


XML 프로그래밍은 XML 파일에 대해 거친 작업을 수행하는 것입니다.
그렇다면 XML에서 crud 작업을 수행하기 위해 왜 java나 C/C++를 사용해야 할까요?
1. 데이터 전송 시 XML을 파싱해야 함
2. XML을 구성 파일로 읽어야 함
3. 소규모 데이터베이스인 XML은 정밀한 작업이 필요함
w3C 조직에서 제작함 누구나 쉽게 XML을 파싱할 수 있도록 일련의 사양을 정의합니다(API)
1. XML 파싱은 다음과 같이 나뉩니다. 및 sax 구문 분석
dom: (Document Object Model)은 W3C 조직에서 권장하는 XML 처리 방법입니다
sax: (Simple API for XML)은 공식적인 표준은 아니지만 XML 커뮤니티에서는 사실상의 표준이며 거의 모든 XML 파서가 이를 지원합니다.
SAX 파싱에서는 이를 사용합니다. 이벤트 기반 모델 에지 읽는 동안 구문 분석: 위에서 아래로 한 줄씩 구문 분석하고 특정 요소까지 구문 분석하고 해당 구문 분석 메서드를 호출합니다.
DOM은 XML 계층 구조에 따라 메모리에 트리 구조를 할당하고 XML 태그, 속성, 텍스트 및 기타 요소를 트리 노드 객체로 캡슐화합니다.
다양한 회사와 조직에서 DOM과 SAX 모두에 대한 파서를 제공합니다.
Sun의 JAXP
dom4j가 구성한 Dom4j(대부분 최대 절전 모드와 같이 일반적으로 사용됨)
JDom으로 구성된 jdom
JASP는 J2SE의 일부이며 DOM 및 SAX 파서가 제공됩니다. DOM 및 SAX의 경우.
JAXP 개발 패키지는 javax.xml, org.w3c.dom, org.xml.sax 패키지와 해당 하위 패키지로 구성된 J2SE의 일부입니다.
<bookstore>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book></bookstore>1.dom은 xml 파일을 트리로 간주하여 메모리에 로드합니다
2.dom 특히 crud 작업에 적합3.dom은 더 큰 xml 파일을 작업하는 데 적합하지 않습니다(메모리 점유).
4.dom은 xml 파일의 모든 요소, 속성 및 텍스트를 해당 항목에 매핑합니다. 노드 개체 .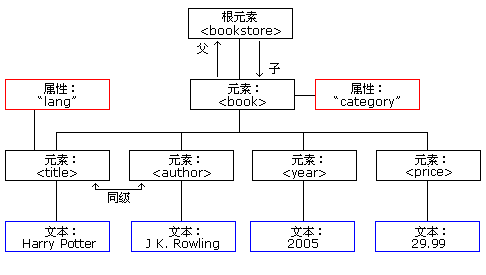
1. DocumentBuilderFactory.newInstance() 메서드를 호출하여 DOM 파서를 생성하는 팩토리를 가져옵니다
2. 팩토리 객체의 newDocumentBuilder 메소드를 호출하여 DOM 파서 객체
를 얻습니다. 3. DOM 파서 객체의 parse() 메소드를 호출하여 XML 문서를 구문 분석하고 전체 XML 문서를 나타내는 Document 객체를 얻습니다. DOM 기능을 사용하여 작동할 수 있습니다.
XML 문서는 다음과 같습니다.
