

스레드 풀 생성은 이전 기사에서 분석되었습니다. 스레드 풀에는 유연한 사용자 정의를 지원하기 위해 사전 설정된 템플릿과 다양한 매개 변수가 모두 있는 것으로 이해됩니다.
이 글에서는 스레드 풀의 라이프사이클에 초점을 맞춰 스레드 풀이 작업을 실행하는 과정을 분석해 보겠습니다.
먼저 스레드 풀 코드 전체에서 두 매개변수를 이해하세요.
runState: 스레드 풀 실행 상태
WorkerCount: 작업자 스레드 수
스레드 풀은 32비트 int를 사용하여 runState와 WorkerCount를 동시에 저장하는데, 그 중 상위 3비트가 runState이고 나머지 29비트가 WorkerCount입니다. RunStateOf 및 WorkerCountOf는 runState 및 WorkerCount를 얻기 위해 코드에서 반복적으로 사용됩니다.
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); private static final int COUNT_BITS = Integer.SIZE - 3; private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 线程池状态 private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS;
// ctl操作
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }RUNNING: 새 작업 수신 가능, 대기 대기열에 있는 작업 실행 가능
SHUTDOWN: 새 작업 수신 불가, 대기 대기열에 있는 작업 실행 가능
STOP: 새 작업을 받을 수 없고, 대기 중인 대기열에 있는 작업을 실행할 수 없으며, 실행 중인 모든 작업을 종료하려고 합니다.
TIDYING: 모든 작업이 종료되었습니다. 실행이 종료되었습니다()
TERMINATED : 종료됨() 실행 완료
스레드 풀 상태는 기본적으로 RUNNING부터 시작하여 TERMINATED 상태로 종료됩니다. 중간에 각 상태를 거칠 필요는 없으나, 상태를 롤링할 수는 없습니다. 뒤쪽에. 상태 변경이 가능한 경로와 조건은 다음과 같습니다. 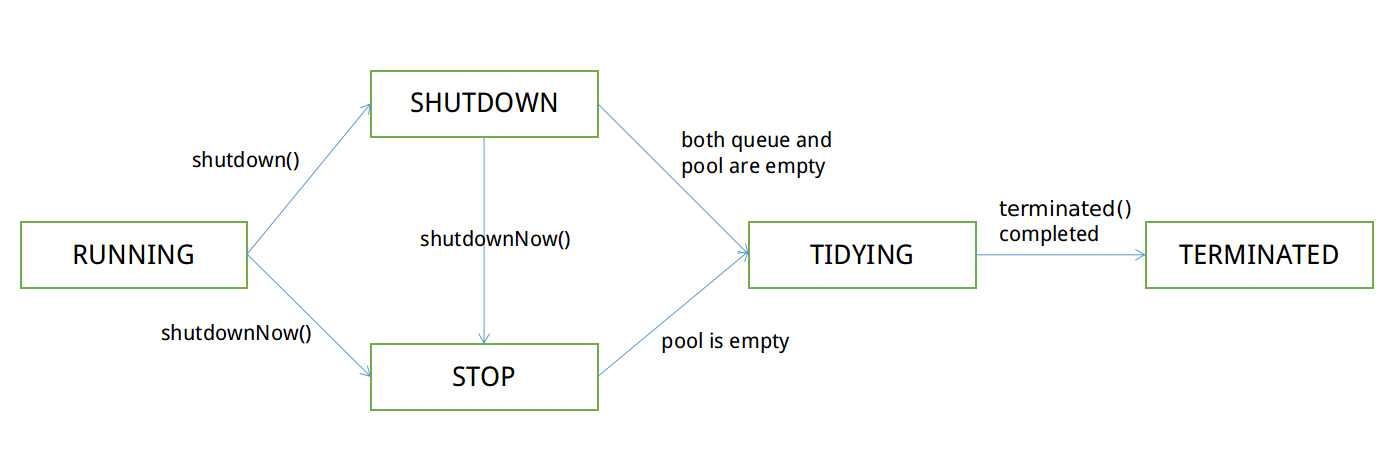
그림 1 스레드 풀 상태 변경 경로
스레드 풀은 Worker 클래스에 의한 작업 실행을 담당합니다. Worker는 Java 동시성 프레임워크의 핵심인 AQS로 이어지는 AbstractQueuedSynchronizer를 상속합니다.
