AIxiv 칼럼은 본 사이트에 학술적, 기술적 내용을 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
이 기사의 첫 번째 저자는 이전에 스탠포드 대학교 대학원생인 Cai Wenxiao입니다. 1학년 점수. 그의 연구 관심 분야에는 다중 모드 대형 모델과 구체화된 지능이 포함됩니다. 이 작업은 그가 Shanghai Jiao Tong University를 방문하고 베이징 Zhiyuan 인공 지능 연구소에서 인턴십을 하는 동안 완료되었습니다. 그의 지도교수는 이 기사의 교신 저자인 Zhao Bo 교수였습니다. 이전에 Li Feifei 선생님이 공간 지능 개념을 제안했습니다. 이에 대응하여 Shanghai Jiao Tong University, Stanford University, Zhiyuan University, Peking University, Oxford University 및 Dongda University의 연구원들은 대규모 공간 모델 SpatialBot을 제안했습니다. 또한 다중 모달 대형 모델이 일반 시나리오와 구현된 시나리오에서 깊이와 공간을 이해할 수 있도록 훈련 데이터 SpatialQA와 테스트 목록 SpatialBench를 제안했습니다. 
- 논문 제목: SpatialBot: Vision Language Models를 통한 정확한 깊이 이해
- 논문 링크: https://arxiv.org/abs/2406.13642
- 프로젝트 홈페이지: https://github. com/BAAI-DCAI/SpatialBot
구체지능의 픽 앤 플레이스 작업에서는 기계 발톱이 대상 물체에 닿았는지 판단하는 것이 필요합니다. 마주치면 발톱을 닫고 잡을 수 있습니다. 그러나 이 Berkerly UR5 데모 데이터 세트 장면에서는 GPT-4o나 인간조차도 단일 RGB 이미지에서 기계적 발톱이 대상 물체에 닿았는지 여부를 판단할 수 없습니다. 예를 들어 깊이 정보를 사용하면 깊이 맵을 직접 확인할 수 있습니다. GPT-4o에 표시되면 깊이 맵을 이해할 수 없기 때문에 판단할 수 없습니다. SpatialBot은 RGB-Depth에 대한 이해를 통해 기계 집게발과 대상 물체의 깊이 값을 정확하게 획득하여 공간 개념에 대한 이해를 생성할 수 있습니다.
포인트 클라우드는 상대적으로 비싸며 쌍안경 카메라는 사용 중에 자주 보정이 필요합니다. 대조적으로, 깊이 카메라는 저렴하고 널리 사용됩니다. 일반적인 시나리오에서는 이러한 하드웨어 장비가 없어도 대규모 비지도 학습 깊이 추정 모델이 이미 상대적으로 정확한 깊이 정보를 제공할 수 있습니다. 따라서 저자는 공간적으로 큰 모델에 대한 입력으로 RGBD를 사용할 것을 제안합니다.
기존 모델은 깊이 맵 입력을 직접 이해할 수 없습니다. 예를 들어, 이미지 인코더 CLIP/SigLIP은 깊이 맵을 보지 않고 RGB 이미지에 대해 학습됩니다.
- 기존의 대규모 모델 데이터 세트 대부분은 RGB만으로 분석 및 답변이 가능합니다. 따라서 기존 데이터를 단순히 RGBD 입력으로 변경하면 모델은 지식을 깊이 맵에 적극적으로 색인화하지 않습니다. 모델이 깊이 맵을 이해하고 깊이 정보를 사용할 수 있도록 안내하려면 특별히 설계된 작업과 QA가 필요합니다.
S SpatialQA의 3단계, 깊이 맵, 깊이 정보의 활용을 이해하도록 모델을 점진적으로 안내합니다 모델이 깊이 정보를 이해하고 사용하며 공간을 이해하도록 안내하는 방법은 무엇입니까? 저자는 세 가지 수준의 SpatialQA 데이터 세트를 제안합니다.
낮은 수준에서는 모델이 깊이 맵을 이해하도록 안내하고 깊이 맵에서 직접 정보를 안내합니다.
-
중간 수준에서는 모델이 깊이를 RGB와 정렬하도록 합니다.