<?xml version="1.0" encoding="utf-8"?><班级>
<学生 地址="香港">
<名字>周小星</名字>
<年龄>23</年龄>
<介绍>学习刻苦</介绍>
</学生>
<学生 地址="澳门">
<名字>林晓</名字>
<年龄>25</年龄>
<介绍>是一个好学生</介绍>
</学生> </班级>// 1.创建一个DocumentBuilderFactoryDocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2.通过工厂实例得到DocumentBuilder对象DocumentBuilder builder = factory.newDocumentBuilder();
// 3.指定要解析的xml文件,返回document对象Document document = builder.parse(new File("src/myClass.xml"));
read(document);/**
* 显示所有学生的所有信息
* @param document
*/public static void read(Document document){ // 通过学生这个标签名字得到NodeList
NodeList nodeList = document.getElementsByTagName("学生");
for(int i=0;i<nodeList.getLength();i++){ // 因为Element是Node的子接口,所有这里可以转换成Element
// 从而可以使用更多的方法
Element student = (Element)nodeList.item(i); // 获取属性
String address = student.getAttribute("地址");
System.out.println(address); // 得到学生的所有子节点,并循环输出
NodeList childList = student.getChildNodes(); for(int j=0;j<childList.getLength();j++){
Node node = childList.item(j); if(node.getNodeType() == Node.ELEMENT_NODE)
System.out.println(node.getNodeName()+":"+node.getTextContent());
}
System.out.println("-------------");
} // 这样一层一层向下查询也可以
//Element name = (Element)student.getElementsByTagName("名字").item(0);
//System.out.println(name.getTextContent()); }read(Document document)
XML 문서 업데이트
<🎜. >DOM을 사용하여 XML 문서를 업데이트하는 경우 Transformer 클래스를 사용하여 파일에 변경 사항을 써야 합니다. 그렇지 않으면 메모리의 XML 문서 객체만 변경됩니다.

javax.xml.transform.dom.DOMSource 클래스
javax.xml.transform.stream.StreamResult 개체를 사용하여 데이터의 대상을 나타냅니다.【1】요소 추가
/**
* 添加学生
*
* @param document
* @throws Exception
*/public static void add(Document document) throws Exception { // 创建一个新的学生节点
Element newStudent = document.createElement("学生"); // 给新的学生添加地址属性
newStudent.setAttribute("地址", "旧金山"); // 创建学生的子节点
Element newStudent_name = document.createElement("名字");
newStudent_name.setTextContent("小明");
Element newStudent_age = document.createElement("年龄");
newStudent_age.setTextContent("25");
Element newStudent_intro = document.createElement("介绍");
newStudent_intro.setTextContent("这是一个好孩子"); // 将子节点添加到学生节点上
newStudent.appendChild(newStudent_name);
newStudent.appendChild(newStudent_age);
newStudent.appendChild(newStudent_intro); // 把新的学生节点添加到根节点下
document.getDocumentElement().appendChild(newStudent); // 更新XML文档
// 得到TransformerFactory
TransformerFactory tff = TransformerFactory.newInstance(); // 通过TransformerFactory得到一个转换器
Transformer tf = tff.newTransformer(); // 更新当前的XML文件
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【2】删除元素
同样的,我们也可以删除一个学生节点,如下:
/**
* 删除第一个学生节点
*
* @param document
*/public static void delete(Document document) throws Exception { // 首先找到这个学生,这里可以不用转为Element
Node student = document.getElementsByTagName("学生").item(0); // 通过它的父节点来删除
student.getParentNode().removeChild(student); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【3】更改元素的值
比如,我们也可以将第一个学生的名字改为松江,如下:
/**
* 把第一个学生的元素名字改为宋江
*
* @param document
*/public static void update_name(Document document) throws Exception{
Element student = (Element) document.getElementsByTagName("学生").item(0);
Element name = (Element) student.getElementsByTagName("名字").item(0);
name.setTextContent("宋江"); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【4】更改或删除元素的属性
/**
* 删除第一个学生节点的属性
*
* @param document
*/public static void delete_attribute(Document document) throws Exception { // 首先找到这个学生
Element student = (Element) document.getElementsByTagName("学生").item(0); // 删除student的地址属性
student.removeAttribute("地址"); // 更新属性
// student.setAttribute("地址", "新地址");
// 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}上述列举了几个更新元素(节点)的例子,更一般的需求是这样的:将名字是周小星的同学的年龄改为30,这时候我们需要去遍历XML文档,找到对应的节点,再进行修改。
另外,所有关于更新的方法中都用到了TransformerFactory来进行实际的更新,所以,我们可以把这三句话写成一个函数,从而避免代码冗余,如下:
public static void update(Document document, String path) throws Exception {
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File(path)));
}XML编程,就是对XML文件进行crud操作。
那么为什么要用java或者C/C++对XML进行crud操作呢?