AbstractQueuedSynchronizer,简称AQS,是Java并发包里一系列同步工具的基础实现,原理是根据状态位来控制线程的入队阻塞、出队唤醒来处理同步。
AQS에서는 Worker가 Thread를 래핑하고 작업을 수행한다는 점만 알면 됩니다.
execute를 호출하면 스레드 풀의 상황에 따라 Worker가 생성됩니다. 다음 네 가지 상황으로 요약할 수 있습니다. 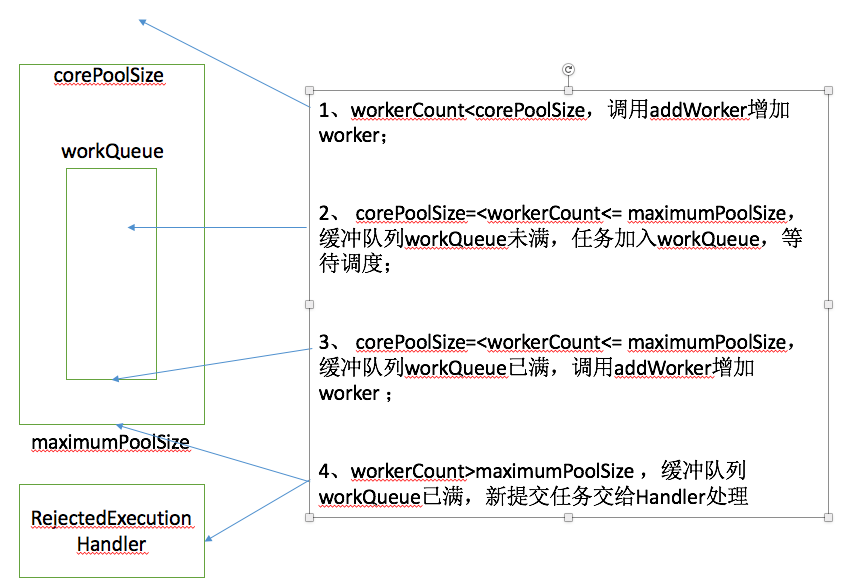
그림 2 스레드의 Worker pool 네 가지 가능성
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//1
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//2
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
//3
reject(command);
else if (workerCountOf(recheck) == 0)
//4
addWorker(null, false);
}
//5
else if (!addWorker(command, false))
//6
reject(command);
} 마크 1은 첫 번째 상황에 해당합니다. addWorker가 코어에서 전달되고, core=true는 corePoolSize이고, core=false는 maximumPoolSize인지 확인해야 합니다. 허용된 최대값을 초과했습니다.
마크 2는 스레드 풀이 실행 중인지 확인하고 작업을 대기 대기열에 추가하는 두 번째 상황에 해당합니다. Mark 3은 스레드 풀 상태를 다시 확인합니다. 스레드 풀이 갑자기 실행되지 않는 상태가 되면 방금 대기 큐에 추가한 작업을 삭제하고 처리를 위해 RejectedExecutionHandler에 넘겨줍니다. Mark 4는 작업자가 없음을 확인하고 먼저 빈 작업이 있는 작업자를 추가합니다.
Mark 5는 세 번째 상황에 해당합니다. 대기 대기열에 더 이상 작업을 추가할 수 없습니다.
