

상하이 Jiaotong University, Shanghai AI Lab 및 Chinese University of Hong Kong의 연구원들은 Visual-RFT (Visual Enhancement Fine Tuning) 오픈 소스 프로젝트를 시작했으며, 이는 LVLM (Visual Language Mockups)의 성능을 크게 향상시키기 위해 소량의 데이터 만 필요합니다. Visual-Rft는 영리하게 DeepSeek-R1의 규칙 기반 강화 학습 접근 방식을 OpenAI의 RFT (Rencement Fine Tuning) 패러다임과 결합 하여이 접근법을 텍스트 필드에서 시야로 성공적으로 확장합니다.

Visual-RFT는 시각적 하위 분류 및 객체 감지와 같은 작업에 대한 해당 규칙 보상을 설계함으로써 텍스트, 수학적 추론 및 기타 필드로 제한되는 DeepSeek-R1 메소드의 한계를 극복하여 LVLM 교육을위한 새로운 방법을 제공합니다.

Visual-Rft의 장점 :
전통적인 시각적 지시 미세 조정 (SFT) 방법과 비교할 때 Visual-Rft는 다음과 같은 중요한 이점이 있습니다.
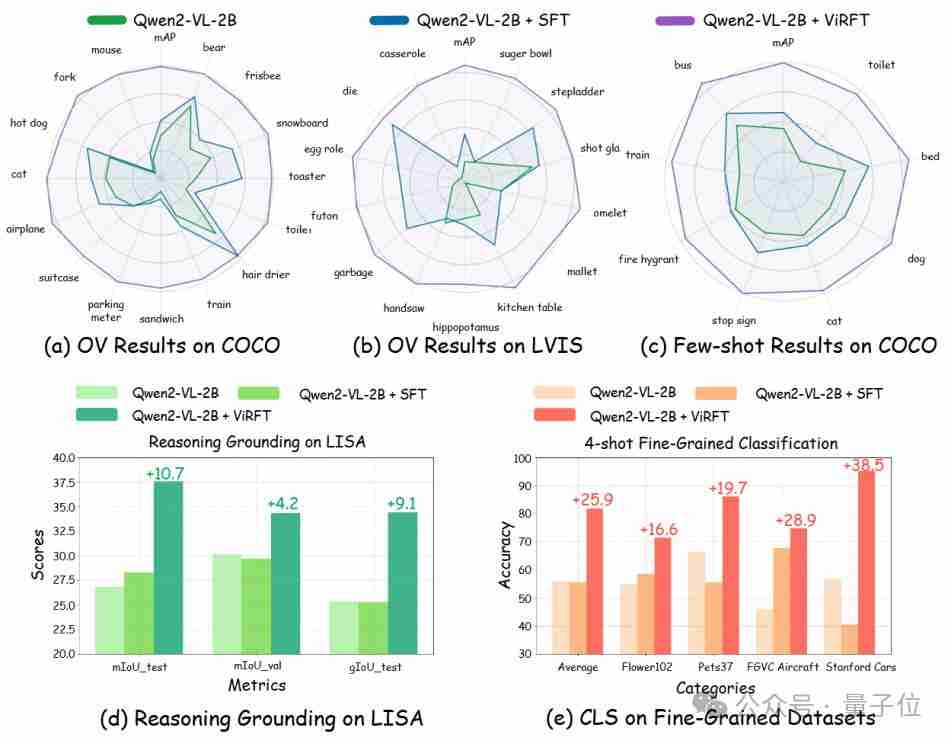
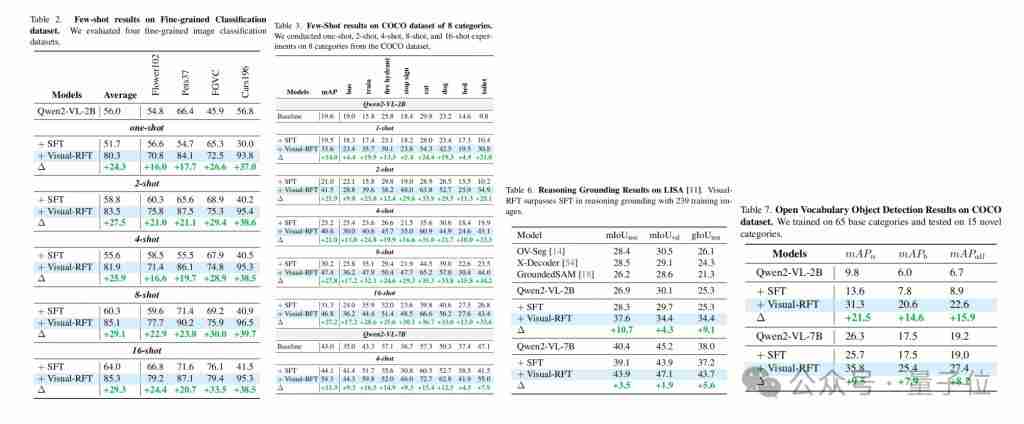
