

판이첸: 저장대학교 석사 1년차 학생입니다. Kong Dehan: Cross Star Technology의 모델 알고리즘 책임자. Zhou Sida: 2024년 난창대학교를 졸업한 그는 시안전자과학기술대학교에서 석사 학위 과정을 공부할 예정입니다. 추이 쳉(Cui Cheng): 2024년 절강 중의약대학교를 졸업한 그는 쑤저우대학교에서 석사 학위를 취득할 예정입니다.
Pan Yichen, Zhou Sida 및 Cui Cheng은 Cross Star Technology의 알고리즘 인턴으로 공동으로 이 논문의 연구 작업을 완료했습니다.
오늘날 급속한 기술 발전 시대에 LLM(대형 언어 모델)은 우리가 디지털 세계와 상호 작용하는 방식을 전례 없는 속도로 변화시키고 있습니다. LLM 기반 지능형 에이전트(LLM Agent)는 단순한 정보 검색부터 복잡한 웹 페이지 운영까지 점차 우리 생활에 통합되고 있습니다. 그러나 중요한 질문은 여전히 열려 있습니다. 이 LLM 에이전트가 실제 온라인 네트워크 세계에 들어서면 기대한 만큼 성과를 낼 수 있을까요?
기존 평가 방법의 대부분은 정적 데이터 세트 또는 시뮬레이션된 웹 사이트 수준에 남아 있습니다. 이러한 방법에는 가치가 있지만 한계는 분명합니다. 정적 데이터 세트는 인터페이스 업데이트 및 콘텐츠 반복과 같은 웹 환경의 동적 변화를 포착하기 어렵습니다. 시뮬레이션된 웹 사이트는 실제 세계의 복잡성이 부족하고 크로스 사이트를 완전히 고려하지 못합니다. 검색 엔진 사용 및 기타 작업과 같은 작업에는 이러한 요소가 실제 환경에 없어서는 안 될 요소입니다.
이 문제를 해결하기 위해 "WebCanvas: 온라인 환경에서 웹 에이전트 벤치마킹
"이라는 제목의 논문에서는 실제 온라인 세계에서 에이전트의 성능을 벤치마킹하는 것을 목표로 하는 혁신적인 온라인 평가 프레임워크인 WebCanvas를 제안했습니다. 접근하다.

문서 링크: https://arxiv.org/pdf/2406.12373
WebCanvas 플랫폼 링크: https://imean.ai/web-canvas
프로젝트 코드 링크: https: //github.com/iMeanAI/WebCanvas
Dataset 링크: https://huggingface.co/datasets/iMeanAI/Mind2Web-Live
WebCanvas의 혁신 중 하나는 "키 노드" 개념의 제안입니다. . 이 개념은 작업의 최종 완료에만 초점을 맞추는 것이 아니라 평가의 정확성을 보장하기 위해 작업 실행 프로세스의 세부 사항까지 자세히 설명합니다. WebCanvas는 특정 웹 페이지에 도달하거나 특정 작업(예: 특정 버튼 클릭)을 수행하는지 여부에 관계없이 작업 흐름의 주요 노드를 식별하고 감지하여 에이전트의 온라인 평가에 대한 새로운 관점을 제공합니다.

