1
# 重考一
reexaminef = tds[7].string
print(reexaminef.ljust(2) + '\t\t', end='')
j += 1
# 重考二
reexamines = tds[8].string
print(reexamines.ljust(2) + '\t\t')
j += 1
i += 1这里查了很多别人的博客都是用正则表达式来分解数据,表示自己的正则写的并不好也尝试了但是没成功,所以无奈选择这种方式,如果有人有测试成功的正则欢迎跟我说一声,我也学习学习。
把数据保存到Excel
因为已经清楚了这个网页保存成绩的具体结构,所以顺着每次循环解析将数据不断加以保存就是了,这里使用xlwt写入数据到Excel,因为xlwt模块打印输出到Excel中的样式宽度偏小,影响观看,所以这里还加入了一个方法去控制打印到Excel表格中的样式:
file = xlwt.Workbook(encoding='utf-8')
table = file.add_sheet('achieve')
# 设置Excel样式
def set_style(name, height, bold=False):
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name # 'Times New Roman'
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style运用到代码中:
for tag in target[1:]:
tds = tag.findAll('td')
j = 0
# 学期
semester = str(tds[0].string)
if semester == 'None':
break
else:
print(semester.ljust(6) + '\t\t\t', end='')
table.write(i, j, semester, set_style('Arial', 220))
# 学号
studentid = tds[1].string
print(studentid.ljust(14) + '\t\t\t', end='')
j += 1
table.write(i, j, studentid, set_style('Arial', 220))
table.col(i).width = 256 * 16
# 姓名
name = tds[2].string
print(name.ljust(3) + '\t\t\t', end='')
j += 1
table.write(i, j, name, set_style('Arial', 220))
# 课程
course = tds[3].string
print(course.ljust(20, ' ') + '\t\t\t', end='')
j += 1
table.write(i, j, course, set_style('Arial', 220))
# 课程要求
requirments = tds[4].string
print(requirments.ljust(10, ' ') + '\t\t', end='')
j += 1
table.write(i, j, requirments, set_style('Arial', 220))
# 学分
scredit = tds[5].string
print(scredit.ljust(2, ' ') + '\t\t', end='')
j += 1
table.write(i, j, scredit, set_style('Arial', 220))
# 成绩
achievement = tds[6].string
print(achievement.ljust(2) + '\t\t', end='')
j += 1
table.write(i, j, achievement, set_style('Arial', 220))
