

Die erste simulierte interaktive 3D-Gesellschaft, die speziell für verschiedene Roboter entwickelt wurde.
Erinnern Sie sich an Stanfords KI-Stadt? Dies ist eine virtuelle Umgebung, die von KI-Forschern in Stanford erstellt wurde. In dieser kleinen Stadt leben, arbeiten, knüpfen und verlieben sich ganz normal 25 KI-Agenten. Jeder Agent hat seine eigene Persönlichkeit und Hintergrundgeschichte. Das Verhalten und das Gedächtnis des Agenten werden durch große Sprachmodelle gesteuert, die die Erfahrungen des Agenten speichern und abrufen und auf der Grundlage dieser Erinnerungen Aktionen planen. (Siehe „Stanfords „virtuelle Stadt“ ist Open Source: 25 KI-Agenten erhellen „Westworld““)
In ähnlicher Weise hat kürzlich eine Gruppe von Forschern des Shanghai Artificial Intelligence Laboratory OpenRobotLab und anderer Institutionen eine Gruppe von Forschern hat auch eine virtuelle Stadt geschaffen. Unter ihnen leben jedoch Roboter und NPCs.  Mit 100.000 interaktiven Szenen und 89 verschiedenen Szenenkategorien ist diese Stadt die erste simulierte interaktive 3D-Gesellschaft, die speziell für verschiedene Roboter entwickelt wurde.
Mit 100.000 interaktiven Szenen und 89 verschiedenen Szenenkategorien ist diese Stadt die erste simulierte interaktive 3D-Gesellschaft, die speziell für verschiedene Roboter entwickelt wurde.

Die Autoren gaben an, dass sie diese Umgebung entworfen haben, um das Problem der Datenknappheit im Bereich der verkörperten Intelligenz zu lösen. Wie wir alle wissen, war die Erforschung des Skalierungsgesetzes im Bereich der verkörperten Intelligenz aufgrund der hohen Kosten für die Erhebung realer Daten schwierig. Daher wird das Simulation-to-Real-Paradigma (Sim2Real) zu einem entscheidenden Schritt bei der Erweiterung des verkörperten Modelllernens.
Die virtuelle Umgebung, die sie für Roboter entworfen haben, heißt GRUtopia. Das Projekt umfasst hauptsächlich:
1 Szenendatensatz. Enthält 100.000 interaktive, fein kommentierte Szenen, die frei zu Umgebungen im Stadtmaßstab kombiniert werden können. Im Gegensatz zu früheren Arbeiten, die sich hauptsächlich auf das Zuhause konzentrierten, deckt GRScenes 89 verschiedene Szenenkategorien ab und schließt damit die Lücke in serviceorientierten Umgebungen (in denen Roboter typischerweise zunächst eingesetzt werden).
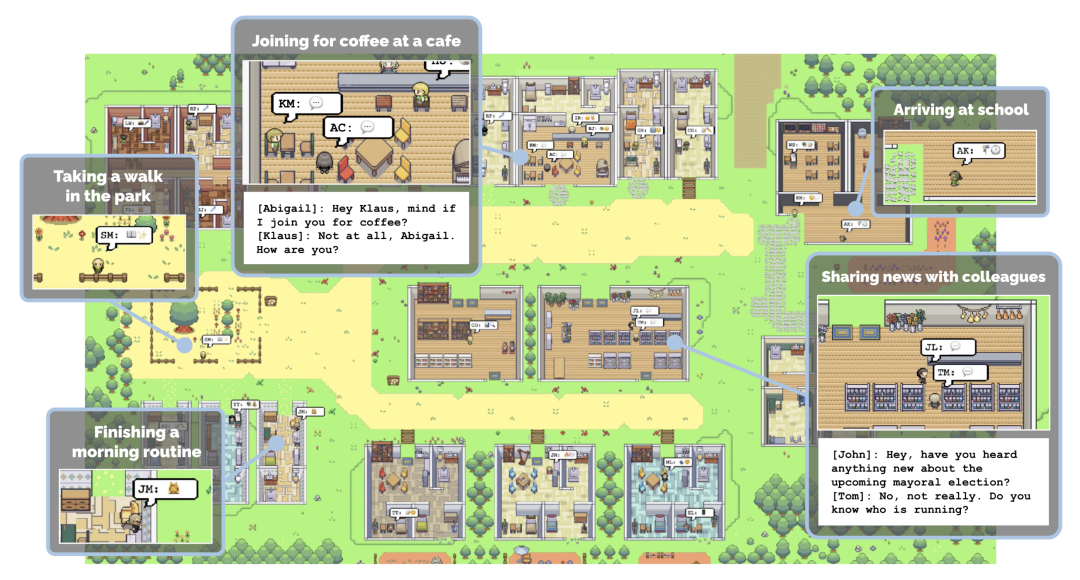
2. GREinwohner. Hierbei handelt es sich um ein durch ein großes Sprachmodell (LLM) gesteuertes Nicht-Spieler-Charaktersystem (NPC), das für soziale Interaktion, Aufgabengenerierung und Aufgabenzuweisung verantwortlich ist und dadurch soziale Szenarien für verkörperte KI-Anwendungen simuliert.
