


소개
• 개요
• 무엇 뒤에 변수를 선언할 때 무슨 일이 일어났나요?
• 힙 및 스택
• 값 유형 및 참조 유형
• 값 유형과 참조 유형은 무엇입니까?
•박싱 및 언박싱
•박싱 및 언박싱의 성능 문제
1. 개요
이 문서에서는 힙이라는 6가지 중요한 개념을 설명합니다. , 스택, 값 유형, 참조 유형, 박싱 및 언박싱. 이 기사에서는 변수를 정의할 때 시스템 내부에서 어떤 일이 일어나는지 설명하는 것으로 시작한 다음 스토리지 듀오인 힙과 스택에 초점을 맞춥니다. 나중에 값 유형과 참조 유형을 살펴보고 이 두 유형에 대한 중요한 기본 사항을 설명합니다.
이 기사에서는 간단한 코드를 사용하여 박싱 및 개봉 과정 중 성능에 미치는 영향을 보여드리겠습니다.

2. 변수를 선언하면 뒤에서 무슨 일이 일어나나요?
.NET 애플리케이션에서 변수를 정의하면 해당 변수에 대한 일부 메모리 블록이 RAM에 할당됩니다. 이 메모리에는 변수 이름, 변수 데이터 유형, 변수 값의 세 가지 항목이 포함됩니다.
위는 메모리에서 어떤 일이 일어나는지에 대한 간략한 설명이지만, 변수가 정확히 어떤 메모리 유형에 할당될지는 데이터 유형에 따라 다릅니다. .NET에는 스택과 힙이라는 두 가지 유형의 할당 가능한 메모리가 있습니다. 다음 몇 섹션에서는 이 두 가지 유형의 스토리지를 자세히 이해하려고 노력할 것입니다.
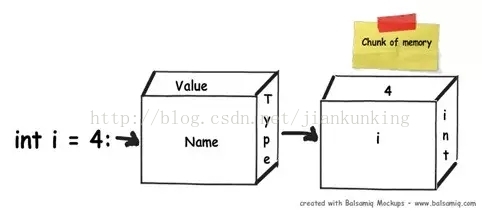
3. 스토리지 듀오: 힙과 스택
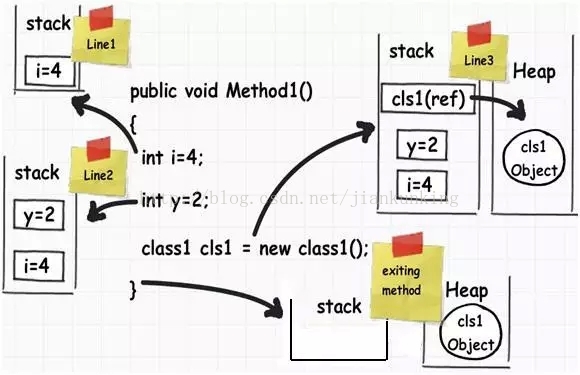
스택과 힙을 이해하기 위해 다음 코드를 통해 그 뒤에서 무슨 일이 일어나는지 이해해 보겠습니다.
public void Method1()
{
// Line 1
int i=4;
// Line 2
int y=2;
//Line 3
class1 cls1 = new class1();
}이제 코드가 한 줄씩 실행되는 방식을 이해할 수 있습니다.
•라인 1: 이 라인이 실행되면 컴파일러는 스택에 작은 메모리 조각을 할당합니다. 스택은 애플리케이션에 실행 메모리가 필요한지 추적하는 역할을 담당합니다
• 2행: 이제 두 번째 단계가 수행됩니다. 이름에서 알 수 있듯이 스택은 첫 번째 단계에서 방금 수행한 메모리 할당 위에 작은 메모리 할당을 쌓습니다. 스택은 서로 겹쳐진 방이나 상자로 생각할 수 있습니다. 스택에서는 LIFO(Last In First Out) 논리 규칙을 통해 데이터가 할당되고 할당 해제됩니다. 즉, 스택에 먼저 들어간 데이터 항목이 스택에서 가장 나중에 튀어나오는 항목일 수 있습니다.
•3번째 줄: 세 번째 줄에서는 객체를 생성합니다. 이 줄이 실행되면 .NET은 스택에 포인터를 생성하고 실제 개체는 "힙"이라는 메모리 영역에 저장됩니다. "힙"은 실행 중인 메모리를 모니터링하지 않으며 언제든지 액세스할 수 있는 개체 묶음일 뿐입니다. 스택과 달리 힙은 동적 메모리 할당에 사용됩니다.
•여기서 주목해야 할 또 다른 중요한 점은 객체의 참조 포인터가 스택에 할당된다는 것입니다. 예를 들어 Class1 cls1; 선언문은 실제로 Class1 인스턴스에 대한 메모리를 할당하지 않고 스택에 cls1 변수에 대한 참조 포인터를 생성하고 기본 위치를 null로 설정합니다. new 키워드를 만날 때만 힙의 개체에 메모리를 할당합니다.
