커피 한잔 사주세요😄
*메모:
-
내 게시물에서는 Vanishing Gradient 문제, Exploding Gradient 문제 및 Dying ReLU 문제에 대해 설명합니다.
-
내 게시물에서는 PyTorch의 레이어에 대해 설명합니다.
-
내 게시물에서는 PyTorch의 활성화 기능에 대해 설명합니다.
-
내 게시물에서는 PyTorch의 손실 기능에 대해 설명합니다.
-
내 게시물에서는 PyTorch의 최적화 프로그램에 대해 설명합니다.

*오버피팅과 과소피팅 모두 홀드아웃 방법이나 교차 검증(K-Fold Cross-Validation)으로 감지할 수 있습니다. *교차검증이 더 좋습니다.
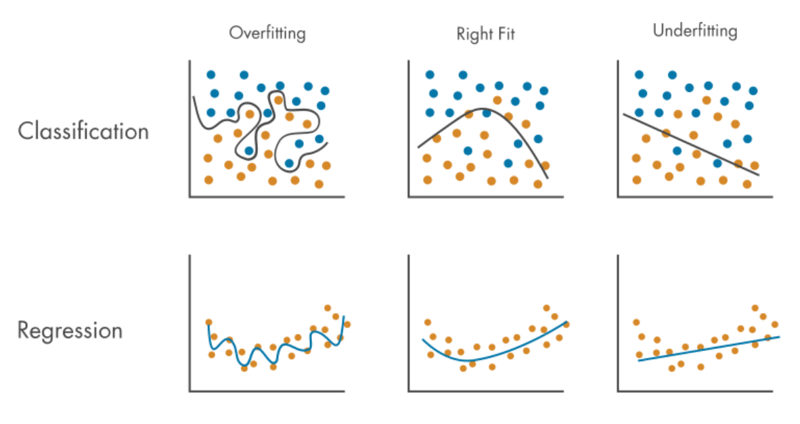
과적합:
- 모델이 기차 데이터에 대해서는 많이 정확하게 예측할 수 있지만 새 데이터(테스트 데이터 포함)에 대해서는 정확도가 낮아서 모델이 새 데이터보다 기차 데이터에 훨씬 더 적합하다는 문제입니다.
- 다음과 같은 이유로 발생합니다.
- 학습 데이터가 작아(충분하지 않음) 모델이 소수의 패턴만 학습할 수 있습니다.
- 학습 데이터는 특정(제한적), 유사 또는 동일한 데이터가 많지만 다양한 데이터가 많지 않아 모델이 적은 수의 패턴만 학습할 수 있는 불균형(편향)입니다.
- 열차 데이터에는 노이즈(노이즈 데이터)가 많기 때문에 모델은 노이즈의 패턴을 많이 학습하지만 일반 데이터의 패턴은 학습하지 않습니다. *노이즈(noisy data)는 이상값, 이상치 또는 때로는 중복된 데이터를 의미합니다.
- 세대 수가 너무 많아 훈련 시간이 너무 깁니다.
- 모델이 너무 복잡합니다.
- 다음을 통해 완화할 수 있습니다.
- 더 큰 열차 데이터.
- 다양한 데이터가 많아요.
- 소음을 줄입니다.
- 데이터세트를 섞습니다.
- 훈련을 조기 중단합니다.
- 앙상블 학습
- 모델 복잡성을 줄이기 위한 정규화:
*메모:
- Dropout(정규화)이 있습니다. *내 게시물에서는 Dropout 레이어에 대해 설명합니다.
- L1 Norm 또는 Lasso Regression이라고도 하는 L1 정규화가 있습니다.
- L2 Norm 또는 Ridge Regression이라고도 하는 L2 정규화가 있습니다.
-
내 게시물에서는 linalg.norm()에 대해 설명하고 있습니다.
-
내 게시물에서는 linalg.Vector_norm()에 대해 설명합니다.
-
내 게시물에서는 linalg.matrix_norm()에 대해 설명합니다.
과소적합:
- 모델이 train 데이터와 새 데이터(테스트 데이터 포함) 모두에 대해 정확한 예측을 많이 할 수 없어 모델이 train 데이터와 새 데이터 모두에 맞지 않는 문제입니다.
