


비즈니스 발전으로 인해 mysql을 사용하여 인덱스를 생성하고 검색하면 데이터베이스 io에서 데이터 흐름의 병목 현상이 발생합니다. 테이블이 덤프되면 압력이 너무 커서 시간이 오래 걸리고 현재 데이터 볼륨이 기본적으로 1억 수준에 도달했습니다. mysql이 더 나은 서비스를 제공하려면 다음 단계는 하위를 고려하는 것입니다. -이를 기반으로 한 데이터베이스와 테이블; 이 경우 데이터 저장을 위해 hbase를 사용하는 것이 좋습니다. hbase가 감당할 수 있는 데이터의 양은 mysql보다 훨씬 크고 컬럼 확장도 매우 편리하기 때문입니다
mysql, sqlserver, oracle과 같은 관계형 데이터베이스에서는 다음과 같이 데이터가 행별로 저장됩니다. 그림:
그러나 hbase에서는 모든 데이터가 아래와 같이 열을 기반으로 저장됩니다.

hbase의 논리 모델은 다음과 같습니다.
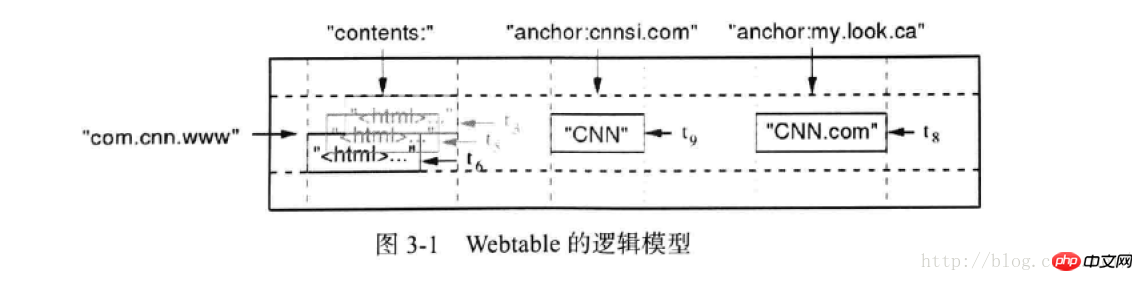
그 중 com.cnn.ww는 rowkey에 해당하며, 이는 다음과 같은 개념입니다. mysql의 기본 키
내용, 앵커: 이 둘은 컬럼 패밀리(column family) 개념에 해당하며, 물리적인 저장 측면에서는 동일한 컬럼 패밀리의 데이터가 동일한 파일
cnnsi.com에 저장된다. , mylook.ca: 해당 열 패밀리 아래의 열은 hbase에서 동적으로 추가할 수 있습니다
해당 그리드 데이터는 단위 데이터를 나타냅니다. 즉, rowkey에 해당합니다. cf: 열 아래의 특정 값
그 중 tn:은 타임스탬프를 나타냅니다. 다양한 버전의 단위 데이터
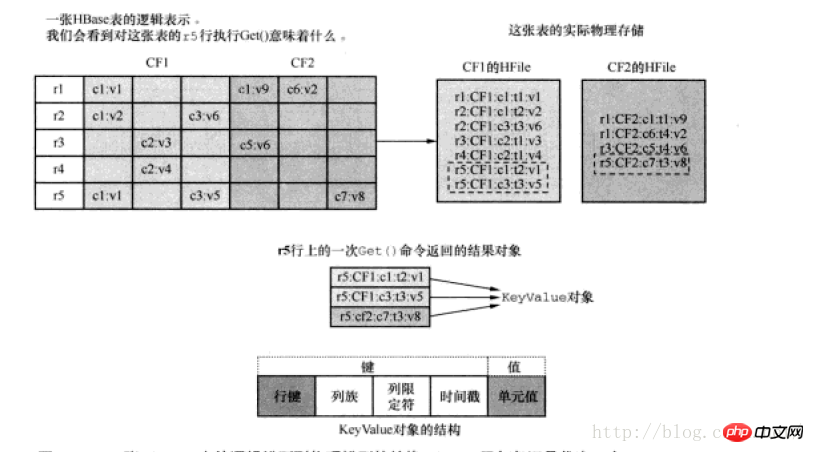
는 다음과 같은 저장 구조를 갖습니다.
CRUD는 데이터베이스의 가장 기본적이고 일반적으로 사용되는 작업입니다. 예를 들어, 테이블 생성 명령문도 있습니다. mysql은 여기에서 자세히 설명하지 않습니다. hbase 셸은
create 'table', 'columnfamily'
와 같이 table이라는 이름의 테이블을 생성하고, 열 패밀리는 columnfamily이고 기타 다른 항목은 다음과 같습니다. 블록 크기 및 버전 데이터가 기본값입니다