3. Benchmark GRBench. Es werden verschiedene Roboter unterstützt, der Schwerpunkt liegt jedoch auf Beinrobotern als Hauptagenten, und es werden mittelschwere Aufgaben vorgeschlagen, die Objektlokalisierungsnavigation, soziale Lokalisierungsnavigation und Lokalisierungsmanipulation umfassen.
Die Autoren hoffen, dass diese Arbeit den Mangel an qualitativ hochwertigen Daten in diesem Bereich lindern und eine umfassendere Bewertung der verkörperten KI-Forschung ermöglichen wird.

Papiertitel: GRUtopia: Dream General Robots in a City at Scale
Papieradresse: https://arxiv.org/pdf/2407.10943
Projektadresse: https://github .com/OpenRobotLab/GRUtopia
GRScenes: Vollständig interaktive Umgebungen im großen Maßstab
Um eine Plattform für die Schulung und Bewertung verkörperter Agenten aufzubauen, ist eine vollständig interaktive Umgebung mit verschiedenen Szenen- und Objektressourcen ein Muss. Unverzichtbar. Daher haben die Autoren einen großen synthetischen 3D-Szenendatensatz gesammelt, der verschiedene Objektressourcen als Grundlage der GRUtopia-Plattform enthält.
Vielfältige, realistische Szenen
Aufgrund der begrenzten Anzahl und Kategorie von Open-Source-3D-Szenendaten sammelte der Autor zunächst etwa 100.000 hochwertige synthetische Szenen von Designer-Websites, um verschiedene Szenenprototypen zu erhalten. Anschließend bereinigten sie diese Szenenprototypen, kommentierten sie mit Semantik auf Regions- und Objektebene und kombinierten sie schließlich zu Städten, die als grundlegende Spielwiese des Roboters dienten.
Wie in Abbildung 2-(a) gezeigt, enthält der vom Autor erstellte Datensatz zusätzlich zu gewöhnlichen Heimszenen auch 30 % anderer Szenenkategorien, wie z. B. Restaurants, Büros, öffentliche Orte, Hotels, Unterhaltung, usw. Die Autoren überprüften zunächst 100 fein kommentierte Szenen aus einem umfangreichen Datensatz für das Open-Source-Benchmarking. Diese 100 Szenen umfassen 70 Heimszenen und 30 Geschäftsszenen, wobei die Heimszene aus umfassenden Gemeinschaftsbereichen und anderen unterschiedlichen Bereichen besteht und die Geschäftsszenen gängige Typen wie Krankenhäuser, Supermärkte, Restaurants, Schulen, Bibliotheken und Büros abdecken.
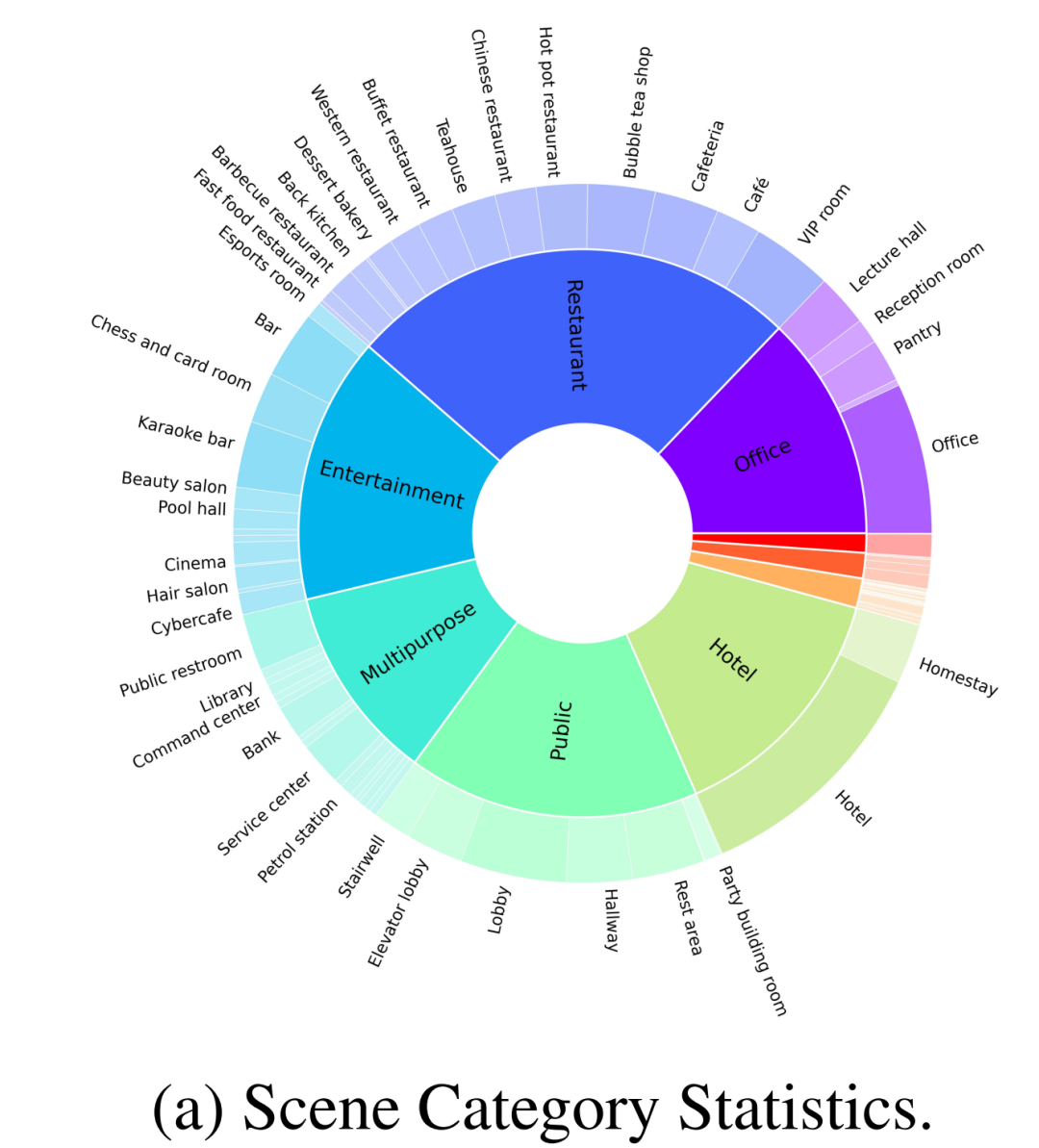
또한 저자는 이전 작품에서 일반적으로 무시되었던 그림 1과 같이 이러한 장면을 더욱 사실적으로 만들기 위해 여러 전문 디자이너와 협력하여 인간의 생활 습관에 따라 개체를 할당했습니다.