상위 수준에서 다중 깊이 설계 관련 작업의 경우 50k 데이터에 주석이 추가되어 모델이 깊이 정보를 사용하여 깊이 맵 이해를 기반으로 작업을 완료할 수 있습니다. 작업에는 공간 위치 관계, 물체 크기, 물체 접촉 여부, 로봇 장면 이해 등이 포함됩니다.
What does Spatialbot에 포함된 대화 예시?
1. SpatialBot은 에이전트의 아이디어를 바탕으로 필요할 때 API를 통해 정확한 깊이 정보를 얻을 수 있습니다. 깊이 정보 획득, 거리 비교 등의 작업에서 99% 이상의 정확도를 달성할 수 있습니다. 2. 공간 이해 작업을 위해 저자는 SpatialBench 목록을 발표했습니다. 신중하게 설계되고 주석이 달린 QA를 통해 모델의 깊은 이해 능력을 테스트합니다. SpatialBot은 목록에서 GPT-4o에 가까운 기능을 보여줍니다. 1. 모델의 깊이 맵 입력: 실내 및 실외 작업을 고려하려면 통일된 깊이 맵 인코딩 방법이 필요합니다. 실내 잡기 및 탐색 작업에는 밀리미터 수준의 정확도가 필요할 수 있습니다. 실외 장면에서는 그다지 정확할 필요는 없지만 100미터 이상의 깊이 값 범위가 필요할 수 있습니다. 서수 인코딩은 기존 비전 작업의 인코딩에 사용되지만 서수의 값을 더하거나 뺄 수 없습니다. 모든 깊이 정보를 최대한 보존하기 위해 SpatialBot은 uint24 또는 3채널 uint8을 사용하여 1mm에서 131m 범위의 미터법 깊이(밀리미터)를 직접 사용하여 이러한 값을 보존합니다. 2. SpatialBot은 깊이 정보를 정확하게 얻기 위해 필요하다고 판단될 때 DepthAPI를 포인트 형태로 호출하여 정확한 깊이 값을 얻습니다. 객체의 깊이를 얻으려면 SpatialBot은 먼저 객체의 경계 상자를 생각한 다음 경계 상자의 중심점을 사용하여 API를 호출합니다. 3. SpatialBot은 물체의 중심점, 깊이 평균, 최대 및 최소 4가지 값을 사용하여 깊이를 설명합니다. SpatialBot 및 DepthAPI 아키텍처 SpatialBot은 일반 시나리오와 특정 시나리오에서 얼마나 효과적인가요?
1. SpatialBot은 3B에서 8B까지의 다중 기본 LLM을 기반으로 합니다. SpatialQA에서 공간 지식을 학습함으로써 SpatialBot은 일반적으로 사용되는 MLLM 데이터 세트(MME, MMBench 등)에서도 상당한 성능 향상을 보여줍니다. 2. SpatialBot은 Open X-Embodiment와 저자가 수집한 로봇 크롤링 데이터 등 특정 작업에서도 놀라운 결과를 보여주었습니다.
B Spatialbot 일반 시나리오의 데이터 표시 방법 깊이, 거리 관계, 상하, 좌우 전후 위치 관계, 크기 관계 등 공간적 이해에 관한 질문을 세심하게 설계했으며, 두 물체가 안에 있는지 등 구현에 있어서 중요한 문제를 포함합니다. 연락하다.
테스트 세트 SpatialBench에서는 질문, 옵션 및 답변이 먼저 수동으로 고려됩니다. 테스트 세트 크기를 확장하기 위해 동일한 프로세스로 주석을 달기 위해 GPT도 사용됩니다.
훈련 세트 SpatialQA에는 세 가지 측면이 포함됩니다.
깊이 맵을 직접 이해하고, 모델이 깊이 맵을 보고, 깊이 분포를 분석하고, 포함될 수 있는 객체를 추측하도록 합니다.
-
공간 관계 이해 및 추론
-
로봇 장면 이해: Open X-Embodiment의 장면, 포함된 개체 및 가능한 작업과 이 기사에서 수집된 로봇 데이터를 설명하고 개체 및 경계 상자에 수동으로 레이블을 지정합니다. 로봇의.
열기 GPT를 사용하여 데이터의 이 부분에 주석을 달 때 GPT는 먼저 깊이 맵을 보고, 깊이 맵을 설명하고, 포함될 수 있는 장면과 개체에 대한 이유를 설명한 다음 RGB 맵을 확인하여 올바른 설명과 추론을 필터링합니다.