WebCanvas 프레임 다이어그램. 왼쪽은 과제의 라벨링 과정을 나타내고, 오른쪽은 과제 평가 과정을 나타낸다. WebCanvas는 온라인 네트워크 상호 작용에서 작업 경로의 비고유성을 고려하며 "트로피"는 각 핵심 노드에 성공적으로 도달한 후 얻은 단계 점수를 나타냅니다.
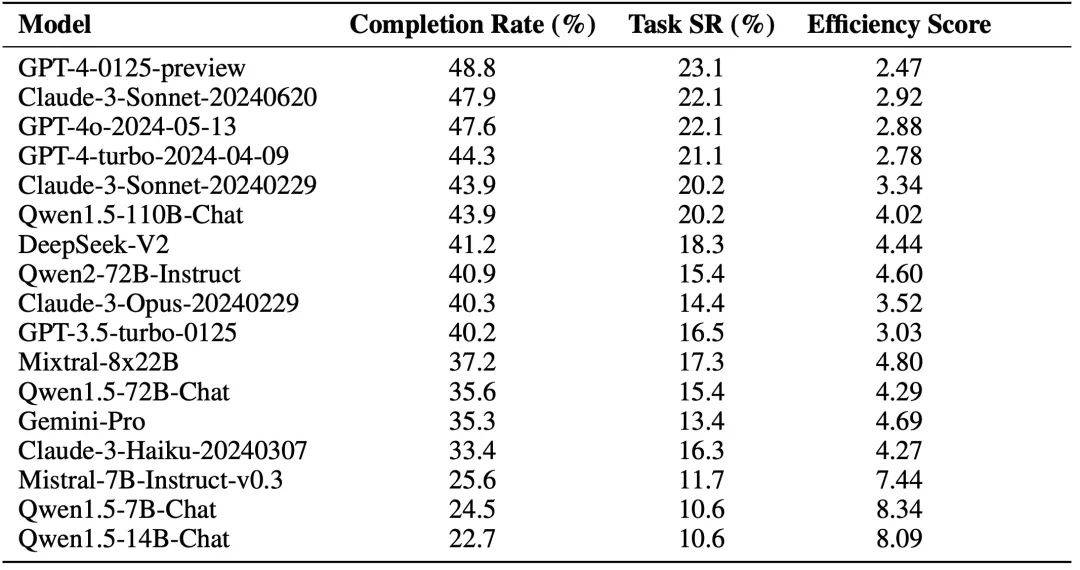
WebCanvas 프레임워크를 기반으로 저자는 Mind2Web에서 무작위로 선택된 542개의 작업이 포함된 Mind2Web-Live 데이터 세트를 구성했습니다. 이 기사의 작성자는 데이터 세트의 각 작업에 대한 주요 노드에도 주석을 달았습니다. 일련의 실험을 통해 에이전트에 메모리 모듈을 장착하고 ReAct 추론 프레임워크를 보완하며 GPT-4-turbo 모델을 장착하면 작업 성공률이 23.1%로 증가하는 것으로 나타났습니다. 우리는 지속적인 기술 발전으로 인해 웹 에이전트의 잠재력은 여전히 무한하며, 곧 이 숫자를 초과하게 될 것이라고 굳게 믿습니다.
키 노드
"키 노드" 개념은 WebCanvas의 핵심 아이디어 중 하나입니다. 핵심 노드는 특정 네트워크 작업을 완료하는 데 없어서는 안 될 단계를 의미합니다. 즉, 이러한 단계는 작업을 완료하는 경로에 관계없이 필수입니다. 이러한 단계는 특정 웹페이지를 방문하는 것부터 양식 작성, 버튼 클릭 등 페이지에서 특정 작업을 수행하는 것까지 다양합니다.
WebCanvas 프레임의 녹색 부분을 예로 들면, 사용자는 Rotten Tomatoes 웹사이트에서 가장 높은 평가를 받은 개봉 예정 모험 영화를 찾아야 합니다. 그는 Rotten Tomatoes 홈 페이지에서 시작하거나 검색 엔진의 "예정된 영화" 페이지를 직접 타겟팅하는 등 다양한 방법으로 이를 수행할 수 있습니다. 동영상을 필터링할 때 사용자는 먼저 '어드벤처' 장르를 선택한 다음 인기순으로 정렬하거나 그 반대로 정렬할 수 있습니다. 목표를 달성하는 데는 여러 가지 경로가 있지만 특정 페이지로 이동하여 이를 필터링하는 것은 작업을 완료하는 데 있어 필수적인 단계입니다. 따라서 이 세 가지 작업은 이 작업의 중요한 노드로 정의됩니다.
평가 지표
WebCanvas의 평가 시스템은 단계 점수와 작업 점수의 두 부분으로 나누어져 있으며, 이는 WebAgent의 종합적인 기능을 함께 평가하는 것입니다.
단계 점수: 키 노드에서 에이전트의 성능을 측정합니다. 각 키 노드는 세 가지 평가 대상(URL, 요소 경로, 요소 값)과 세 가지 일치 기능(정확, 포함, 의미)을 통해 평가 기능과 연결됩니다. ) 달성합니다. 핵심 노드에 도달하고 평가 기능을 통과할 때마다 에이전트는 해당 점수를 얻을 수 있습니다.

