

안녕하세요!
오늘 저는 데이터 과학과 사이버 보안이라는 두 가지 도메인을 포함하기로 결정했습니다.
따라오시면 제가 쓴 내용을 보실 수 있습니다.
조직 유형에 따른 공격 횟수 분석을 진행했습니다.
Kaggle에서 데이터세트를 다운로드했습니다.
그러다가 Jupyter Lab과 Python을 사용하여 데이터 작업을 시작했습니다.
노트북은 연습용으로, 데이터를 테스트하고 관찰하거나 가지고 놀 수 있습니다.
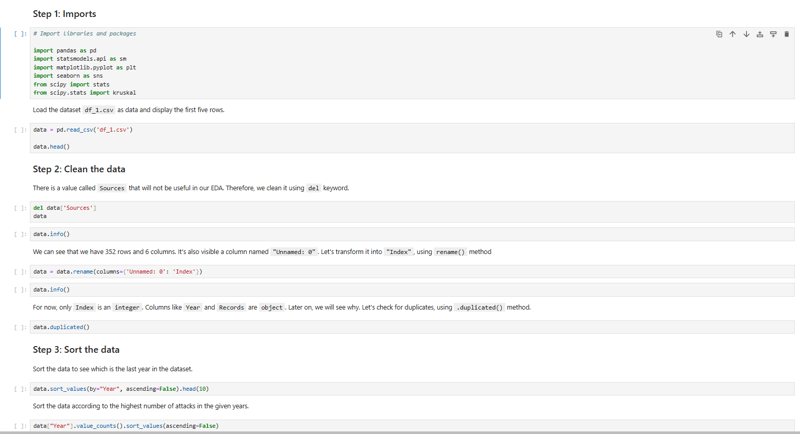
평소처럼 가장 먼저 데이터를 가져왔습니다. 그런 다음 데이터 세트를 로드하고 정리했습니다.
EDA(탐색적 데이터 분석)는 반복적이고 비순차적인 프로세스이기 때문에 데이터 정리는 더 많이 수행할 수 있는 단계입니다. 그래서 이후에도 의미 있는 인사이트를 찾아내기 위해 이 과정을 계속했습니다.
공격 횟수를 기준으로 어떤 조직이 사이버 공격에 더 취약한지 알아보기 위해n=40의 단순 무작위 샘플링을 선택했습니다. 단순 무작위 샘플링은 모집단의 모든 구성원이 선택될 확률이 동일하다는 것을 의미합니다.
가설
귀무가설(H0): 조직 유형별로 경험한 사이버 공격 횟수에는 큰 차이가 없습니다.
대체 가설(H1): 사이버 공격 횟수는 조직 유형에 따라 크게 다릅니다.
최대 공격 횟수 기준으로헬스케어업종이 6회 공격으로 취약성이 더 높은 것으로 결론지었습니다. 반면,뱅킹은 공격 횟수가 1회로 가장 낮았습니다.
마지막으로 데이터 세트의 분포 정규성을 확인하기 위해 Shapiro-Wilk 테스트를 수행했습니다. 귀무가설이 기각되어 데이터가 정규 분포를 따르지 않는 것으로 보입니다. 나는 Kruskal-Wallis 테스트를 적용했는데, 귀무 가설을 기각하지 못했습니다. 즉, 그룹 간에 유의미한 차이가 없다는 의미입니다. 간단히 말해서, 한 조직 유형이 다른 조직 유형보다 사이버 공격에 더 취약하다고 자신있게 말할 수 있는 증거가 충분하지 않다는 의미입니다.
신뢰 수준 없음, 오차 한계 및 신뢰 구간이 설정되었습니다. 표본 크기가 작으므로 통계적으로 유의미한 차이를 탐지하기가 더 어렵습니다. 앞으로는 샘플 선택 시 이러한 단계를 존중하고 더 큰 샘플을 고려할 것입니다.
제 GitHub 페이지에서전체작업을 확인하실 수 있습니다. ?
제가 명시한 대로 이 기사에는보너스가 있습니다. 데이터 과학과 사이버 보안의 결합은 계속됩니다. TryHackMe 룸 Attacktive Directory에 대한 글을 작성했습니다!
언뜻 보면 이 주제들은 서로 관련이 없다고 말할 수 있습니다. 사실 이는어떻게침해가 발생할 수 있는지 보여주는 시연입니다! ? 데이터 침해는어쨌든그리고어떤 이유로나타나기 때문입니다.
궁금하시죠? 글쎄, 내 GitHub 페이지에서 내 글을 확인하세요.
당신의 생각은 무엇입니까?
위 내용은 데이터 침해에 대한 응용 데이터 과학 + 보너스의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