•이 Method1 메소드(재미)를 떠날 때: 이제 실행 제어문이 메소드 본문을 떠나기 시작합니다. 이때 스택에서 변수에 할당된 메모리 공간이 모두 지워집니다. 즉, 위의 예에서는 int 유형과 관련된 모든 변수가 "LIFO" 후입선출 방식으로 스택에서 하나씩 팝됩니다.
•이번에는 힙에 있는 메모리 블록을 해제하지 않는다는 점에 유의해야 합니다. 힙에 있는 메모리 블록은 나중에 가비지 수집기에 의해 정리됩니다.
이제 많은 개발자 친구들이 왜 두 가지 유형의 스토리지가 있는지 궁금해할 것입니다. 왜 모든 메모리 블록을 한 가지 유형의 스토리지에만 할당할 수 없나요?
자세히 살펴보면 원시 데이터 유형은 복잡하지 않고 'int i = 0'과 같은 값만 보유합니다. 객체 데이터 유형은 더 복잡합니다. 다른 객체나 기타 기본 데이터 유형을 참조합니다. 즉, 여러 다른 값에 대한 참조를 보유하고 있으며 이러한 값은 하나씩 메모리에 저장되어야 합니다. 객체 유형에는 동적 메모리가 필요하고 기본 유형에는 정적 메모리가 필요합니다. 요구 사항이 동적 메모리이면 힙에 메모리를 할당하고, 그렇지 않으면 스택에 할당합니다.
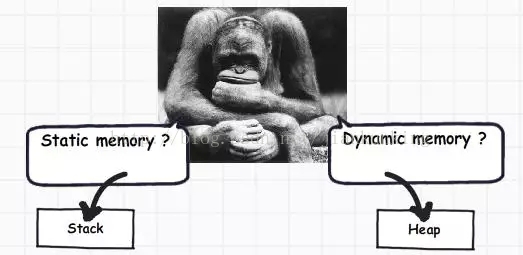
4. 값 유형과 참조 유형
이제 스택과 힙의 개념을 이해했으니 이제 값 유형을 이해해야 합니다. 및 참조 유형의 개념입니다. 값 유형은 데이터와 메모리를 모두 동일한 위치에 유지하는 반면 참조 유형은 실제 메모리 영역에 대한 포인터를 갖습니다.
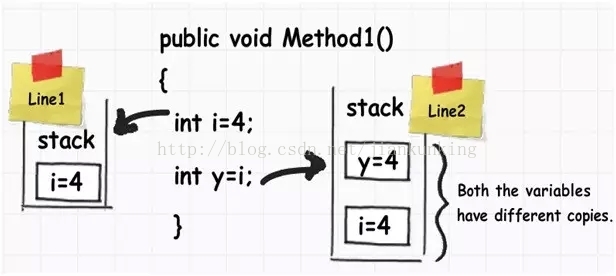
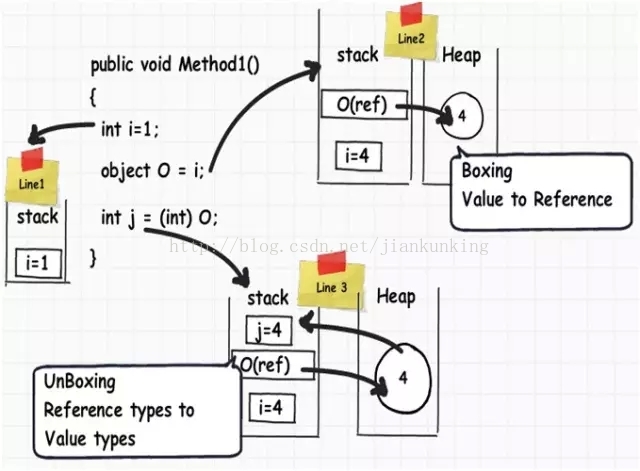
아래 그림을 보면 i라는 정수 데이터 유형이 있고, 그 값이 j라는 또 다른 정수 데이터 유형에 할당되어 있는 것을 볼 수 있습니다. 해당 값은 스택에 저장됩니다.
int 유형의 값을 int 유형의 다른 값에 할당하면 실제로 완전히 다른 복사본이 생성됩니다. 즉, 하나의 값을 변경해도 다른 값은 변경되지 않습니다. 따라서 이러한 종류의 데이터 유형을 "값 유형"이라고 합니다.
객체를 생성하고 이 객체를 다른 객체에 할당하면 아래 코드 스니펫에 표시된 것처럼 둘 다 동일한 메모리 영역을 가리킵니다. 따라서 obj를 obj1에 할당하면 둘 다 힙의 동일한 영역을 가리킵니다. 즉, 이때 둘 중 하나를 변경하면 다른 하나도 영향을 받게 되는데, 이를 "참조 유형"이라고 부르는 이유도 설명됩니다.
5. 값 유형과 참조 유형은 무엇인가요?
