

주요 가비지 수집 알고리즘은 표시-지우기, 복사 및 표시-구성입니다.
1. 마크 스윕 알고리즘
재활용할 개체를 표시합니다.
알고리즘 단점: 효율성 문제, 표시 및 지우기 프로세스가 매우 비효율적입니다. 공간 문제, 수집 후 많은 수의 메모리 조각이 생성되므로 대형 개체 할당에 도움이 되지 않습니다.
2. 복사 알고리즘
복사 알고리즘은 사용 가능한 메모리를 동일한 크기의 블록 A와 B로 나눕니다. 한 번에 하나만 사용됩니다. A의 메모리가 사용됩니다. 그 후, 살아남은 객체를 B에 복사하고 A의 메모리를 지웁니다. 이렇게 하면 살아남은 객체만 표시하면 되므로 표시 효율성이 향상될 뿐만 아니라 메모리 조각화 문제도 방지됩니다. 사용 가능한 메모리를 원래 크기의 절반으로 줄이는 비용.
3. 마크 대조 알고리즘
구세대에서는 개체 생존율이 높고 복사 알고리즘의 효율성이 매우 낮습니다. mark-compact 알고리즘에서는 모든 살아있는 객체를 표시하여 한쪽 끝으로 이동한 다음 경계 외부의 메모리를 직접 정리합니다.
도달성 분석 과정에서 GC Roots와 연관된 객체를 정확하게 찾아내기 위해서는 전체 실행 엔진이 정지되어 있는 것처럼 보여야 합니다. 특정 시점은 실행 중인 모든 스레드가 일시 중지되고 개체의 참조 관계가 계속 변경될 수 없음을 의미합니다.
GC Roots를 빠르게 열거하는 방법은 무엇입니까?
GC 루트는 주로 전역 참조(상수 또는 클래스 정적 속성) 및 실행 컨텍스트(로컬 변수 테이블의 참조)에 있습니다. 검색할 경우 메서드 영역만 수백 메가바이트에 이릅니다. 매우 비효율적일 것입니다.
HotSpot에서는 OopMap이라는 데이터 구조 집합을 사용하여 구현됩니다. 클래스 로딩이 완료되면 HotSpot은 객체의 어떤 오프셋에 어떤 유형의 데이터가 있는지 계산하고 이를 OopMap에 저장합니다. JIT를 통해 컴파일된 로컬 코드는 스택과 레지스터에서 참조되는 위치도 기록합니다. GC가 발생하면 OopMap 데이터를 스캔하여 살아남은 개체를 빠르게 식별할 수 있습니다.
GC를 안전하게 하는 방법은?
스레드가 실행 중일 때 안전 지점에 도달한 경우에만 GC를 위해 중지할 수 있습니다.
HotSpot은 OopMap 데이터 구조를 기반으로 GC Roots의 순회를 빠르게 완료할 수 있습니다. 그러나 HotSpot은 각 명령어에 대해 해당 OopMap을 생성하지 않으며 이 정보를 Safe Point에만 기록합니다.
그래서 Safe Point의 선택은 매우 중요합니다. 너무 적으면 GC가 너무 오래 기다리게 되어 런타임 성능 문제가 발생할 수 있습니다. 대부분의 명령어의 실행 시간은 매우 짧으며, 메서드 호출, 루프 점프, 예외 점프 등 실행 시간이 긴 일부 명령어는 일반적으로 안전 지점으로 선택됩니다.
Safe Point에 대한 자세한 내용은 JVM의 Stop The World, Safe Point, Dark Underground World 기사를 확인하세요.
GC 발생 시 모든 스레드를 중지하는 방법 가장 가까운 안전 지점과 일시 중지?
GC가 발생하면 스레드가 직접 중단되지 않고 단순히 인터럽트 플래그가 설정됩니다. 각 스레드가 Safe Point로 실행되면 인터럽트 플래그가 다음과 같은 경우 적극적으로 폴링됩니다. 사실, 자체적으로 중단됩니다.
여기서는 문제가 무시됩니다. GC가 발생하면 실행 중인 스레드가 Safe Point로 실행되어 정지될 수 있으며 이때 Sleep 또는 Blocked 상태의 스레드는 JVM의 인터럽트 요청에 응답할 수 없습니다. 일시 중단하려면 안전 지점으로 이동하세요. 이 경우 안전 영역을 사용하여 문제를 해결할 수 있습니다.
안전한 영역은 코드 조각에서 객체의 참조 관계가 변경되지 않음을 의미하며 이 영역의 어느 곳에서나 GC를 시작하는 것이 안전합니다.
