

In the previous blog we saw how to install and setup neo4j locally with 2 plugins APOC and Graph Data Science Library - GDS. In this blog I am going to take a toy dataset(products in a e-commerce website) and store that in Neo4j.
Before starting to load the data if in your use case you have huge data ensure that sufficient amount of memory is allocated to neo4j. To do that :



Graphs have two primary components nodes and relationships, let's create the nodes first and later establish the relationships.
The data I am using is present here - data
Use the requirements.txt present here to create a python virtual environment - requirements.txt
Let's define various functions to push data.
Importing necessary libraries
import pandas as pd from neo4j import GraphDatabase from openai import OpenAI
client = OpenAI(api_key="") product_data_df = pd.read_csv('../data/product_data.csv')
def get_embedding(text): """ Used to generate embeddings using OpenAI embeddings model :param text: str - text that needs to be converted to embeddings :return: embedding """ model = "text-embedding-3-small" text = text.replace("\n", " ") return client.embeddings.create(input=[text], model=model).data[0].embedding
def create_category(product_data_df): """ Used to generate queries for creating category nodes in neo4j :param product_data_df: pandas dataframe - data :return: query_list: list - list containing all create node queries for category """ cat_query = """CREATE (a:Category {name: '%s', embedding: %s})""" distinct_category = product_data_df['Category'].unique() query_list = [] for category in distinct_category: embedding = get_embedding(category) query_list.append(cat_query % (category, embedding)) return query_list
def create_product(product_data_df): """ Used to generate queries for creating product nodes in neo4j :param product_data_df: pandas dataframe - data :return: query_list: list - list containing all create node queries for product """ product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d, available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})""" query_list = [] for idx, row in product_data_df.iterrows(): embedding = get_embedding(row['Product Name'] + " - " + row['Description']) query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']), int(row['Warranty Period (Years)']), int(row['Stock']), float(row['Review Rating']), str(row['Product Release Date']), embedding)) return query_list
def execute_bulk_query(query_list): """ Executes queries is a list one by one :param query_list: list - list of cypher queries :return: None """ url = "bolt://localhost:7687" auth = ("neo4j", "neo4j@123") with GraphDatabase.driver(url, auth=auth) as driver: with driver.session() as session: for query in query_list: try: session.run(query) except Exception as error: print(f"Error in executing query - {query}, Error - {error}")
import pandas as pd from neo4j import GraphDatabase from openai import OpenAI client = OpenAI(api_key="") product_data_df = pd.read_csv('../data/product_data.csv') def preprocessing(df, columns_to_replace): """ Used to preprocess certain column in dataframe :param df: pandas dataframe - data :param columns_to_replace: list - column name list :return: df: pandas dataframe - processed data """ df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s")) df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", "")) return df def get_embedding(text): """ Used to generate embeddings using OpenAI embeddings model :param text: str - text that needs to be converted to embeddings :return: embedding """ model = "text-embedding-3-small" text = text.replace("\n", " ") return client.embeddings.create(input=[text], model=model).data[0].embedding def create_category(product_data_df): """ Used to generate queries for creating category nodes in neo4j :param product_data_df: pandas dataframe - data :return: query_list: list - list containing all create node queries for category """ cat_query = """CREATE (a:Category {name: '%s', embedding: %s})""" distinct_category = product_data_df['Category'].unique() query_list = [] for category in distinct_category: embedding = get_embedding(category) query_list.append(cat_query % (category, embedding)) return query_list def create_product(product_data_df): """ Used to generate queries for creating product nodes in neo4j :param product_data_df: pandas dataframe - data :return: query_list: list - list containing all create node queries for product """ product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d, available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})""" query_list = [] for idx, row in product_data_df.iterrows(): embedding = get_embedding(row['Product Name'] + " - " + row['Description']) query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']), int(row['Warranty Period (Years)']), int(row['Stock']), float(row['Review Rating']), str(row['Product Release Date']), embedding)) return query_list def execute_bulk_query(query_list): """ Executes queries is a list one by one :param query_list: list - list of cypher queries :return: None """ url = "bolt://localhost:7687" auth = ("neo4j", "neo4j@123") with GraphDatabase.driver(url, auth=auth) as driver: with driver.session() as session: for query in query_list: try: session.run(query) except Exception as error: print(f"Error in executing query - {query}, Error - {error}") # PREPROCESSING product_data_df = preprocessing(product_data_df, ['Product Name', 'Description']) # CREATE CATEGORY query_list = create_category(product_data_df) execute_bulk_query(query_list) # CREATE PRODUCT query_list = create_product(product_data_df) execute_bulk_query(query_list)
from neo4j import GraphDatabase import pandas as pd product_data_df = pd.read_csv('../data/product_data.csv') def preprocessing(df, columns_to_replace): """ Used to preprocess certain column in dataframe :param df: pandas dataframe - data :param columns_to_replace: list - column name list :return: df: pandas dataframe - processed data """ df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s")) df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", "")) return df def create_category_food_relationship_query(product_data_df): """ Used to create relationship between category and products :param product_data_df: dataframe - data :return: query_list: list - cypher queries """ query = """MATCH (c:Category {name: '%s'}), (p:Product {name: '%s'}) CREATE (c)-[:CATEGORY_CONTAINS_PRODUCT]->(p)""" query_list = [] for idx, row in product_data_df.iterrows(): query_list.append(query % (row['Category'], row['Product Name'])) return query_list def execute_bulk_query(query_list): """ Executes queries is a list one by one :param query_list: list - list of cypher queries :return: None """ url = "bolt://localhost:7687" auth = ("neo4j", "neo4j@123") with GraphDatabase.driver(url, auth=auth) as driver: with driver.session() as session: for query in query_list: try: session.run(query) except Exception as error: print(f"Error in executing query - {query}, Error - {error}") # PREPROCESSING product_data_df = preprocessing(product_data_df, ['Product Name', 'Description']) # CATEGORY - FOOD RELATIONSHIP query_list = create_category_food_relationship_query(product_data_df) execute_bulk_query(query_list)
Hover over theopenicon and click onneo4j browserto visualize the nodes that we have created.
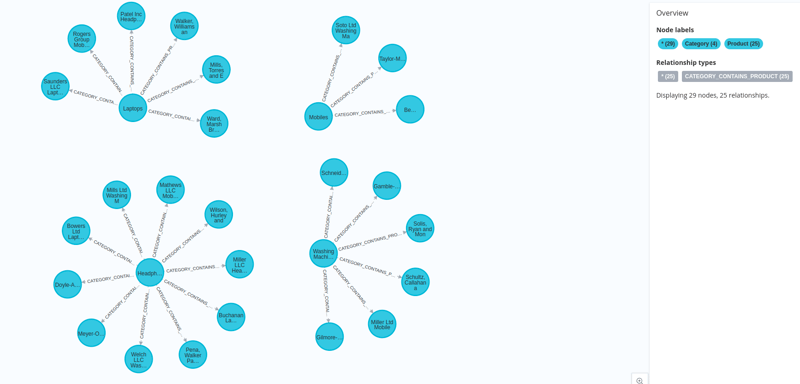
And our data is loaded into neo4j along with their embeddings.
In the fore-coming blogs we'll see how to build a graph query engine using python and use the fetched data to do augmented generation.
Hope this helps... See you !!!
LinkedIn - https://www.linkedin.com/in/praveenr2998/
Github - https://github.com/praveenr2998/Creating-Lightweight-RAG-Systems-With-Graphs/tree/main/push_data_to_db
위 내용은 Neo4j에 데이터 로드의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