부분 수준 주석이 있는 대화형 개체
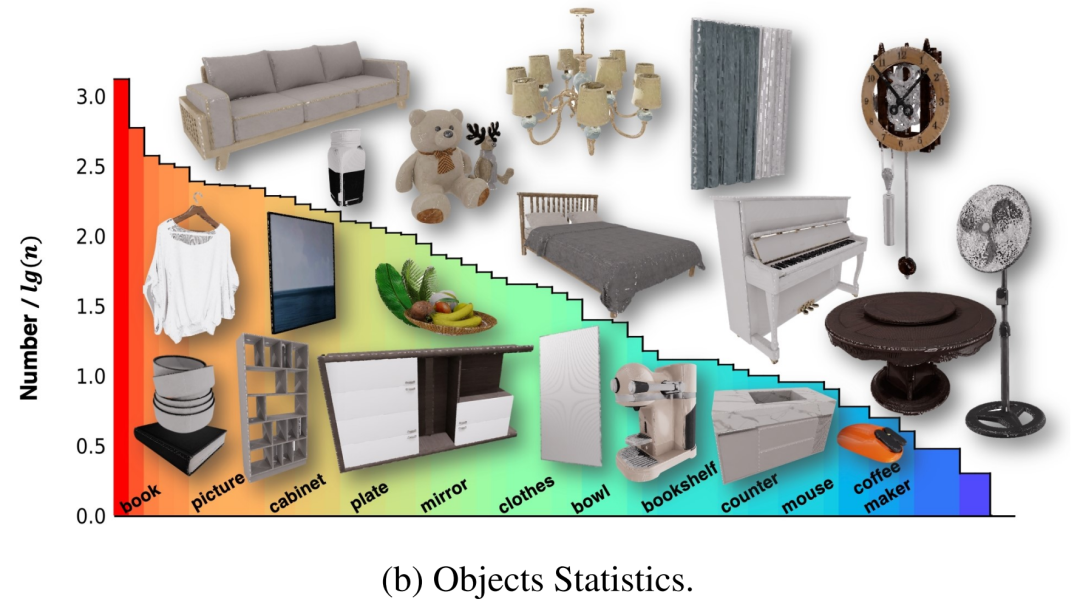
이러한 장면에는 원래 여러 3D 개체가 포함되어 있었지만 일부는 내부적으로 모델링되지 않았기 때문에 로봇이 이러한 개체와 상호 작용하도록 훈련할 수 없었습니다. 이 문제를 해결하기 위해 저자는 전문가 팀과 협력하여 이러한 자산을 수정하고 물리적으로 믿을 수 있는 방식으로 상호 작용할 수 있는 완전한 개체를 만들었습니다. 또한 에이전트가 이러한 자산과 상호 작용할 수 있도록 보다 포괄적인 정보를 제공하기 위해 작성자는 NVIDIA Omniverse에 있는 모든 개체의 대화형 부분에 X 형식의 세밀한 부품 라벨을 첨부했습니다. 마지막으로 100개의 장면에는 96개 범주의 2956개의 대화형 개체와 22001개의 비대화형 개체가 포함되어 있으며 그 분포는 그림 2-(b)에 나와 있습니다.