1.XML作为数据传递需要解析
2.XML作为配置文件需要读取
3.XML作为小型数据库,需要进行crud操作
w3C组织为了大家解析XML方便,定义了一套规范(API)
1.XML解析分为:dom解析和sax解析
dom:(Document Object Model,即文档对象模型),是W3C组织推荐的处理XML的一种方式
sax:(Simple API for XML),不是官方标准,但它是XML社区事实上的标准,几乎所有的XML解析器都支持它
SAX解析采用事件驱动模型边读边解析:从上到下一行一行解析,解析到某一元素,调用相应的解析方法。
DOM根据XML层级结构在内存中分配一个树形结构,把XML的标签,属性和文本等元素都封装成树的节点对象。
不同的公司和组织提供了针对DOM和SAX两种方式的解析器:
Sun的JAXP
Dom4j组织的dom4j(最常用,例如hibernate)
JDom组织的jdom
其中的JASP是J2SE的一部分,它分别针对DOM和SAX提供了DOM和SAX解析器。
在这里也主要介绍三种解析:dom、sax和dom4j
Sun公司提供了Java API for XML Parsing(JAXP)接口来使用SAX和DOM,通过JAXP,我们可以使用任何与JAXP兼容的XML解析器。
JAXP开发包是J2SE的一部分,它由javax.xml、org.w3c.dom、org.xml.sax包及其子包组成
在javax.xml.parsers包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的DOM或SAX的解析器对象。
首先说明JAXP解析XML的DOM对象的原理,XML DOM把XML文档视为一颗节点树(node-tree),树中的所有节点彼此之间都有关系。可通过这棵树访问所有的节点。可以修改或者删除它们的内容,也可以创建新的元素。
比如,现在的XML文档如下(该例子来自w3cschool在线教程):
<bookstore>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book></bookstore>这棵树从根节点开始,在树的最低层级向文本节点长出枝条:
【要知道的几个知识点】:
1.dom会把xml文件看做一棵树,并加载到内存
2.dom特别适合做crud操作
3.dom不太适合去操作比较大的xml文件(占用内存)
4.dom会把xml文件中每一个元素、属性、文本都映射成对应的Node对象。
1.调用DocumentBuilderFactory.newInstance()方法得到创建DOM解析器的工厂
2.调用工厂对象的newDocumentBuilder方法得到DOM解析器对象
3.调用DOM解析器对象的parse()方法解析XML文档,得到代表整个文档的Document对象,进行可以利用DOM特性对整个XML文档进行操作了。
XML文档如下:
<?xml version="1.0" encoding="utf-8"?><班级>
<学生 地址="香港">
<名字>周小星</名字>
<年龄>23</年龄>
<介绍>学习刻苦</介绍>
</学生>
<学生 地址="澳门">
<名字>林晓</名字>
<年龄>25</年龄>
<介绍>是一个好学生</介绍>
</学生> </班级>首先使用2.2中介绍了三个步骤得到代表整个文档的document对象,并调用我们所写的read(Document document)方法,如下:
// 1.创建一个DocumentBuilderFactoryDocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2.通过工厂实例得到DocumentBuilder对象DocumentBuilder builder = factory.newDocumentBuilder();
// 3.指定要解析的xml文件,返回document对象Document document = builder.parse(new File("src/myClass.xml"));
read(document);其中的read方法是这么写的:
/**
* 显示所有学生的所有信息
* @param document
*/public static void read(Document document){ // 通过学生这个标签名字得到NodeList
NodeList nodeList = document.getElementsByTagName("学生");
for(int i=0;i<nodeList.getLength();i++){ // 因为Element是Node的子接口,所有这里可以转换成Element
// 从而可以使用更多的方法
Element student = (Element)nodeList.item(i); // 获取属性
String address = student.getAttribute("地址");
System.out.println(address); // 得到学生的所有子节点,并循环输出
NodeList childList = student.getChildNodes(); for(int j=0;j<childList.getLength();j++){
Node node = childList.item(j); if(node.getNodeType() == Node.ELEMENT_NODE)
System.out.println(node.getNodeName()+":"+node.getTextContent());
}
System.out.println("-------------");
} // 这样一层一层向下查询也可以
//Element name = (Element)student.getElementsByTagName("名字").item(0);
//System.out.println(name.getTextContent()); }最后的XML - XML 구문 분석을 위한 DOM如下所示:
利用DOM更新XML文档一定要使用Transformer类将更改写入文件,否则只是更改了在内存中的XML文档对象。
