

소형 모델의 대두.
지난 달 Meta는 현재까지 Meta의 가장 큰 405B 모델과 각각 700억 개의 매개변수와 80억 개의 매개변수를 가진 두 개의 작은 모델을 포함하는 Llama 3.1 모델 시리즈를 출시했습니다.
Llama 3.1은 오픈 소스의 새로운 시대를 여는 것으로 간주됩니다. 그러나 차세대 모델은 성능이 강력하더라도 배포 시 여전히 많은 양의 컴퓨팅 리소스가 필요합니다.
따라서 업계에서는 또 다른 추세가 나타났습니다. 이는 다양한 언어 작업에서 충분히 성능을 발휘하고 배포 비용도 매우 저렴한 소규모 언어 모델(SLM)을 개발하는 것입니다.
최근 NVIDIA 연구에 따르면 지식 증류와 결합된 구조화된 가중치 가지치기를 통해 처음에는 더 큰 모델에서 더 작은 언어 모델을 점차적으로 얻을 수 있는 것으로 나타났습니다. 튜링상 수상자이자 메타 AI 수석 과학자인 M 얀 레쿤(M Yann Lecun)도 이번 연구에 찬사를 보냈다.

Llama-3.1-Minitron 4B는 Minitron 4B, Phi-2 2.7B, Gemma2 2.6B 및 Qwen2-1.5B를 포함하여 비슷한 크기의 최첨단 오픈 소스 모델보다 성능이 뛰어납니다.
이 연구의 관련 논문은 이르면 지난달 발표됐습니다.

논문 링크: https://www.arxiv.org/pdf/2407.14679

두 가지 주요 증류 방법이 있습니다. SDG 미세 조정과 고전 지식 증류입니다. 이 두 가지 증류 방법은 상호보완적입니다. 이 기사에서는 고전 지식 증류 방법에 중점을 둡니다.
NVIDIA는 가지치기와 고전 지식 증류를 결합한 방법을 사용하여 대형 모델을 구성합니다. 아래 그림은 단일 모델의 가지치기 및 증류 과정(상단)과 모델 가지치기 및 증류의 체인(하단)을 보여줍니다. 구체적인 프로세스는 다음과 같습니다. 1. NVIDIA는 15B 모델로 시작하여 각 구성 요소(레이어, 뉴런, 헤드 및 임베딩 채널)의 중요성을 평가한 다음 모델을 정렬하고 정리하여 목표 크기인 8B 모델에 도달합니다. 2. 그런 다음 원래 모델을 교사로, 정리된 모델을 학생으로 사용하여 가벼운 재훈련을 위해 모델 증류를 사용합니다. 3. 훈련 후 작은 모델(8B)을 출발점으로 삼아 가지치기하고 증류하여 더 작은 4B 모델로 만듭니다. 15B 모델의 가지치기 및 증류 과정. 주의할 점은 모델을 잘라내기 전에 모델의 어떤 부분이 중요한지 이해해야 한다는 것입니다. NVIDIA는 1024개 샘플의 소규모 보정 데이터 세트를 사용하여 모든 관련 차원(깊이, 뉴런, 헤드 및 임베딩 채널)의 정보를 동시에 계산하는 활성화 기반 순수 중요도 평가 전략을 제안하며 순방향 전파만 필요합니다. 이 접근 방식은 기울기 정보에 의존하고 역전파가 필요한 전략보다 더 간단하고 비용 효율적입니다. 가지치기 중에 특정 축 또는 축 조합에 대한 가지치기와 중요도 추정을 반복적으로 번갈아 가며 수행할 수 있습니다. 경험적 연구에 따르면 단일 중요도 추정을 사용하는 것만으로도 충분하며 반복 추정이 추가적인 이점을 가져오지 않는 것으로 나타났습니다.
아래 그림 2는 M층 Teacher 모델(원래 가지치기되지 않은 모델)에서 N 계층 학생 모델(가지치기 모델)을 증류하는 증류 과정을 보여줍니다. 스튜던트 모델은 스튜던트 블록 S와 티처 블록 T에 매핑된 임베딩 출력 손실, 로짓 손실, 변환기 인코더별 손실의 조합을 최소화하여 학습됩니다. 그림 2: 증류 훈련 손실.