계층적 다중 모드 주석
마지막으로, 구현된 에이전트와 환경 및 NPC의 다중 모드 상호 작용을 달성하려면 이러한 장면과 객체에도 언어적으로 주석을 달아야 합니다. 객체 수준이나 객체 간의 관계에만 초점을 맞춘 이전 다중 모드 3D 장면 데이터세트와 달리 저자는 객체와 영역 간의 관계와 같은 장면 요소의 다양한 세부사항도 고려했습니다. 지역 레이블이 부족하다는 점을 고려하여 저자는 먼저 장면의 조감도에서 다각형이 있는 지역에 주석을 달기 위한 사용자 인터페이스를 설계했습니다. 그러면 언어 주석에 객체-지역 관계가 포함될 수 있습니다. 각 개체에 대해 렌더링된 다중 뷰 이미지와 함께 강력한 VLM(예: GPT-4v)을 실행하여 주석을 초기화한 다음 사람이 이를 검사합니다. 결과적인 언어 주석은 후속 벤치마크 생성 구현 작업의 기초를 제공합니다.
GRResidents3D 환경 생성 NPC
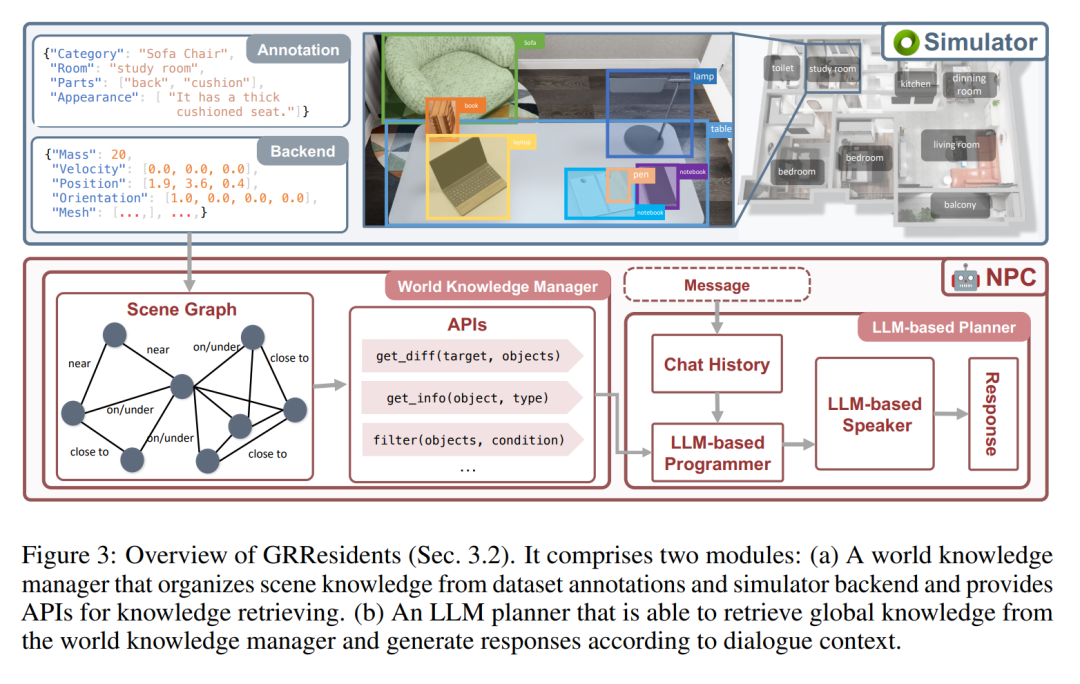
GRUtopia에서 저자는 도시 환경에서 사회적 상호 작용을 시뮬레이션하기 위해 일부 "거주자"(예: LLM이 구동하는 생성 NPC)를 내장하여 전 세계에 사회적 기능을 제공합니다. 이 NPC 시스템의 이름은 GRResidents입니다. 3D 장면에서 사실적인 가상 캐릭터를 구축하는 데 있어 주요 과제 중 하나는 3D 인식 기능을 통합하는 것입니다. 그러나 가상 캐릭터는 장면 주석과 시뮬레이션된 세계의 내부 상태에 쉽게 액세스하여 강력한 인식 기능을 사용할 수 있습니다. 이를 위해 저자는 실시간 세계 상태에 대한 동적 지식을 관리하고 일련의 데이터 인터페이스를 통해 액세스를 제공하는 WKM(World Knowledge Manager)을 설계했습니다. WKM을 사용하면 NPC는 필요한 지식을 검색하고 지각 능력의 핵심을 형성하는 매개변수화된 함수 호출을 통해 세분화된 객체 기반을 수행할 수 있습니다.
World Knowledge Manager(WKM)
WKM의 주요 업무는 가상 환경 지식을 지속적으로 관리하고 NPC에게 고급 현장 지식을 제공하는 것입니다. 특히 WKM은 데이터 세트와 시뮬레이터 백엔드에서 각각 계층적 주석과 장면 지식을 얻고 장면 표현으로 장면 그래프를 구성합니다. 여기서 각 노드는 객체 인스턴스를 나타내고 가장자리는 객체 간의 공간 관계를 나타냅니다. 저자는 Sr3D에서 정의된 공간 관계를 관계 공간으로 채택했습니다. WKM은 각 시뮬레이션 단계에서 이 장면 그래프를 유지합니다. 또한 WKM은 장면 그래프에서 지식을 추출하기 위한 세 가지 핵심 데이터 인터페이스도 제공합니다.
1, find_diff(대상, 객체): 대상 객체와 다른 객체 집합 간의 차이를 비교합니다.
2, get_info(객체, 유형): 필수 속성 유형에 따라 객체 지식을 얻습니다.