연구원들은 여러 시각적 인식 작업 (탐지, 분류, 위치 등)에 대해 Visual-RFT를 검증했으며, 결과는 개방형 어휘 및 작은 샘플 학습의 설정에서도 시각적 RFT가 상당한 성능 개선을 달성하고 쉽게 능력 전달을 달성 한 것으로 나타났습니다.
연구자들은 다양한 작업에 대한 해당 검증 가능한 보상을 설계했습니다. IOU 기반 보상은 탐지 및 위치 작업에 사용되며 분류 정확성 기반 보상은 분류 작업에 사용됩니다.
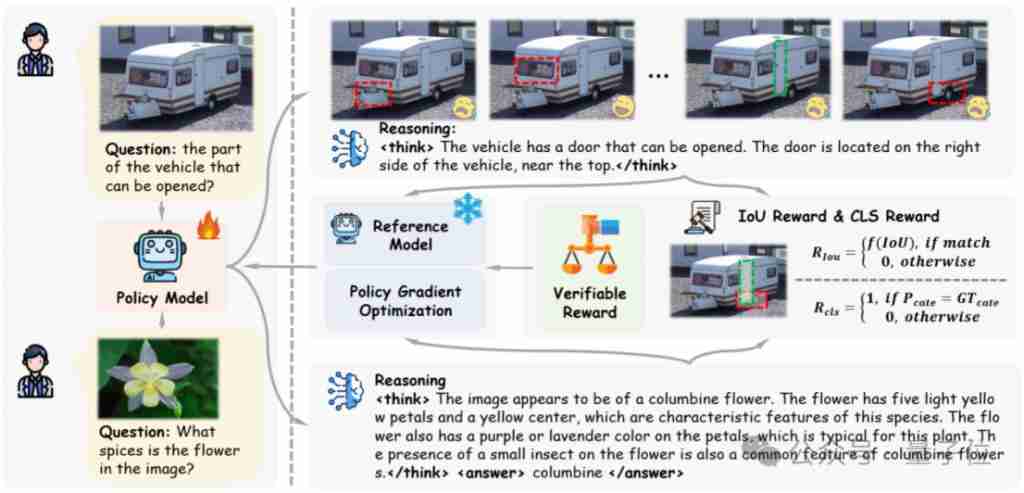
추론 포지셔닝 작업에서 Visual-Rft는 운동 선수가 그림에서 착용 해야하는 방수 안경을 정확하게 식별하는 것과 같은 강력한 시각적 추론 기능을 보여줍니다.


실험 결과 :
QWEN2-VL 2B/7B 모델을 기반으로 한 실험은 개방형 물체 감지, 작은 샘플 감지, 세밀한 분류 및 추론 포지셔닝 작업에서 SFT보다 시각적 RFT가 SFT보다 우수함을 보여줍니다. 특정 애니메이션 캐릭터 (예 : 점액)를 감지하더라도 소량의 데이터만으로 Visual-RFT를 달성 할 수 있습니다.
오픈 소스 정보 :
Visual-RFT 프로젝트는 오픈 소스이며 교육, 평가 코드 및 데이터를 포함합니다.
프로젝트 주소 : //m.sbmmt.com/link/ec5652bc9c2e15be17d11962eeec453

위 내용은 SFT를 상당히 능가하는 O1/DeepSeek-R1의 비밀은 멀티 모달 대형 모델에서도 사용할 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