# 重考一
reexaminef = tds[7].string
print(reexaminef.ljust(2) + '\t\t', end='')
j += 1
table.write(i, j, reexaminef, set_style('Arial', 220))
# 重考二
reexamines = tds[8].string
print(reexamines.ljust(2) + '\t\t')
j += 1
table.write(i, j, reexamines, set_style('Arial', 220))
i += 1
file.save('demo.xls')最后稍加整合,写成一个方法:
# 获取成绩
# 这里num代表输入的学号,pagenum代表页数,总共76条数据,一页30条所以总共有三页
def getScore(num, pagenum, i, j):
score_healders = {'Connection': 'keep-alive',
'User - Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Content - Type': 'application / x - www - form - urlencoded',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Content - Length': '69',
'Host': 'jwc.ecjtu.jx.cn',
'Referer': 'http: // jwc.ecjtu.jx.cn / mis_o / main.php',
'Upgrade - Insecure - Requests': '1',
'Accept - Language': 'zh - CN, zh;q = 0.8'
}
score_url = 'http://jwc.ecjtu.jx.cn/mis_o/query.php?start=' + str(
pagenum) + '&job=see&=&Name=&Course=&ClassID=&Term=&StuID=' + num
score_data = {'Name': '',
'StuID': num,
'Course': '',
'Term': '',
'ClassID': '',
'Submit': '%B2%E9%D1%AF'
}
score_response = sessions.post(score_url, data=score_data, headers=score_healders)
# 输出到文本
with open('text.txt', 'wb') as f:
f.write(score_response.content)
content = score_response.content
soup = BeautifulSoup(content, 'html.parser')
target = soup.findAll('tr')
try:
for tag in target[1:]:
tds = tag.findAll('td')
j = 0
# 学期
semester = str(tds[0].string)
if semester == 'None':
break
else:
print(semester.ljust(6) + '\t\t\t', end='')
table.write(i, j, semester, set_style('Arial', 220))
# 学号
studentid = tds[1].string
print(studentid.ljust(14) + '\t\t\t', end='')
j += 1
table.write(i, j, studentid, set_style('Arial', 220))
table.col(i).width = 256 * 16
# 姓名
name = tds[2].string