데이터를 읽을 때 get 'table', 'row', 'cf:column'과 같은 hbase 문을 사용하여 해당 데이터를 가져옵니다
업데이트할 때. 데이터, hbase 사용 해당 업데이트에 대한 개념은 없지만 타임스탬프에서 반영할 수 있는 새 버전이 있을 예정입니다. 사용된 문은
put 'table', 'row', 'cf: name', 'value'
는 해당 cf 컬럼 패밀리에 value의 값을 할당할 수 있습니다. name의 컬럼 이름은
입니다. 데이터 삭제의 차이점은 mysql에서 데이터를 삭제할 수 있다는 것입니다. 행을 직접 삭제하거나 특정 열만 변경하면 hbase에서 특정 열을 직접 삭제할 수 있습니다
mysql에서는 다음을 생성할 수 있습니다. 인덱스나 필터 쿼리를 지원하지만, hbase에서는 rowkey만 지원합니다. 쿼리 속도가 가장 빠릅니다
관계형 데이터베이스는 오랜 역사를 가지고 있지만, 예를 들어 mysql 데이터베이스의 경우 데이터 양이 수백 개에 달할 때 수백만 개 이상 때로는 인덱스를 기반으로 쿼리하는 경우 효과가 특별히 뚜렷하지 않을 수 있습니다. 결국에는 기본 키 기반으로만 쿼리하거나 점차적으로 하위 데이터베이스 및 하위 테이블 모델로 발전할 수 있습니다. 그러나 하위 데이터베이스와 하위 테이블은 운영, 유지 관리 및 사용에 많은 문제를 가져오므로 이때 NoSQL 데이터베이스의 기본 키가 개발되었으며, 이는 sql의 약자입니다. 데이터 양이 급격히 증가함에 따라 확장되었습니다. NoSQL의 hbase를 예로 들면 TB 및 PB 데이터와 컬럼을 지원합니다. 확장이 특히 유연합니다
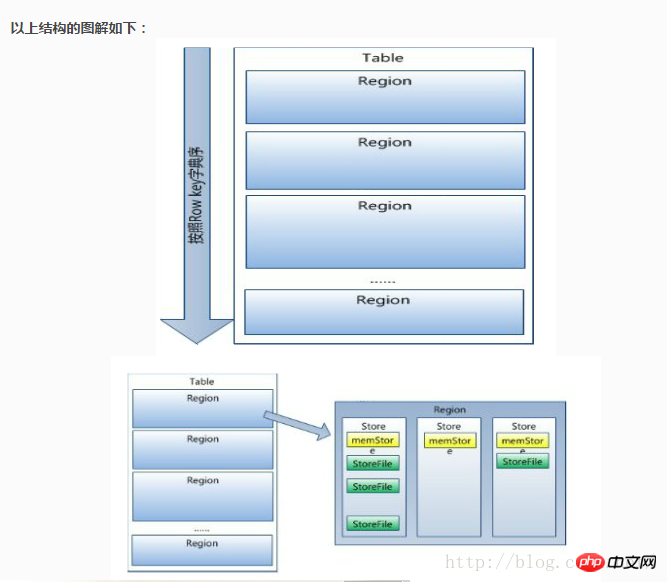


위 내용은 mysql에서 hbase로 데이터를 마이그레이션하는 데 대한 몇 가지 생각과 설계입니다. 더 많은 관련 내용을 보려면 PHP 중국어 웹사이트( m.sbmmt.com)!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