가지치기 및 증류 모범 사례NVIDIA 압축 언어 모델을 기반으로 한 가지치기 및 지식 증류 기반 광범위한 절제 연구를 통해 학습 결과를 다음과 같은 구조화된 압축 모범 사례로 요약했습니다.
첫번째는 사이즈 조절입니다.LLM 세트를 훈련하려면 가장 큰 LLM을 먼저 훈련한 다음 반복적으로 가지치기 및 증류를 통해 더 작은 LLM을 얻습니다. 다단계 학습 전략을 사용하여 가장 큰 모델을 학습하는 경우 마지막 학습 단계에서 얻은 모델을 잘라내고 다시 학습하는 것이 가장 좋습니다.
# ## # 선생님 미세 조정
깊이 전용 가지치기모델 교육의 기반이 되는 원본 데이터 세트의 분포 편향을 수정하기 위해 NVIDIA는 먼저 정리되지 않은 8B 모델을 해당 모델에서 교육했습니다. 데이터 세트(94B 토큰) 미세 조정되었습니다. 실험에 따르면 분포 편향이 수정되지 않으면 교사 모델이 추출 시 데이터 세트에 대해 최적이 아닌 지침을 제공하는 것으로 나타났습니다.
아래 그림 5는 1, 2, 8 또는 16개 레이어를 제거한 후 검증 세트의 LM 손실 값을 보여줍니다. 예를 들어, 레이어 16에 대한 빨간색 플롯은 처음 16개 레이어가 제거될 경우 발생하는 LM 손실을 나타냅니다. 레이어 17은 첫 번째 레이어를 유지하고 레이어 2~17을 삭제해도 LM 손실이 발생함을 나타냅니다. Nvidia는 다음과 같이 관찰합니다. 시작 및 종료 레이어가 가장 중요합니다.
~ 그림 5: 중간 레이어의 깊이만 가지치기의 중요성.
그러나 NVIDIA는 이러한 LM 손실이 반드시 다운스트림 성능과 직접적인 관련이 있는 것은 아니라는 점을 관찰했습니다. 아래 그림 6은 각 가지치기 모델의 Winogrande 정확도를 보여주며, 이는 16~31번째 레이어를 삭제하는 것이 가장 좋음을 보여줍니다. 여기서 31번째 레이어는 끝에서 두 번째 레이어, 5번째는 가지치기 모델 -shot 정확도는 무작위 정확도(0.5)보다 훨씬 높습니다. Nvidia는 이 통찰력을 채택하고 레이어 16부터 31까지 제거했습니다.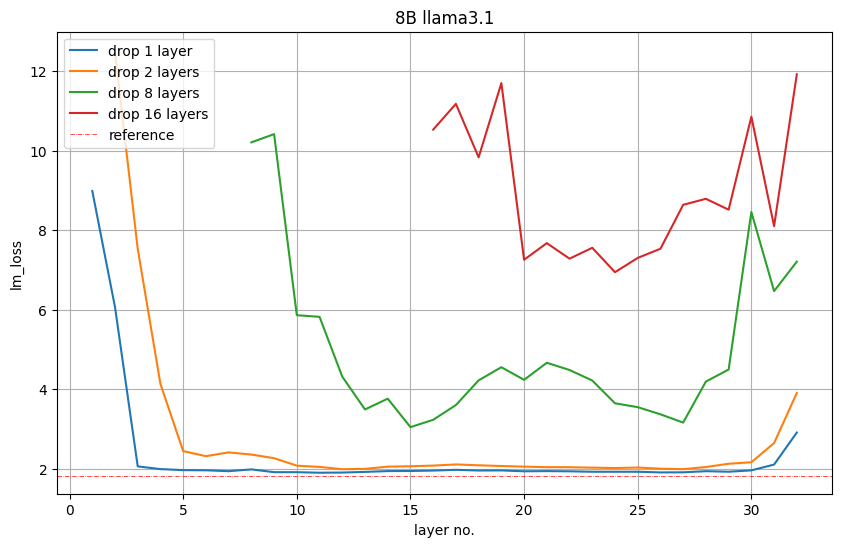
정확성.
너비 전용 가지치기
 NVIDIA는 너비 축을 따라 임베딩(숨김) 및 MLP를 잘라냅니다. 중간 크기 Llama 3.1 8B를 압축합니다. 구체적으로 그들은 앞서 설명한 활성화 기반 전략을 사용하여 각 관심 헤드, 임베딩 채널 및 MLP 숨겨진 차원에 대한 중요도 점수를 계산합니다.
NVIDIA는 너비 축을 따라 임베딩(숨김) 및 MLP를 잘라냅니다. 중간 크기 Llama 3.1 8B를 압축합니다. 구체적으로 그들은 앞서 설명한 활성화 기반 전략을 사용하여 각 관심 헤드, 임베딩 채널 및 MLP 숨겨진 차원에 대한 중요도 점수를 계산합니다.
중요도 평가 후 NVIDIA는 MLP 중간 차원을 14336에서 9216으로 정리하기 위해을 선택했습니다.
숨겨진 크기를 4096에서 3072로 정리합니다.
헤드 수와 레이어 수에 다시 주의를 기울이세요.
단일 표본 가지치기 후 너비 가지치기의 LM 손실이 깊이 가지치기의 LM 손실보다 높다는 점은 언급할 가치가 있습니다. 그러나 짧은 재교육 기간 이후 추세는 반전되었습니다.
정확도 벤치마크
NVIDIA는 다음 매개변수를 사용하여 모델을 증류했습니다
최대 학습률 = 1e-4
최소 학습률 = 1e-5
40단계 선형 워밍업
Cosine Decay Plan
글로벌 배치 크기 = 1152
아래 표 1은 원래 Llama 3.1 8B 모델과 유사한 Llama-3.1-Minitron 4B 모델 변형(너비 가지치기 및 깊이 가지치기), 기타 성능 비교를 보여줍니다. 여러 도메인에 걸친 벤치마크에 대한 크고 작은 모델의 비교. 전반적으로 NVIDIA는 모범 사례를 따르는 심층 가지치기와 비교하여 넓은 가지치기 전략의 효율성을 다시 한 번 확인했습니다. ㅋㅋㅋ 표 1: 정확도 비교 Minitron 4B 기본 모델과 유사한 규모의 기본 모델 비교.