3. 필터(객체, 조건):: 조건에 따라 객체를 필터링합니다.
LLM Planner
NPC의 의사결정 모듈은 세 부분으로 구성된 LLM 기반 플래너입니다(그림 3). NPC와 다른 에이전트 간의 채팅 기록을 저장하는 데 사용되는 저장 모듈 LLM 프로그래머가 인터페이스를 사용합니다. WKM은 장면 지식을 쿼리하고 LLM 스피커는 채팅 기록과 쿼리된 지식을 소화하여 응답을 생성하는 데 사용됩니다. NPC가 메시지를 받으면 먼저 메시지를 메모리에 저장한 다음 업데이트된 기록을 LLM 프로그래머에게 전달합니다. 그런 다음 프로그래머는 필요한 장면 지식을 쿼리하기 위해 데이터 인터페이스를 반복적으로 호출합니다. 마지막으로 지식과 이력이 LLM 발표자에게 전송되어 응답이 생성됩니다.
Experiments
저자는 논문 속 NPC가 객체 설명을 생성하고, 설명을 통해 객체를 찾고, 지능형 제공을 제공할 수 있음을 증명하기 위해 객체 참조, 언어 접지 및 객체 중심 QA에 대한 실험을 수행했습니다. 정보. 이 실험의 NPC 백엔드 LLM에는 GPT-4o, InternLM2-Chat-20B 및 Llama-3-70BInstruct가 포함됩니다.
그림 4에 표시된 것처럼 참조 실험에서 저자는 Human-In-The-Loop 평가를 사용했습니다. NPC는 무작위로 객체를 선택하여 설명하고, 인간 주석자는 설명을 바탕으로 객체를 선택합니다. 사람 주석자가 설명에 해당하는 올바른 객체를 찾을 수 있으면 참조가 성공한 것입니다. 접지 실험에서 GPT-4o는 NPC가 배치한 물체에 대한 설명을 제공하는 인간 주석자 역할을 했습니다. NPC가 해당 물체를 찾을 수 있으면 접지에 성공한 것입니다.
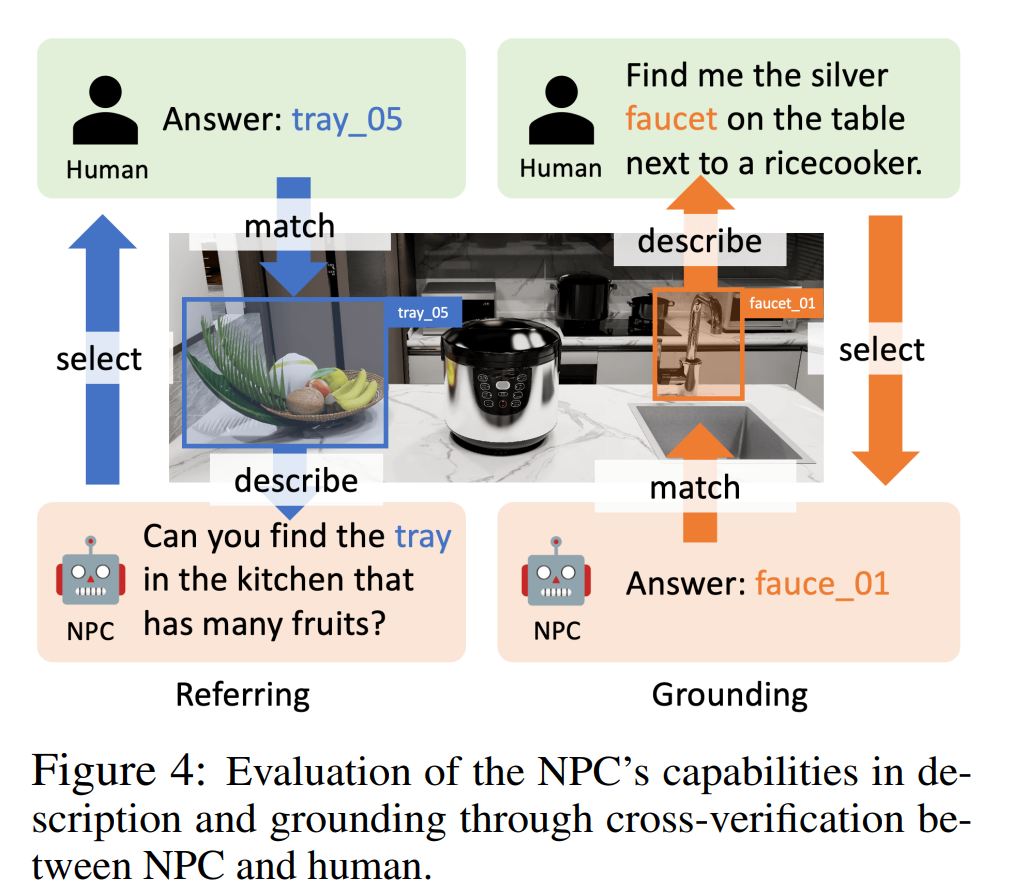
표 2의 성공률(참조 및 접지)은 다양한 LLM의 정확도가 각각 95.9%-100% 및 83.3%-93.2%임을 보여주며, 이는 NPC 프레임워크가 다른 LLM을 참조할 수 있음을 확인합니다. 접지 정확도.