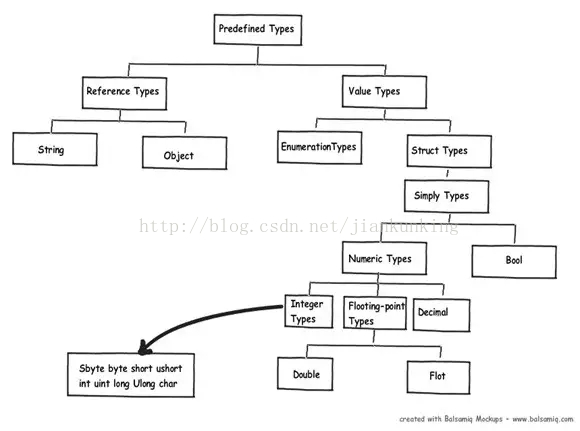
.NET에서 변수가 스택에 저장되는지 아니면 힙에 저장되는지는 해당 변수가 속한 데이터 유형에 따라 전적으로 달라집니다. 예를 들어 'String' 또는 'Object'는 참조 유형이고 다른 .NET 기본 데이터 유형은 스택에 할당됩니다. 아래 그림은 .NET 사전 설정 유형 중 어떤 것이 값 유형이고 어떤 것이 참조 유형인지 자세히 보여줍니다.
6. 포장 및 개봉
이제 이론적 기초는 많이 갖추었습니다. 이제 위의 지식이 실제 프로그래밍에서 어떻게 활용되는지 알아보겠습니다. 애플리케이션에서 가장 큰 의미 중 하나는 데이터가 스택에서 힙으로 또는 그 반대로 이동할 때 발생하는 성능 소비 문제를 이해하는 것입니다.
다음 코드 조각을 고려하세요. 값 유형을 참조 유형으로 변환하면 데이터가 스택에서 힙으로 이동됩니다. 반대로 참조 유형을 값 유형으로 변환하면 데이터도 힙에서 스택으로 이동됩니다.
스택에서 힙으로 이동하든, 힙에서 스택으로 이동하든 필연적으로 시스템 성능에 어느 정도 영향을 미치게 됩니다.
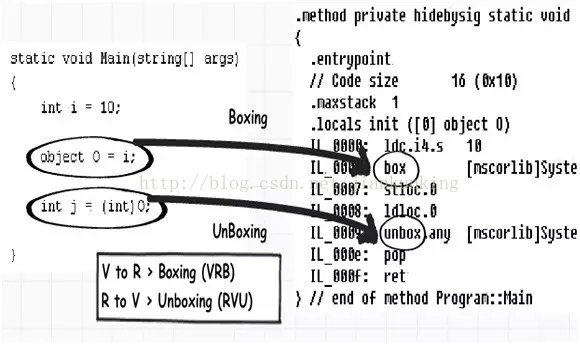
결과적으로 두 가지 새로운 용어가 등장했습니다. 데이터를 값 유형에서 참조 유형으로 변환하는 과정을 "박싱"이라고 하고, 참조 유형에서 참조 유형으로 변환하는 과정을 말합니다. 값 유형을 "boxing"이라고 합니다.
위 코드를 컴파일하고 ILDASM(IL 디컴파일 도구)에서 보면 IL 코드에서 boxing과 unboxing이 어떤 모습인지 알 수 있습니다. 좋다. 아래 그림은 샘플 코드가 컴파일된 후 생성된 IL 코드를 보여줍니다.
7.복싱 및 언박싱의 성능 문제
파악하기 위해서는 boxing과 unboxing은 성능에 어떤 영향을 미치나요? 아래 그림에 표시된 두 가지 함수 메서드를 루프에서 10,000번 실행합니다. 첫 번째 방법에는 복싱 작업이 있지만 다른 방법에는 없습니다. 우리는 Stopwatch 객체를 사용하여 시간 소비를 모니터링합니다.
복싱 작업이 있는 방법은 완료하는 데 3542밀리초가 걸린 반면, 복싱 작업이 없는 방법은 2477밀리초밖에 걸리지 않아 1초 이상의 차이가 납니다. 또한, 이 값은 사이클 수가 증가함에 따라 증가합니다. 즉, 박싱(boxing) 및 언박싱(unboxing) 작업을 피하도록 노력해야 합니다. 프로젝트에서 박스와 박스를 해야 한다면 그것이 절대적으로 필수적인 작업인지 신중하게 고려하고, 그렇지 않다면 사용하지 마십시오.

위의 코드 조각은 언박싱을 표시하지 않지만, 언박싱에도 효과가 적용됩니다. Unboxing을 구현하고 Stopwatch를 통해 시간 소모를 테스트하는 코드를 작성할 수 있습니다.
위는 .NET의 6가지 중요한 개념입니다: 스택, 힙, 값 유형, 참조 유형, 박싱 및 언박싱. 더 많은 관련 내용을 보려면 PHP 중국어 웹사이트(m.sbmmt.com)를 참고하세요. )!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