그들은 Nemotron-4 340B 교육 데이터를 사용하고 IFEval, MT-Bench, ChatRAG-Bench 및 BFCL(Berkeley Function Calling Leaderboard)을 평가하여 지시 따르기, 롤플레잉, RAG 및 함수 호출 기능을 테스트했습니다. 마지막으로 Llama-3.1-Minitron 4B 모델이 신뢰할 수 있는 명령 모델이 될 수 있으며 다른 기본 SLM보다 성능이 우수하다는 것이 확인되었습니다. ㅋㅋㅋ ~ 표 2: 정렬된 Minitron 4B 기본 모델과 비슷한 크기의 정렬된 모델의 정확도 비교.
성능 벤치마크
NVIDIA는 LLM 추론 최적화를 위한 오픈 소스 툴킷인 NVIDIA TensorRT-LLM을 사용하여 Llama 3.1 8B 및 Llama-3.1-Minitron 4B 모델을 최적화했습니다. 다음 두 그림은 다양한 사용 사례에서 FP8 및 FP16 정밀도로 다양한 모델의 초당 처리량 요청을 보여주며, 8B에 대한 배치 크기 32의 입력 시퀀스 길이/출력 시퀀스 길이(ISL/OSL) 조합으로 표현됩니다. 모델 및 4B 모델의 배치 크기는 NVIDIA H100 80GB GPU에서 더 큰 배치 크기를 허용하는 더 작은 가중치 덕분에 64의 입력 시퀀스 길이/출력 시퀀스 길이(ISL/OSL) 조합입니다.
다음 두 그림은 다양한 사용 사례에서 FP8 및 FP16 정밀도로 다양한 모델의 초당 처리량 요청을 보여주며, 8B에 대한 배치 크기 32의 입력 시퀀스 길이/출력 시퀀스 길이(ISL/OSL) 조합으로 표현됩니다. 모델 및 4B 모델의 배치 크기는 NVIDIA H100 80GB GPU에서 더 큰 배치 크기를 허용하는 더 작은 가중치 덕분에 64의 입력 시퀀스 길이/출력 시퀀스 길이(ISL/OSL) 조합입니다.
Llama-3.1-Minitron-4B-Depth-Base 변형은 Llama 3.1 8B보다 평균 처리량이 약 2.7배로 가장 빠르며, Llama-3.1-Minitron-4B-Width-Base 변형은 평균 처리량을 갖습니다. Llama 3.1 8B의 처리량은 약 1.8배입니다. FP8에 배포하면 세 가지 모델 모두 BF16에 비해 성능이 약 1.3배 향상됩니다.
~ 80GB GPU.
결론
 Llama-3.1-Minitron 4B는 최첨단 오픈 소스 Llama 3.1 시리즈를 사용하려는 NVIDIA의 첫 번째 시도입니다. NVIDIA NeMo와 함께 Llama-3.1의 SDG 미세 조정을 사용하려면 GitHub의 /sdg-law-title-generation 섹션을 참조하세요.
Llama-3.1-Minitron 4B는 최첨단 오픈 소스 Llama 3.1 시리즈를 사용하려는 NVIDIA의 첫 번째 시도입니다. NVIDIA NeMo와 함께 Llama-3.1의 SDG 미세 조정을 사용하려면 GitHub의 /sdg-law-title-generation 섹션을 참조하세요.
자세한 내용은 다음 리소스를 참조하세요.https://arxiv.org/abs/2407.14679
https://github.com/NVlabs/Minitron
https:// Huggingface.co/nvidia/Llama-3.1-Minitron-4B-Width-Base
https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b -모델/
위 내용은 Nvidia는 가지치기 및 증류 작업을 수행합니다. 동일한 크기로 더 나은 성능을 달성하기 위해 Llama 3.1 8B의 매개변수를 절반으로 줄였습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