객체 중심 QA 실험에서 저자는 탐색 작업의 질문에 답하여 객체 수준 정보를 에이전트에 제공하는 NPC의 능력을 평가했습니다. 그들은 실제 시나리오를 시뮬레이션하는 객체 중심 탐색 플롯을 생성하는 파이프라인을 설계했습니다. 이러한 시나리오에서 에이전트는 정보를 얻기 위해 NPC에게 질문을 하고 답변에 따라 조치를 취합니다. 에이전트 질문이 주어지면 저자는 답변과 실제 답변 간의 의미적 유사성을 기반으로 NPC를 평가합니다. 표 2(QA)에 표시된 전체 점수는 NPC가 정확하고 유용한 탐색 지원을 제공할 수 있음을 나타냅니다.
GRBench: 구현된 에이전트 평가를 위한 벤치마크
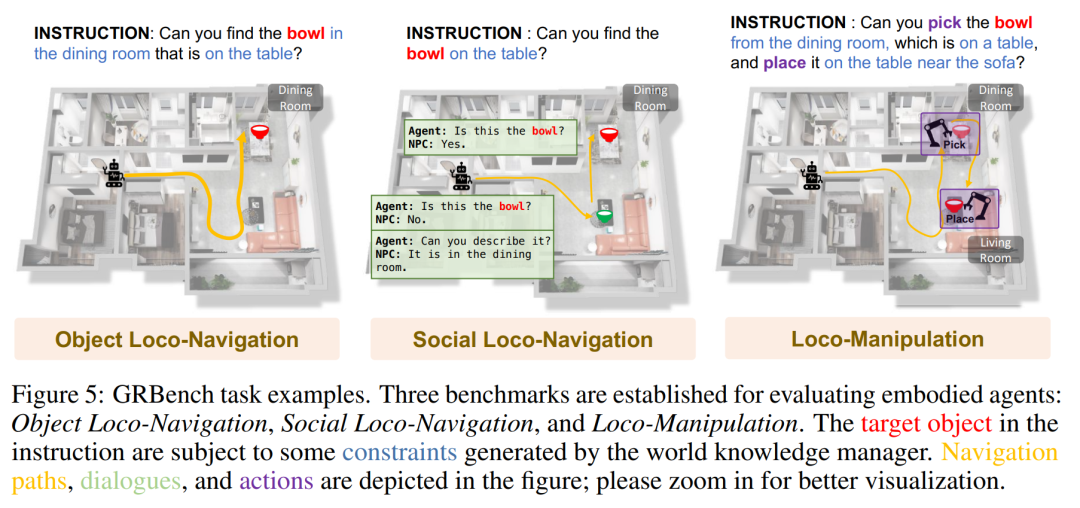
GRBench는 로봇 에이전트의 기능을 평가하기 위한 포괄적인 평가 도구입니다. 일상적인 작업을 처리하는 로봇 에이전트의 능력을 평가하기 위해 GRBench에는 객체 현지화 탐색, 소셜 현지화 탐색 및 현지화 작업이라는 세 가지 벤치마크가 포함되어 있습니다. 이러한 벤치마크의 난이도는 점차 증가하고 이에 따라 로봇 기술에 대한 요구 사항도 증가합니다.
다리 로봇의 뛰어난 지형 횡단 능력으로 인해 저자는 이를 주체로 우선시합니다. 그러나 대규모 시나리오에서는 현재 알고리즘이 높은 수준의 인식, 계획 및 낮은 수준의 제어를 동시에 수행하고 만족스러운 결과를 얻는 것이 어렵습니다.
GRBench의 최신 발전은 시뮬레이션에서 단일 기술에 대한 고정밀 정책 교육의 타당성을 입증했습니다. 이에 영감을 받아 GRBench의 초기 버전은 높은 수준의 작업에 중점을 두고 다음과 같은 학습 기반 제어 전략을 API로 제공합니다. 걷기와 선택 및 배치. 결과적으로 벤치마크는 시뮬레이션과 실제 세계 사이의 격차를 해소하면서 보다 현실적인 물리적 환경을 제공합니다.
아래 그림은 GRBench의 작업 예시입니다.