1. 스레드가 안전 지역 코드에 도달하면 먼저 안전 지역에 진입한 것으로 표시됩니다. 이 기간 동안 GC가 발생하면 JVM은 안전 지역으로 표시된 스레드를 무시합니다. >
2. 스레드가 안전 영역을 벗어나려고 할 때 JVM이 GC를 완료했는지 확인합니다. 완료되면 스레드는 신호를 받을 때까지 기다려야 합니다. 안전지역을 안전하게 벗어날 수 있다는 것
Java Virtual Machine 사양에는 가비지 컬렉터의 구현 방법이 명시되어 있지 않습니다. 사용자는 시스템 특성에 따라 각 영역에서 사용되는 컬렉터를 조합할 수 있습니다. 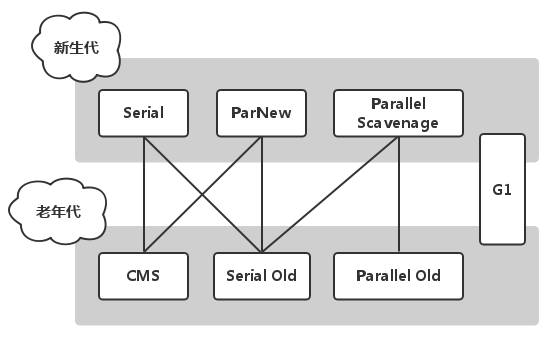
위 사진은 서로 다른 세대의 7명의 컬렉터를 보여주고 있는데, 둘 사이에 연결점이 있다면 조합해서 사용할 수 있다는 의미입니다.
1. 직렬 수집기(serial GC)
Serial은 단일 스레드를 사용하고 복사 알고리즘을 기반으로 새로운 세대에서 작동하는 수집기입니다. collection 에서는 다른 모든 작업자 스레드를 일시 중단해야 합니다. 단일 CPU 환경의 경우 Serial은 스레드 상호 작용 오버헤드가 없기 때문에 가비지 수집을 매우 효율적으로 수행할 수 있습니다. 이는 클라이언트 모드의 새로운 세대에 대한 기본 수집기입니다.
2. ParNew 컬렉터(병렬 GC)
ParNew는 실제로 가비지 수집을 위해 다중 스레드를 사용하는 것 외에도 멀티 스레드 버전입니다. 동작은 Same as Serial과 동일합니다.
3. Parallel Scavenge Collector(병렬 재활용 GC)
Parallel Scavenge는 멀티 스레드 복사 알고리즘을 사용하여 차세대에 중점을 둔 컬렉터입니다. on 요점은 종종 "처리량 우선" 수집기라고도 하는 제어 가능한 처리량을 달성하는 것입니다.
처리량 = 사용자 코드 실행 시간 / (사용자 코드 실행 시간 + 가비지 수집 시간)
Parallel Scavenge는 처리량의 정확한 제어를 위해 두 가지 매개 변수를 제공합니다.
1. -XX : MaxGCPauseMillis는 가비지 수집의 최대 일시 중지 시간을 설정합니다
2. -XX: GCTimeRatio는 처리량 크기를 설정합니다
4. Serial Old Collector(직렬 GC)
Serial Old는 단일 스레드 마크 대조 알고리즘을 사용하고 Old Generation에서 작동하는 Collector입니다. Client 모드에서 Old Generation의 기본 Collector입니다.
5. Parallel Old Collector(Parallel GC)
Parallel Old는 mark-collation 알고리즘 기반의 멀티스레딩을 사용하는 컬렉터로 Old Generation에서 작동합니다. 처리량이 중요하고 CPU 리소스가 민감한 상황에서는 Parallel Scavenge와 Parallel Old의 수집기 조합에 우선 순위가 부여될 수 있습니다.
6. CMS Collector(Concurrent GC)
CMS(Concurrent Mark Sweep)는 가장 짧은 재활용 휴지 시간을 목표로 하는 Collector이며 Old Generation에서 작동합니다. 전체 프로세스는 "mark-clear" 알고리즘을 기반으로 구현됩니다.
1. 초기 마킹 : 이 프로세스는 다음 GC에 해당하는 개체만 표시합니다. 루트는 직접 연결될 수 있지만 여전히
2. 동시 표시: GC 루트 추적 프로세스는 사용자 스레드에서 작동할 수 있습니다.
3. 비고: 동시 마킹 중 사용자 프로그램이 계속 실행되어 변경된 레코드 부분을 수정하는 데 사용됩니다. 이 프로세스는 모든 스레드를 일시 중지하지만 일시 중지 시간은 다음과 같습니다. 동시 마킹보다 시간이 훨씬 짧습니다.
4. 동시 정리: 사용자 스레드로 작업할 수 있습니다.
CMS 컬렉터의 단점:
1. 동시 단계에서는 사용자 스레드를 일시 중지시키지 않지만 스레드 리소스의 일부를 차지합니다. 시스템 수량의 총 처리량을 줄입니다.
2. 플로팅 가비지는 처리할 수 없습니다. 사용자 스레드를 실행하면 여전히 새로운 가비지 개체가 생성됩니다. 이 부분은 다음 GC에서만 수집될 수 있습니다.
3. CMS는 Mark-and-Sweep 알고리즘을 기반으로 구현되어 있으며, 이는 수집이 완료된 후 대량의 메모리 조각이 발생하여 메모리에 많은 양의 남은 공간이 발생할 수 있음을 의미합니다. 이전 세대에서는 현재 개체를 할당할 만큼 충분히 큰 연속 공간을 찾을 수 없으므로 미리 Full GC를 트리거해야 합니다.
