

유니코드는 일반적인 문자 인코딩 집합인데, 유니코드는 자바스크립트를 어떻게 지원하나요? 이 기사에서는 유니코드 문자 집합 에 대한 JavaScript 언어 지원에 대해 설명합니다. 독자들이 JavaScript에서 문자 집합의 개념과 사용법을 기본적으로 이해할 수 있기를 바랍니다.
유니코드는 세상의 모든 문자를 하나의 세트에 포함한다는 매우 간단한 아이디어에서 유래되었습니다. 컴퓨터가 이 문자 세트를 지원하는 한 모든 문자를 표시할 수 있으며 더 이상 문자가 깨질 수 없습니다.
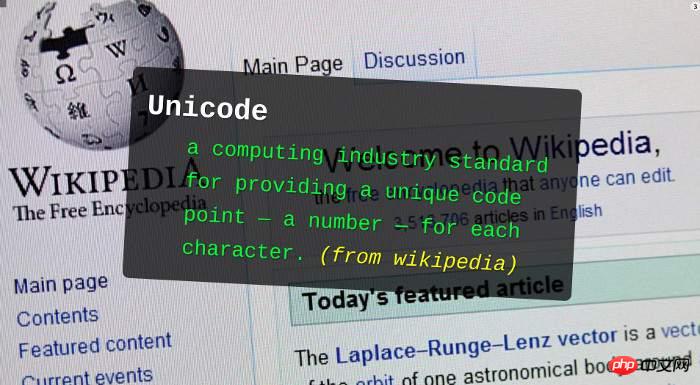
0부터 시작하여 "코드 포인트"라고 하는 각 기호에 숫자를 할당합니다. 예를 들어, 코드 포인트 0의 기호는 null입니다(모든 이진 비트가 0임을 의미).
U+0000 = null
위 수식에서 U+는 바로 뒤에 오는 16진수가 유니코드 코드 포인트임을 나타냅니다.

현재 유니코드의 최신 버전은 버전 7.0으로, 중국어, 일본어, 한국어 74,500자를 포함하여 총 109,449개의 기호가 포함되어 있습니다. 전 세계에 존재하는 기호의 3분의 2 이상이 동아시아 문자에서 유래된 것으로 추정됩니다. 예를 들어 중국어의 "good"에 대한 코드 포인트는 16진수로 597D입니다.
U+597D = 好
기호가 너무 많아서 유니코드는 한 번에 정의되지 않고 파티션으로 정의됩니다. 각 영역에는 65536(216)개의 문자를 저장할 수 있는데 이를 평면이라고 합니다. 현재 총 17개(25)개의 평면이 있습니다. 즉, 전체 유니코드 문자 집합의 크기는 이제 221입니다.
처음 65536 문자 비트를 기본 평면(약어 BMP)이라고 합니다. 코드 포인트 범위는 0~2입니다.16-1로 16진수로 작성하면 U+0000을 의미합니다. U+FFFF로. 가장 일반적인 문자는 모두 이 평면에 배치되는데, 이는 유니코드에 의해 정의되고 발표되는 첫 번째 평면입니다.
나머지 문자는 보조 평면(약어 SMP)에 배치되며 코드 포인트 범위는 U+010000부터 U+10FFFF까지입니다.

유니코드는 각 문자의 코드 포인트만 지정합니다. ? 이 코드 포인트에는 인코딩 방법이 포함됩니다.
가장 직관적인 인코딩 방법은 각 코드 포인트를 4바이트로 표현하고, 바이트 내용이 코드 포인트와 일대일로 대응하는 것입니다. 이 인코딩 방법을 UTF-32라고 합니다. 예를 들어, 코드 포인트 0은 4바이트의 0으로 표시되고, 코드 포인트 597D 앞에는 2바이트의 0이 옵니다.
U+0000 = 0x0000 0000 U+597D = 0x0000 597D

UTF-32의 장점은 변환 규칙이 간단하고 직관적이며 검색 효율성이 높다는 것입니다. 단점은 동일한 영어 텍스트가 ASCII 인코딩보다 4배 더 크다는 점입니다. 이 단점은 너무 치명적이어서 실제로 아무도 이 인코딩 방법을 사용하지 않습니다. HTML 5 표준에서는 웹 페이지를 UTF-32로 인코딩해서는 안 된다고 명확하게 규정하고 있습니다.