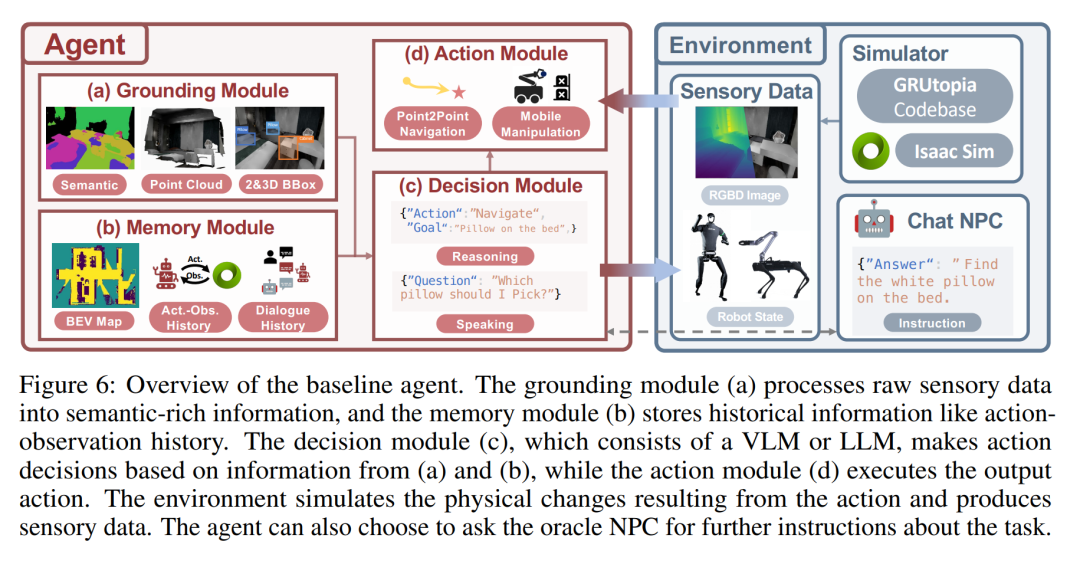
다음 그림은 기준 에이전트의 개요입니다. 접지 모듈(a)은 원시 감각 데이터를 의미가 풍부한 정보로 처리하고, 메모리 모듈(b)은 행동 관찰 기록과 같은 기록 정보를 저장합니다. 결정 모듈(c)는 VLM 또는 LLM으로 구성되며 (a)와 (b)의 정보를 기반으로 조치 결정을 내리고, 조치 모듈(d)는 출력 조치를 실행합니다. 환경은 행동으로 인한 물리적 변화를 시뮬레이션하고 감각 데이터를 생성합니다. 에이전트는 고문 NPC에게 작업에 대한 추가 지침을 요청할 수 있습니다.
정량적 평가 결과
저자는 세 번의 벤치마크 테스트를 통해 다양한 대형 모델 백엔드에서 대형 모델 기반 에이전트 프레임워크를 비교 분석했습니다. 표 4에서 볼 수 있듯이 무작위 전략의 성능은 0에 가까워 작업이 간단하지 않음을 나타냅니다. 상대적으로 우수한 대형 모델을 백엔드로 사용할 때 세 가지 벤치마크 모두에서 전반적인 성능이 크게 향상되는 것으로 나타났습니다. Qwen이 대화에서 GPT-4o보다 더 나은 성능을 발휘한다는 것을 관찰했다는 점은 언급할 가치가 있습니다(표 5 참조).
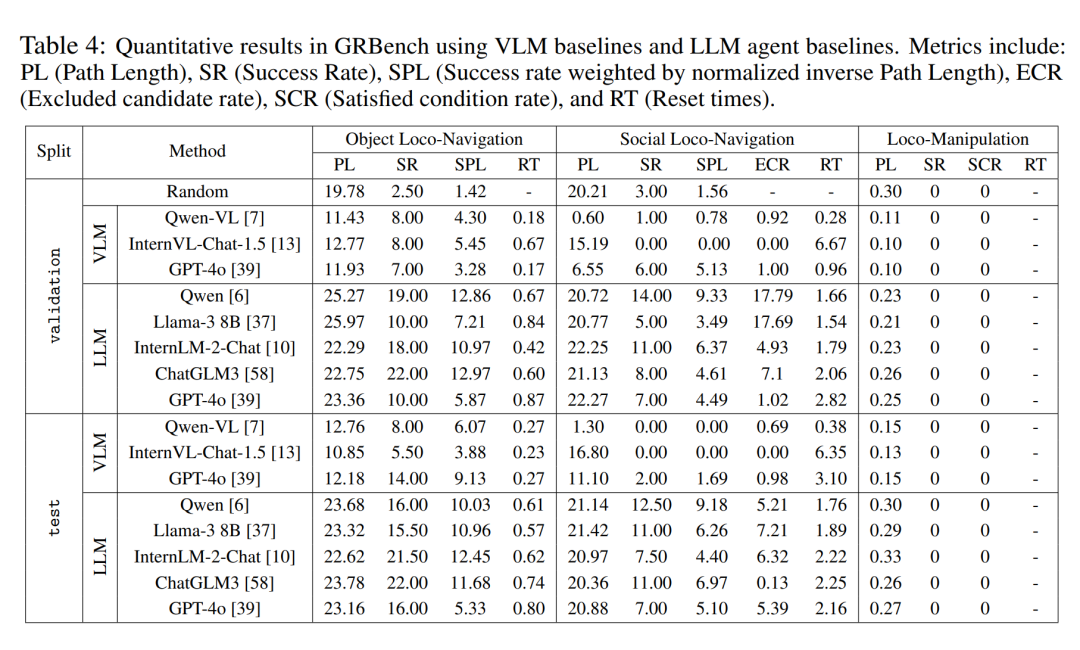

또한 의사결정을 위해 다중 모달 대형 모델을 직접 사용하는 것과 비교하여 본 기사에서 제안하는 에이전트 프레임워크는 명백한 우수성을 보여줍니다. 이는 현재의 최첨단 다중 모드 대규모 모델에도 실제 구현 작업에 대한 강력한 일반화 기능이 부족하다는 것을 보여줍니다. 그러나 이 문서의 방법에도 개선의 여지가 상당히 많습니다. 이는 내비게이션과 같이 수년간 연구된 과제라 할지라도 현실 세계에 가까운 과제 설정이 도입되면 여전히 완전히 해결되기는 어렵다는 것을 보여줍니다.