JDK1.5 구현에서는 Old Generation 공간 사용량이 68%에 도달하면 CMS 수집기가 트리거됩니다. 애플리케이션의 Old Generation이 너무 빨리 성장하지 않으면 다음을 통해 트리거 비율을 높일 수 있습니다. -XX:CMSInitiatingOccupancyFraction 매개변수를 사용하여 메모리 재활용 횟수를 줄이고 시스템 성능을 향상시킵니다.
JDK1.6 구현에서는 CMS 수집기 트리거 임계값이 92%로 증가되었습니다. CMS 작업 중에 예약된 메모리가 사용자 스레드의 요구 사항을 충족할 수 없는 경우 "동시 모드 실패"가 발생합니다. 가상 머신은 이전 세대에서 가비지를 수집하기 위해 Serial Old 컬렉터를 시작합니다. 물론 애플리케이션의 일시 중지 시간이 길어지므로 "동시 모드 실패"가 발생하는 경우 이 임계값을 너무 높게 설정할 수 없습니다. " 실패하면 성능이 저하됩니다. 이 임계 값을 설정하는 방법은 Old Generation 공간의 사용량을 오랫동안 모니터링해야합니다.
7. G1 컬렉터
G1(Garbage First)은 JDK1.7에서 제공하는 "mark- 수집이 완료된 후 메모리 조각화 문제를 방지하기 위해 "조합" 알고리즘이 구현됩니다.
G1 장점:
1. 병렬성 및 동시성: 여러 CPU를 최대한 활용하여 Stop The World의 일시 중지 시간을 단축합니다.
2. 수집이 필요합니다. 협력을 통해 전체 Java 힙을 관리할 수 있고, 새로 생성된 객체, 일정 기간 동안 살아남고 여러 번의 GC를 경험한 객체를 다양한 방법으로 처리하여 더 나은 수집 효과를 얻을 수 있습니다.3. 공간 통합: CMS의 "mark-clear" 알고리즘과 달리 G1은 작동 중에 메모리 공간 조각화를 생성하지 않습니다. 이는 대규모 개체를 할당할 때 응용 프로그램의 장기적인 작동에 도움이 됩니다. 충분히 큰 객체. 연속 메모리는 사전에 Full GC를 트리거합니다.
4. 일시 중지 예측: 예측 가능한 일시 중지 시간 모델을 G1에서 설정할 수 있으므로 사용자는 내부에서 가비지 수집에 소요되는 시간을 명확하게 지정할 수 있습니다. M밀리초의 시간 세그먼트는 N밀리초를 초과할 수 없습니다.
G1 컬렉터를 사용할 때 Java 힙의 메모리 레이아웃은 다른 컬렉터와 매우 다릅니다. 전체 Java 힙은 동일한 크기의 여러 독립 영역으로 나누어집니다. 물리적으로 분리되어 있으며 모두 지역의 모음입니다(반드시 연속적인 것은 아님). G1은 각 Region의 가비지 수집 상태(재활용 공간 크기 및 재활용 시간)를 추적하고 우선 순위 목록을 유지하며 허용된 수집 시간을 기준으로 가장 큰 값을 갖는 Region에 우선 순위를 부여하여 전체 Region에서 가비지 수집을 방지합니다. Java 힙. G1 수집기가 제한된 시간 내에 최대한 많은 가비지를 수집할 수 있도록 합니다.
그러나 여기에 문제가 있습니다. G1 수집기를 사용하면 객체가 영역에 할당되고 Java 힙의 모든 객체와 참조 관계를 가질 수 있으므로 객체가 활성 상태인지 여부를 확인하는 방법입니다. 전체 Java 힙을 스캔해야 합니까? 실제로 이 문제는 이전 수집기에서도 발생했습니다. 새 세대에서 객체를 재활용할 때 이전 세대를 동시에 스캔해야 한다면 Minor GC의 효율성이 크게 떨어지게 됩니다.
이런 상황에 대해 가상머신은 해결책을 제시합니다. G1 컬렉터의 Region 간 객체 참조 관계와 다른 컬렉터의 신세대와 구세대 간 객체 참조 관계는 Remembered Set 데이터 구조에 저장됩니다. , 전체 힙 스캔을 방지하는 데 사용됩니다. G1의 각 영역에는 해당 Remenbered 세트가 있습니다. 가상 머신은 프로그램이 참조 유형의 데이터를 쓰고 있음을 발견하면 쓰기 작업을 일시적으로 중단하고 참조에서 참조하는 개체가 있는지 확인합니다. 동일 Region이 아닐 경우 CardTable을 통해 해당 참조 객체가 속한 Region의 Remenbered Set에 해당 참조 정보를 기록한다.
Java GC에 관한 것(1)
Java GC에 관한 것(2)
위 내용은 Java GC에 관한 것(2), more 관련 내용은 PHP 중국어 홈페이지(m.sbmmt.com)를 참고해주세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