사람들에게 정말 필요했던 것은 공간 절약형 인코딩 방식이었고, 이것이 UTF-8의 탄생으로 이어졌습니다. UTF-8은 가변 길이 인코딩 방법으로, 문자 길이는 1바이트에서 4바이트까지입니다. 일반적으로 사용되는 문자일수록 바이트 수는 짧아집니다. 처음 128자는 1바이트로 표현되며 이는 ASCII 코드와 완전히 동일합니다.
| 编号范围 | 字节 |
| 0×0000 – 0x007F | 1 |
| 0×0080 – 0x07FF | 2 |
| 0×0800 – 0xFFFF | 3 |
| 0×010000 – 0x10FFFF | 4 |
由于UTF-8这种节省空间的特性,导致它成为互联网上最常见的网页编码。不过,它跟今天的主题关系不大,我就不深入了,具体的转码方法,可以参考我多年前写的《字符编码笔记》。
UTF-16编码介于UTF-32与UTF-8之间,同时结合了定长和变长两种编码方法的特点。
它的编码规则很简单:基本平面的字符占用2个字节,辅助平面的字符占用4个字节。也就是说,UTF-16的编码长度要么是2个字节(U+0000到U+FFFF),要么是4个字节(U+010000到U+10FFFF)。

于是就有一个问题,当我们遇到两个字节,怎么看出它本身是一个字符,还是需要跟其他两个字节放在一起解读?
说来很巧妙,我也不知道是不是故意的设计,在基本平面内,从U+D800到U+DFFF是一个空段,即这些码点不对应任何字符。因此,这个空段可以用来映射辅助平面的字符。
具体来说,辅助平面的字符位共有220个,也就是说,对应这些字符至少需要20个二进制位。UTF-16将这20位拆成两半,前10位映射在U+D800到U+DBFF(空间大小210),称为高位(H),后10位映射在U+DC00到U+DFFF(空间大小210),称为低位(L)。这意味着,一个辅助平面的字符,被拆成两个基本平面的字符表示。

所以,当我们遇到两个字节,发现它的码点在U+D800到U+DBFF之间,就可以断定,紧跟在后面的两个字节的码点,应该在U+DC00到U+DFFF之间,这四个字节必须放在一起解读。
Unicode码点转成UTF-16的时候,首先区分这是基本平面字符,还是辅助平面字符。如果是前者,直接将码点转为对应的十六进制形式,长度为两字节。
U+597D = 0x597D
如果是辅助平面字符,Unicode 3.0版给出了转码公式。
H = Math.floor((c-0x10000) / 0x400)+0xD800 L = (c - 0x10000) % 0x400 + 0xDC00

以字符 为例,它是一个辅助平面字符,码点为U+1D306,将其转为UTF-16的计算过程如下。
为例,它是一个辅助平面字符,码点为U+1D306,将其转为UTF-16的计算过程如下。
H = Math.floor((0x1D306-0x10000)/0x400)+0xD800 = 0xD834 L = (0x1D306-0x10000) % 0x400+0xDC00 = 0xDF06
所以,字符的UTF-16编码就是0xD834 DF06,长度为四个字节。


JavaScript语言采用Unicode字符集,但是只支持一种编码方法。
这种编码既不是UTF-16,也不是UTF-8,更不是UTF-32。上面那些编码方法,JavaScript都不用。
JavaScript用的是UCS-2!

怎么突然杀出一个UCS-2?这就需要讲一点历史。
互联网还没出现的年代,曾经有两个团队,不约而同想搞统一字符集。一个是1988年成立的Unicode团队,另一个是1989年成立的UCS团队。等到他们发现了对方的存在,很快就达成一致:世界上不需要两套统一字符集。
1991年10月,两个团队决定合并字符集。也就是说,从今以后只发布一套字符集,就是Unicode,并且修订此前发布的字符集,UCS的码点将与Unicode完全一致。