- 다음과 같은 이유로 발생합니다.
- 모델이 너무 단순합니다(복잡하지 않음).
- 교육 시간이 너무 짧고 Epoch 수가 너무 적습니다.
- 과도한 정규화(드롭아웃, L1 및 L2 정규화)가 적용되었습니다.
- 다음을 통해 완화할 수 있습니다.
- 모델 복잡성이 증가합니다.
- 에포크 수를 늘려 학습 시간을 늘립니다.
- 정규화 감소.
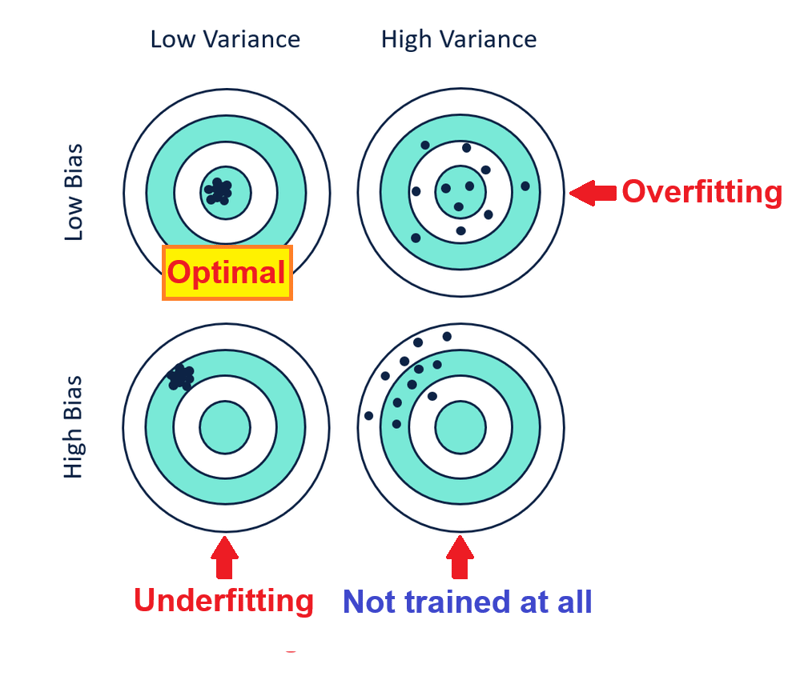
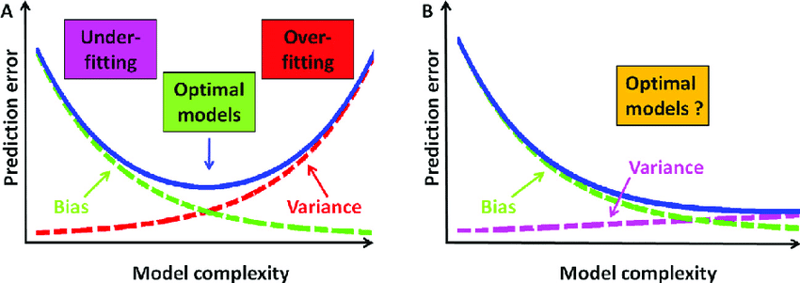
과대적합과 과소적합은 상충 관계입니다.
과대적합 완화(5., 6. 및 7.)가 너무 많으면 편향이 높고 분산이 낮은 과소적합이 발생하고 과소적합 완화가 너무 많습니다( 1., 2. 그리고 3.) 낮은 편향과 높은 분산으로 과적합을 초래하므로 완화는 아래와 같이 균형을 이루어야 합니다.
*메모:
-
편향과 분산은 상충됩니다라고 말할 수도 있습니다. 편향을 줄이면 분산이 증가하고 분산을 줄이면 편향이 증가하므로 균형을 이루어야 하기 때문입니다. *모델 복잡성을 높이면 편향은 줄어들지만 분산은 증가하고, 모델 복잡성을 줄이면 분산은 줄어들지만 편향은 증가합니다.
- 바이어스가 낮으면 정확도가 높고, 바이어스가 높으면 정확도가 낮습니다.
- 낮은 분산은 높은 정밀도를 의미하고, 높은 분산은 낮은 정밀도를 의미합니다.
위 내용은 과적합과 과소적합의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