위 내용은 Li Feifei의 '공간 지능' 이후 Shanghai Jiao Tong University, Zhiyuan University, Peking University 등은 대규모 공간 모델 SpatialBot을 제안했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!




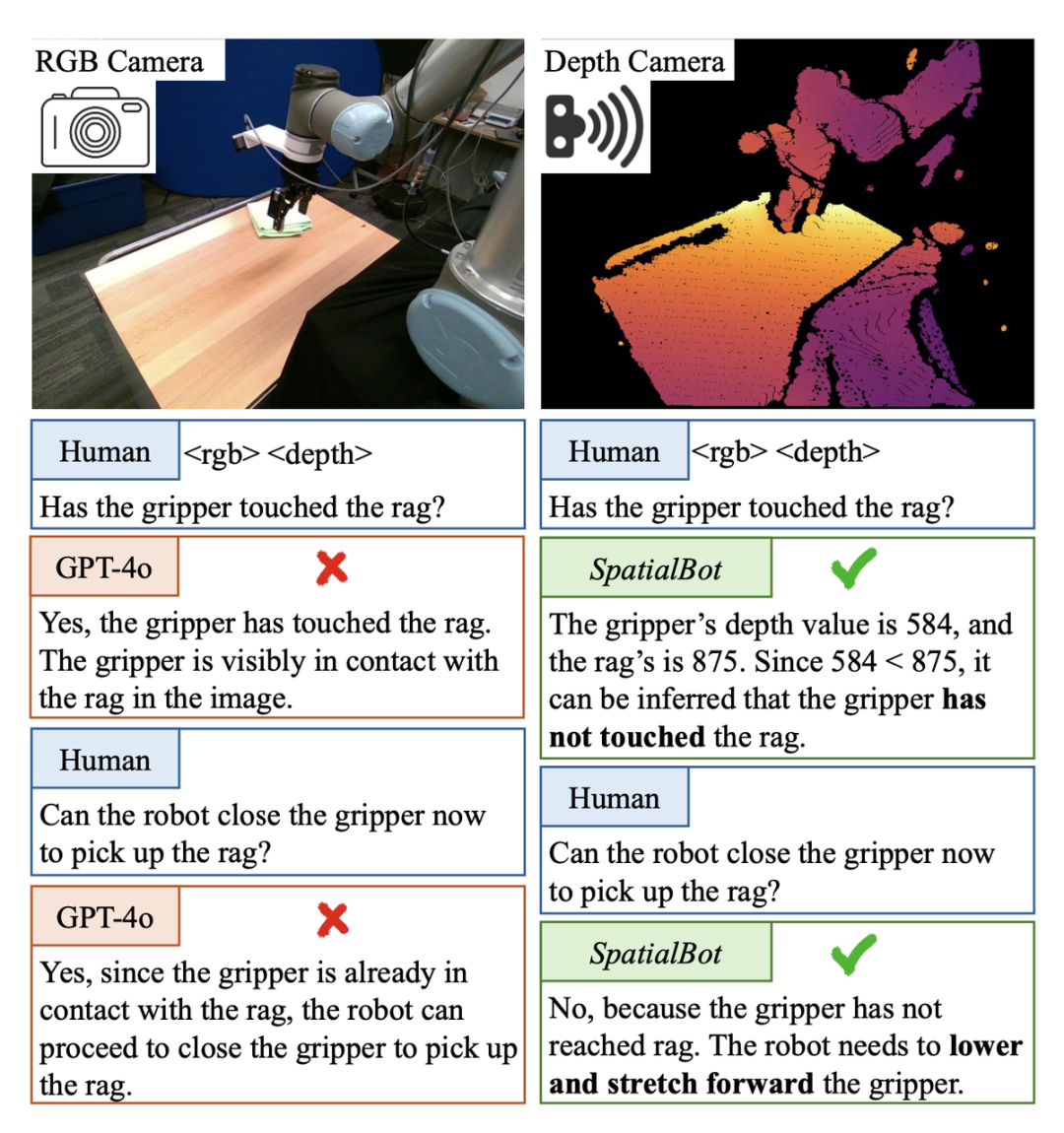
 2. 가운데 찻잔을 잡습니다.