Mark 6은 네 번째 상황에 해당합니다. addWorker의 핵심이 false로 전달되고 반환 호출이 실패합니다. 즉, WorkerCount가 maximumPoolSize를 초과하여 처리를 위해 RejectedExecutionHandler로 넘겨졌습니다.
private boolean addWorker(Runnable firstTask, boolean core) {
//1
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
//2
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}1로 표시된 첫 번째 코드 조각은 작업자 개수에 1을 추가하는 간단한 목적을 가지고 있습니다. 코드를 작성하는 데 시간이 오래 걸리는 이유는 스레드 풀의 상태가 지속적으로 변경되고 동시성 환경에서는 변수의 동기화가 보장되어야 하기 때문입니다. 외부 루프는 스레드 풀 상태를 확인하고, 작업이 비어 있지 않으며, 대기열이 비어 있지 않은지 확인합니다. 내부 루프는 CAS 메커니즘을 사용하여 WorkerCount가 올바르게 증가하는지 확인합니다. CAS를 모르는 경우 CAS가 작업자 수의 후속 증가 또는 감소에 사용되는 비차단 동기화 메커니즘에 대해 알아볼 수 있습니다.
2로 표시된 두 번째 코드는 비교적 간단합니다. 새 Worker 개체를 만들고 Worker를 작업자(Set 컬렉션)에 추가합니다. 추가가 성공적으로 완료되면 작업자에서 스레드를 시작합니다. 마지막으로 스레드가 성공적으로 시작되었는지 판단합니다. 성공하지 못한 경우 addWorkerFailed가 직접 호출됩니다.
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (w != null)
workers.remove(w);
decrementWorkerCount();
tryTerminate();
} finally {
mainLock.unlock();
}
}addWorkerFailed는 이미 증가한 WorkerCount를 줄이고 tryTerminate를 호출하여 스레드 풀을 종료합니다.
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}Worker는 ThreadFactory를 이용해 생성자에서 Thread를 생성하고, run 메소드에서 runWorker를 호출하는데, 그 곳이 작업이 이루어지는 곳인 것 같습니다. 실제로 실행됨.
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//1
while (task != null || (task = getTask()) != null) {
w.lock();
//2
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//3
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
//4
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false; //5
} finally {
//6
processWorkerExit(w, completedAbruptly);
}
} Mark 1은 루프에 들어가 null이 반환될 때까지 getTask에서 실행할 작업을 가져옵니다. 여기에서 스레드 재사용 효과가 달성되어 스레드가 여러 작업을 처리할 수 있습니다.
마크 2는 스레드 풀이 STOP 상태에서 중단되고 비 STOP 상태에서 중단되지 않음을 보장하는 비교적 복잡한 판단입니다. Java의 인터럽트 메커니즘을 이해하지 못한다면 Java 스레드를 올바르게 종료하는 방법에 대한 이 기사를 읽어보세요.
Mark 3에서는 run 메소드를 호출하여 실제로 작업을 실행합니다. beforeExecute와 afterExecute라는 두 가지 메서드가 실행 전후에 제공되며, 이는 하위 클래스에 의해 구현됩니다.
마크 4의 CompleteTasks는 작업자가 실행한 작업 수를 계산하고 최종적으로 CompletedTaskCount 변수에 누적되어 일부 통계 정보를 반환할 수 있습니다.
CompletedAbruptly 5로 표시된 변수는 작업자가 비정상적으로 종료되었는지 여부를 나타냅니다. 여기서 실행은 후속 메서드에 이 변수가 필요하다는 의미입니다.
Mark 6은 processWorkerExit를 종료하도록 호출하며 이는 나중에 분석됩니다.
다음으로 대기 대기열에서 작업을 가져오는 작업자의 getTask 메서드를 살펴보겠습니다.
