

먼저 Go가 설치되어 있어야 합니다. Go를 다운로드하고 설치하는 방법은 다음과 같습니다.
프로젝트를 위한 새 폴더를 생성하고 해당 디렉토리로 이동한 후 다음 명령을 실행합니다.
go mod init scraper
? go mod init 명령은 실행되는 디렉토리에서 새 Go 모듈을 초기화하고 코드 종속성을 추적하기 위해 go.mod 파일을 생성하는 데 사용됩니다. 종속성 관리
이제 Colibri를 설치해 보겠습니다.
go get github.com/gonzxlez/colibri
? Colibri는 JSON에 정의된 일련의 규칙을 사용하여 웹에서 구조화된 데이터를 크롤링하고 추출할 수 있게 해주는 Go 패키지입니다. 저장소
콜리브리가 필요한 데이터를 추출하는 데 사용할 규칙을 정의합니다. 문서
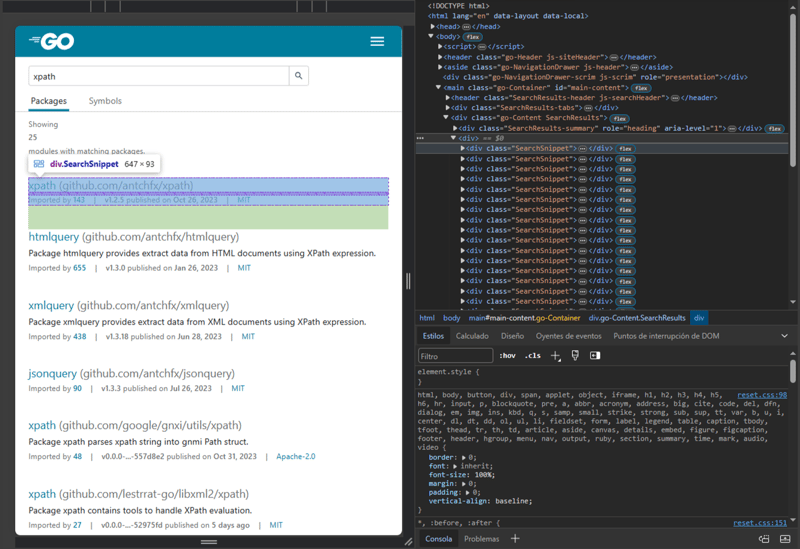
Go 패키지의 xpath와 관련된 Go 패키지에 대한 쿼리 결과가 포함된 URL https://pkg.go.dev/search?q=xpath에 HTTP 요청을 보내겠습니다.
웹 브라우저에 포함된 개발 도구를 사용하여 페이지의 HTML 구조를 검사할 수 있습니다. 브라우저 개발 도구는 무엇인가요?
<div class="SearchSnippet">
<div class="SearchSnippet-headerContainer">
<h2>
<a href="/github.com/antchfx/xpath" data-gtmc="search result" data-gtmv="0" data-test-id="snippet-title">
xpath
<span class="SearchSnippet-header-path">(github.com/antchfx/xpath)</span>
</a>
</h2>
</div>
<div class="SearchSnippet-infoLabel">
<a href="/github.com/antchfx/xpath?tab=importedby" aria-label="Go to Imported By">
<span class="go-textSubtle">Imported by </span><strong>143</strong>
</a>
<span class="go-textSubtle">|</span>
<span class="go-textSubtle">
<strong>v1.2.5</strong> published on <span data-test-id="snippet-published"><strong>Oct 26, 2023</strong></span>
</span>
<span class="go-textSubtle">|</span>
<span data-test-id="snippet-license">
<a href="/github.com/antchfx/xpath?tab=licenses" aria-label="Go to Licenses">
MIT
</a>
</span>
</div>
</div>
쿼리 결과를 나타내는 HTML 구조의 일부입니다.
그런 다음 SearchSnippet 클래스가 있는 HTML의 모든 div 요소를 찾는 선택기 "패키지"가 필요합니다. 해당 요소에서 " name”은 h2 요소 내에서 a 요소의 텍스트와 선택기 “path” 는 내 a 요소의 href 속성 값을 사용합니다. h2 요소입니다. 즉, "name"은 Go 패키지의 이름을 사용하고 "path"는 패키지 경로를 사용합니다 :)
{
"method": "GET",
"url": "https://pkg.go.dev/search?q=xpath",
"timeout": 10000,
"selectors": {
"packages": {
"expr": "div.SearchSnippet",
"all": true,
"type": "css",
"selectors": {
"name": "//h2/a/text()",
"path": "//h2/a/@href"
}
}
}
}
package main
import (
"encoding/json"
"fmt"
"github.com/gonzxlez/colibri"
"github.com/gonzxlez/colibri/webextractor"
)
var rawRules = `{
"method": "GET",
"url": "https://pkg.go.dev/search?q=xpath",
"timeout": 10000,
"selectors": {
"packages": {
"expr": "div.SearchSnippet",
"all": true,
"type": "css",
"selectors": {
"name": "//h2/a/text()",
"path": "//h2/a/@href"
}
}
}
}`
func main() {
we, err := webextractor.New()
if err != nil {
panic(err)
}
var rules colibri.Rules
err = json.Unmarshal([]byte(rawRules), &rules)
if err != nil {
panic(err)
}
output, err := we.Extract(&rules)
if err != nil {
panic(err)
}
fmt.Println("URL:", output.Response.URL())
fmt.Println("Status code:", output.Response.StatusCode())
fmt.Println("Content-Type", output.Response.Header().Get("Content-Type"))
fmt.Println("Data:", output.Data)
}
webextractor의 새로운 기능을 사용하여 데이터 추출을 시작하는 데 필요한 Colibri 구조를 생성합니다.
그런 다음 JSON의 규칙을 Rules 구조로 변환하고 규칙을 인수로 보내는 Extract 메소드를 호출합니다.
HTTP 응답의 출력과 URL, HTTP 상태 코드, 응답의 콘텐츠 유형 및 선택기로 추출된 데이터를 화면에 인쇄합니다. 출력 구조에 대한 문서를 참조하세요.
다음 명령을 실행합니다.
go mod tidy
마지막으로 다음 명령을 사용하여 Go에서 코드를 컴파일하고 실행합니다.
go run scraper.go
간단히 말하면 Go의 Web Scraping은 다양한 웹사이트에서 정보를 추출하는 데 사용할 수 있는 강력하고 다재다능한 기술입니다. 웹 스크래핑은 웹사이트의 이용 약관을 존중하고 서버 과부하를 피하면서 윤리적으로 수행되어야 한다는 점을 강조하는 것이 중요합니다.
위 내용은 웹 스크래핑 시작의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