2. 가운데 찻잔을 잡습니다.  구체화된 지능을 향한 필수 경로로서 대형 모델이 공간을 이해하도록 만드는 방법은 무엇입니까?
구체화된 지능을 향한 필수 경로로서 대형 모델이 공간을 이해하도록 만드는 방법은 무엇입니까? 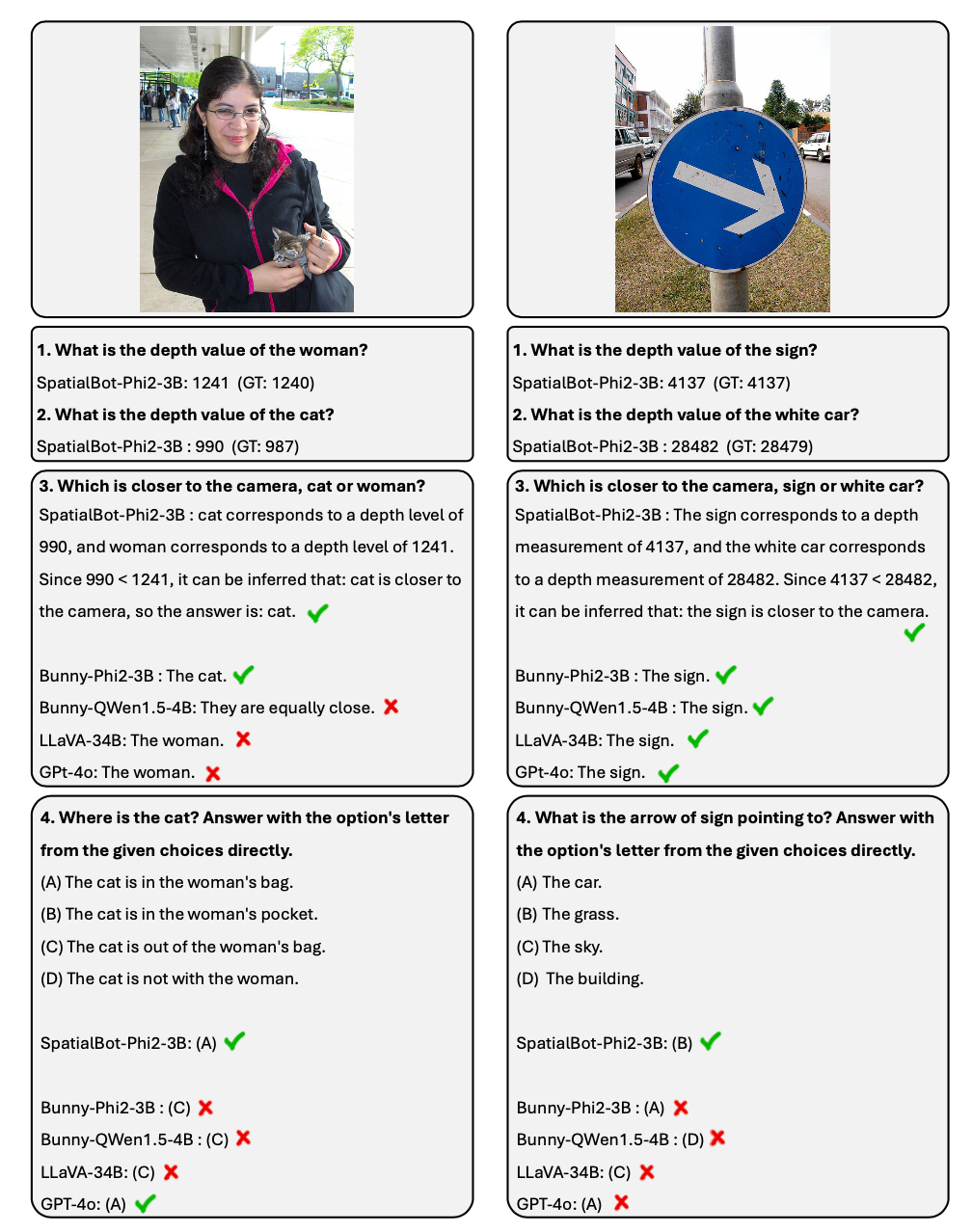



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