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
//1
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
//2
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
//3
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}标记1检查线程池的状态,这里就体现出SHUTDOWN和STOP的区别。如果线程池是SHUTDOWN状态,还会先处理完等待队列的任务;如果是STOP状态,就不再处理等待队列里的任务了。
标记2先看allowCoreThreadTimeOut这个变量,false时worker空闲,也不会结束;true时,如果worker空闲超过keepAliveTime,就会结束。接着是一个很复杂的判断,好难转成文字描述,自己看吧。注意一下wc>maximumPoolSize,出现这种可能是在运行中调用setMaximumPoolSize,还有wc>1,在等待队列非空时,至少保留一个worker。
标记3是从等待队列取任务的逻辑,根据timed分为等待keepAliveTime或者阻塞直到有任务。
最后来看结束worker需要执行的操作:
private void processWorkerExit(Worker w, boolean completedAbruptly) {
//1
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
//2
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
//3
tryTerminate();
int c = ctl.get();
//4
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}正常情况下,在getTask里就会将workerCount减一。标记1处用变量completedAbruptly判断worker是否异常退出,如果是,需要补充对workerCount的减一。
标记2将worker处理任务的数量累加到总数,并且在集合workers中去除。
标记3尝试终止线程池,后续会研究。
标记4处理线程池还是RUNNING或SHUTDOWN状态时,如果worker是异常结束,那么会直接addWorker。如果allowCoreThreadTimeOut=true,并且等待队列有任务,至少保留一个worker;如果allowCoreThreadTimeOut=false,workerCount不少于corePoolSize。
总结一下worker:线程池启动后,worker在池内创建,包装了提交的Runnable任务并执行,执行完就等待下一个任务,不再需要时就结束。
线程池的关闭不是一关了事,worker在池里处于不同状态,必须安排好worker的”后事”,才能真正释放线程池。ThreadPoolExecutor提供两种方法关闭线程池:
shutdown:不能再提交任务,已经提交的任务可继续运行;
shutdownNow:不能再提交任务,已经提交但未执行的任务不能运行,在运行的任务可继续运行,但会被中断,返回已经提交但未执行的任务。
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess(); //1 安全策略机制
advanceRunState(SHUTDOWN); //2
interruptIdleWorkers(); //3
onShutdown(); //4 空方法,子类实现
} finally {
mainLock.unlock();
}
tryTerminate(); //5
}shutdown将线程池切换到SHUTDOWN状态,并调用interruptIdleWorkers请求中断所有空闲的worker,最后调用tryTerminate尝试结束线程池。
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP);
interruptWorkers();
tasks = drainQueue(); //1
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}shutdownNow和shutdown类似,将线程池切换为STOP状态,中断目标是所有worker。drainQueue会将等待队列里未执行的任务返回。
interruptIdleWorkers和interruptWorkers实现原理都是遍历workers集合,中断条件符合的worker。
上面的代码多次出现调用tryTerminate,这是一个尝试将线程池切换到TERMINATED状态的方法。
final void tryTerminate() {
for (;;) {
int c = ctl.get();
//1
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
//2
if (workerCountOf(c) != 0) { // Eligible to terminate
interruptIdleWorkers(ONLY_ONE);
return;
}
//3
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
terminated();
} finally {
ctl.set(ctlOf(TERMINATED, 0));
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
// else retry on failed CAS
}
}标记1检查线程池状态,下面几种情况,后续操作都没有必要,直接return。
RUNNING(还在运行,不能停)
TIDYING或TERMINATED(已经没有在运行的worker)
SHUTDOWN并且等待队列非空(执行完才能停)
标记2在worker非空的情况下又调用了interruptIdleWorkers,你可能疑惑在shutdown时已经调用过了,为什么又调用,而且每次只中断一个空闲worker?你需要知道,shutdown时worker可能在执行中,执行完阻塞在队列的take,不知道要结束,所有要补充调用interruptIdleWorkers。每次只中断一个是因为processWorkerExit时,还会执行tryTerminate,自动中断下一个空闲的worker。
标记3是最终的状态切换。线程池会先进入TIDYING状态,再进入TERMINATED状态,中间提供了terminated这个空方法供子类实现。
调用关闭线程池方法后,需要等待线程池切换到TERMINATED状态。awaitTermination检查限定时间内线程池是否进入TERMINATED状态,代码如下:
public boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (;;) {
if (runStateAtLeast(ctl.get(), TERMINATED))
return true;
if (nanos <= 0)
return false;
nanos = termination.awaitNanos(nanos);
}
} finally {
mainLock.unlock();
}
} 以上就是Java 线程池执行原理分析 的内容,更多相关内容请关注PHP中文网(m.sbmmt.com)!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