print(name.ljust(3) + '\t\t\t', end='')
j += 1
table.write(i, j, name, set_style('Arial', 220))
# 课程
course = tds[3].string
print(course.ljust(20, ' ') + '\t\t\t', end='')
j += 1
table.write(i, j, course, set_style('Arial', 220))
# 课程要求
requirments = tds[4].string
print(requirments.ljust(10, ' ') + '\t\t', end='')
j += 1
table.write(i, j, requirments, set_style('Arial', 220))
# 学分
scredit = tds[5].string
print(scredit.ljust(2, ' ') + '\t\t', end='')
j += 1
table.write(i, j, scredit, set_style('Arial', 220))
# 成绩
achievement = tds[6].string
print(achievement.ljust(2) + '\t\t', end='')
j += 1
table.write(i, j, achievement, set_style('Arial', 220))
# 重考一
reexaminef = tds[7].string
print(reexaminef.ljust(2) + '\t\t', end='')
j += 1
table.write(i, j, reexaminef, set_style('Arial', 220))
# 重考二
reexamines = tds[8].string
print(reexamines.ljust(2) + '\t\t')
j += 1
table.write(i, j, reexamines, set_style('Arial', 220))
i += 1
except:
print('出了一点小Bug')
file.save('demo.xls')在模拟登陆操作后增加一个判断:
# 判断是否登陆
def isLogin(num):
return_code = response.status_code
if return_code == 200:
if re.match(r"^\d{14}$", num):
print('请稍等')
else:
print('请输入正确的学号')
return True
else:
return False最后在main中这么调用:
if name == 'main':
num = input('请输入你的学号:')
if isLogin(num):
getScore(num, pagenum=0, i=0, j=0)
getScore(num, pagenum=1, i=31, j=0)
getScore(num, pagenum=2, i=62, j=0)在PyCharm下按alt+shift+x快捷键运行程序:

控制台输出
控制台会有如下输出(这里只截取部分,不要吐槽没有对齐,这里我也用了格式化输出还是不太行,不过最起码出来了结果,而且我们的目的是输出到Excel中不是吗)
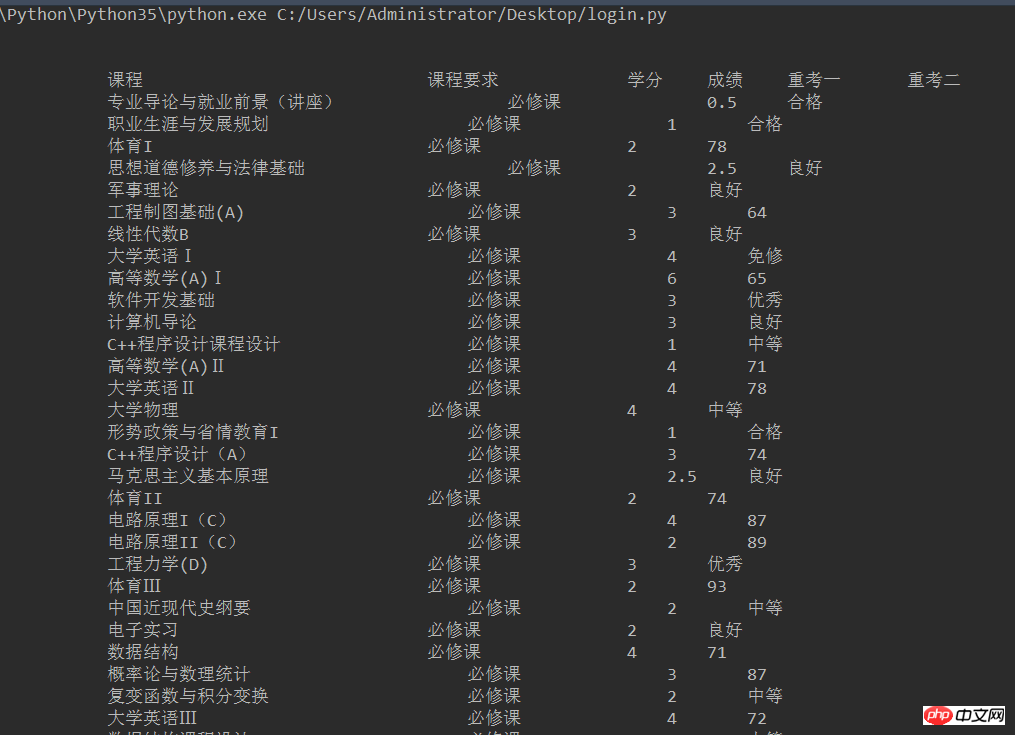
控制台输出
然后去程序根目录找看看有没有生成一个叫demo.xls的文件,我的程序就放在桌面,所以去桌面找:
桌面图标
点开查看是否成功获取:
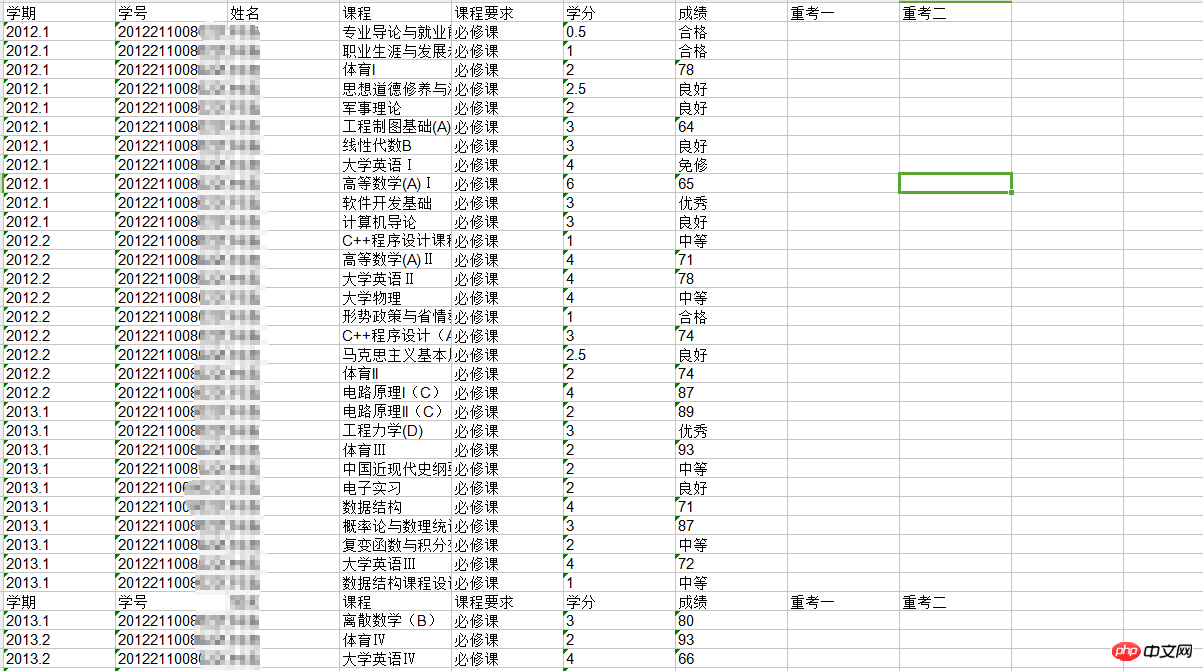
最终获取结果
至此,大功告成
위 내용은 Python 크롤러는 교무처 로그인을 시뮬레이션하고 로컬에 데이터를 저장합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