UCS的开发进度快于Unicode,1990年就公布了第一套编码方法UCS-2,使用2个字节表示已经有码点的字符。(那个时候只有一个平面,就是基本平面,所以2个字节就够用了。)UTF-16编码迟至1996年7月才公布,明确宣布是UCS-2的超集,即基本平面字符沿用UCS-2编码,辅助平面字符定义了4个字节的表示方法。
两者的关系简单说,就是UTF-16取代了UCS-2,或者说UCS-2整合进了UTF-16。所以,现在只有UTF-16,没有UCS-2。
那么,为什么JavaScript不选择更高级的UTF-16,而用了已经被淘汰的UCS-2呢?
答案很简单:非不想也,是不能也。因为在JavaScript语言出现的时候,还没有UTF-16编码。
1995年5月,Brendan Eich用了10天设计了JavaScript语言;10月,第一个解释引擎问世;次年11月,Netscape正式向ECMA提交语言标准(整个过程详见《JavaScript诞生记》)。对比UTF-16的发布时间(1996年7月),就会明白Netscape公司那时没有其他选择,只有UCS-2一种编码方法可用!

由于JavaScript只能处理UCS-2编码,造成所有字符在这门语言中都是2个字节,如果是4个字节的字符,会当作两个双字节的字符处理。JavaScript的字符函数都受到这一点的影响,无法返回正确结果。

还是以字符为例,它的UTF-16编码是4个字节的0xD834 DF06。问题就来了,4个字节的编码不属于UCS-2,JavaScript不认识,只会把它看作单独的两个字符U+D834和U+DF06。前面说过,这两个码点是空的,所以JavaScript会认为是两个空字符组成的字符串!

上面代码表示,JavaScript认为字符的长度是2,取到的第一个字符是空字符,取到的第一个字符的码点是0xDB34。这些结果都不正确!

解决这个问题,必须对码点做一个判断,然后手动调整。下面是正确的遍历字符串的写法。
while (++index < length) {
// ...
if (charCode >= 0xD800 && charCode <= 0xDBFF) {
output.push(character + string.charAt(++index));
} else {
output.push(character);
}
}上面代码表示,遍历字符串的时候,必须对码点做一个判断,只要落在0xD800到0xDBFF的区间,就要连同后面2个字节一起读取。
类似的问题存在于所有的JavaScript字符操作函数。
String.prototype.replace() String.prototype.substring() String.prototype.slice() ...
上面的函数都只对2字节的码点有效。要正确处理4字节的码点,就必须逐一部署自己的版本,判断一下当前字符的码点范围。

JavaScript的下一个版本ECMAScript 6(简称ES6),大幅增强了Unicode支持,基本上解决了这个问题。
(1)正确识别字符
ES6可以自动识别4字节的码点。因此,遍历字符串就简单多了。
for (let s of string ) {
// ...
}但是,为了保持兼容,length属性还是原来的行为方式。为了得到字符串的正确长度,可以用下面的方式。
Array.from(string).length
(2)码点表示法
JavaScript允许直接用码点表示Unicode字符,写法是”反斜杠+u+码点”。
'好' === '\u597D' // true
但是,这种表示法对4字节的码点无效。ES6修正了这个问题,只要将码点放在大括号内,就能正确识别。

(3)字符串处理函数
ES6新增了几个专门处理4字节码点的函数。
String.fromCodePoint():从Unicode码点返回对应字符 String.prototype.codePointAt():从字符返回对应的码点 String.prototype.at():返回字符串给定位置的字符
(4)正则表达式
ES6提供了u修饰符,对正则表达式添加4字节码点的支持。

(5)Unicode正规化
有些字符除了字母以外,还有附加符号。比如,汉语拼音的Ǒ,字母上面的声调就是附加符号。对于许多欧洲语言来说,声调符号是非常重要的。

Unicode提供了两种表示方法。一种是带附加符号的单个字符,即一个码点表示一个字符,比如Ǒ的码点是U+01D1;另一种是将附加符号单独作为一个码点,与主体字符复合显示,即两个码点表示一个字符,比如Ǒ可以写成O(U+004F) + ˇ(U+030C)。
// 方法一 '\u01D1' // 'Ǒ' // 方法二 '\u004F\u030C' // 'Ǒ'
这两种表示方法,视觉和语义都完全一样,理应作为等同情况处理。但是,JavaScript无法辨别。
'\u01D1'==='\u004F\u030C' //false
ES6提供了normalize方法,允许“Unicode正规化”,即将两种方法转为同样的序列。
'\u01D1'.normalize() === '\u004F\u030C'.normalize() // true
위 내용은 유니코드 및 JavaScript 코드 예제에 대한 자세한 소개()의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