정성평가 결과
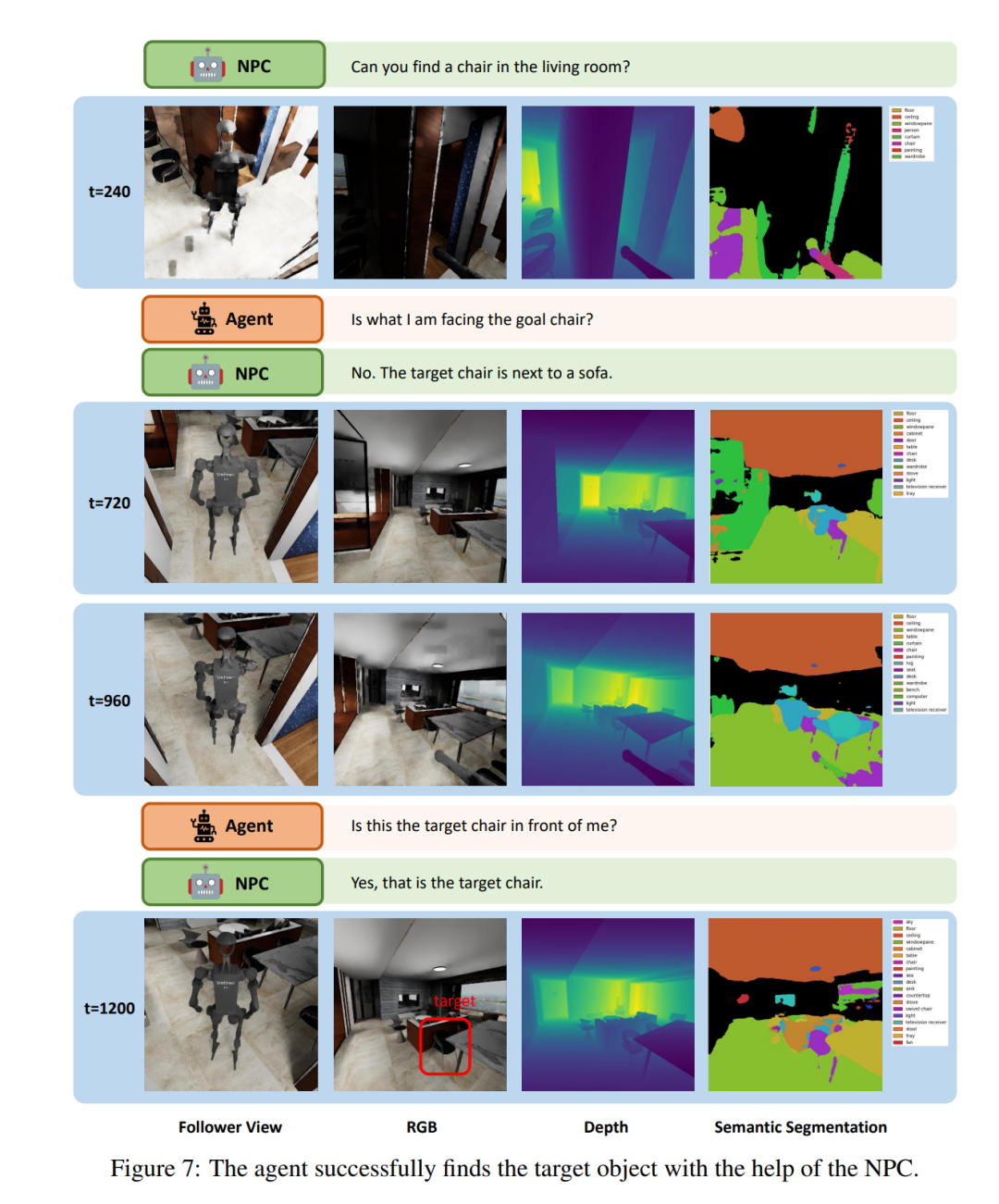
그림 7은 에이전트가 NPC와 상호 작용하는 방식을 설명하기 위해 "Social Loco-Navigation" 작업에서 LLM 에이전트가 수행하는 작은 조각을 보여줍니다. 에이전트는 더 많은 작업 정보를 쿼리하기 위해 NPC와 최대 3번까지 대화할 수 있습니다. t = 240에서 에이전트는 의자로 이동하여 이 의자가 대상 의자인지 NPC에게 묻습니다. 그런 다음 NPC는 모호성을 줄이기 위해 대상에 대한 주변 정보를 제공합니다. NPC의 도움으로 에이전트는 인간의 행동과 유사한 상호작용 과정을 통해 타겟 의자를 식별하는 데 성공했습니다. 이는 본 논문의 NPC가 인간-로봇 상호 작용 및 협업을 연구하기 위한 자연스러운 사회적 상호 작용을 제공할 수 있음을 보여줍니다.
위 내용은 구체화된 지능 연구를 위해 특별히 제작된 로봇 버전 '스탠포드 타운'이 여기에 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