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写回到一个XML文件中
Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
javax.xml.transform.dom.DOMSource类来关联要转换的document对象
用javax.xml.transform.stream.StreamResult对象来表示数据的目的地
Transformer对象通过TransformerFactory获得
【1】添加元素
我们可以向上述XML中添加一个学生子节点,如下:
/**
* 添加学生
*
* @param document
* @throws Exception
*/public static void add(Document document) throws Exception { // 创建一个新的学生节点
Element newStudent = document.createElement("学生"); // 给新的学生添加地址属性
newStudent.setAttribute("地址", "旧金山"); // 创建学生的子节点
Element newStudent_name = document.createElement("名字");
newStudent_name.setTextContent("小明");
Element newStudent_age = document.createElement("年龄");
newStudent_age.setTextContent("25");
Element newStudent_intro = document.createElement("介绍");
newStudent_intro.setTextContent("这是一个好孩子"); // 将子节点添加到学生节点上
newStudent.appendChild(newStudent_name);
newStudent.appendChild(newStudent_age);
newStudent.appendChild(newStudent_intro); // 把新的学生节点添加到根节点下
document.getDocumentElement().appendChild(newStudent); // 更新XML文档
// 得到TransformerFactory
TransformerFactory tff = TransformerFactory.newInstance(); // 通过TransformerFactory得到一个转换器
Transformer tf = tff.newTransformer(); // 更新当前的XML文件
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【2】删除元素
同样的,我们也可以删除一个学生节点,如下:
/**
* 删除第一个学生节点
*
* @param document
*/public static void delete(Document document) throws Exception { // 首先找到这个学生,这里可以不用转为Element
Node student = document.getElementsByTagName("学生").item(0); // 通过它的父节点来删除
student.getParentNode().removeChild(student); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【3】更改元素的值
比如,我们也可以将第一个学生的名字改为松江,如下:
/**
* 把第一个学生的元素名字改为宋江
*
* @param document
*/public static void update_name(Document document) throws Exception{
Element student = (Element) document.getElementsByTagName("学生").item(0);
Element name = (Element) student.getElementsByTagName("名字").item(0);
name.setTextContent("宋江"); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【4】更改或删除元素的属性
/**
* 删除第一个学生节点的属性
*
* @param document
*/public static void delete_attribute(Document document) throws Exception { // 首先找到这个学生
Element student = (Element) document.getElementsByTagName("学生").item(0); // 删除student的地址属性
student.removeAttribute("地址"); // 更新属性
// student.setAttribute("地址", "新地址");
// 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}上述列举了几个更新元素(节点)的例子,更一般的需求是这样的:将名字是周小星的同学的年龄改为30,这时候我们需要去遍历XML文档,找到对应的节点,再进行修改。
另外,所有关于更新的方法中都用到了TransformerFactory来进行实际的更新,所以,我们可以把这三句话写成一个函数,从而避免代码冗余,如下:
public static void update(Document document, String path) throws Exception {
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File(path)));
} 以上就是XML—XML解析之DOM的内容,更多相关内容请关注PHP中文网(m.sbmmt.com)!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