Overview of evaluation functions, where E represents the web element Element
Task score: divided into task completion score and efficiency score. The task completion score reflects whether the Agent successfully obtained all step scores for this task. The efficiency score considers the resource utilization of task execution and is calculated as the average number of steps required to score each step.
Mind2Web-Live Dataset
The author randomly selected 601 time-independent tasks from the Mind2Web training set and 179 equally time-independent tasks from the Cross-task subset of the test set, and then combined these Tasks are annotated in real online environments. Finally, the author constructed a Mind2Web-Live dataset consisting of 542 tasks, including 438 training samples and 104 samples for testing. The figure below visually shows the distribution of annotation results and evaluation functions.

Data annotation tool
During the data annotation process, the author used the iMean Builder browser plug-in developed by Chuanxingkong Technology. This plug-in can record user browser interaction behaviors, including but not limited to clicks, text input, hovering, dragging and other actions. It also records the specific type of operation, execution parameters, Selector path of the target element, as well as element content and page coordinate position. In addition, iMean Builder also generates web page screenshots for each step of the operation, providing an intuitive display of the verification and maintenance workflow.
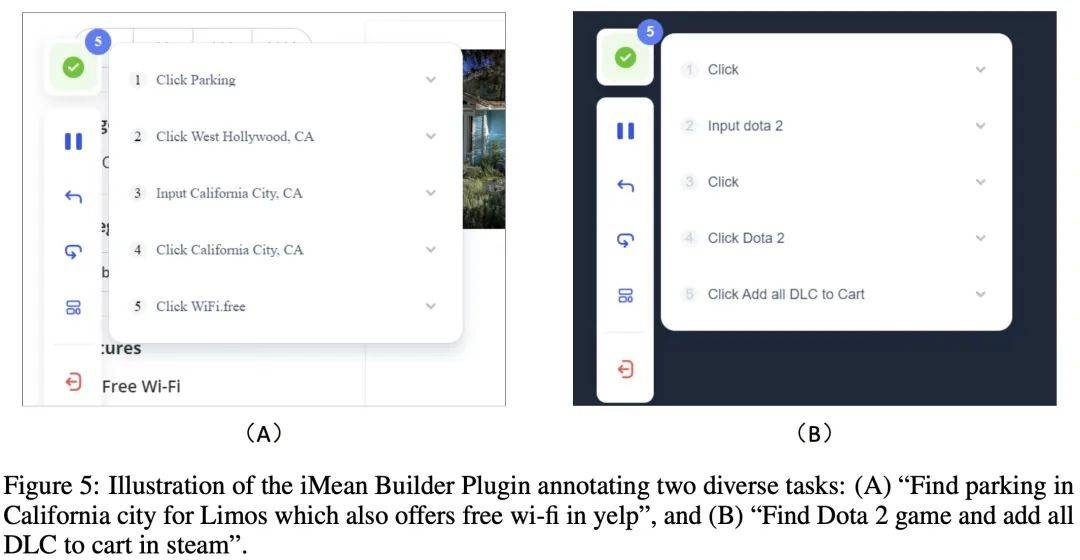
Example: Annotating two different tasks using the iMean Builder plugin. (A) Find limousine parking lots in California that offer free Wi-Fi on Yelp, (B) Find the Dota 2 game on Steam and add all DLC to your shopping cart
Data maintenance
The network environment is changing rapidly , website content updates, user interface adjustments and even site closures are inevitable and normal. These changes may cause previously defined tasks or key nodes to lose their timeliness, thereby affecting the validity and fairness of the evaluation.
To this end, the author has designed a data maintenance plan aimed at ensuring the continued relevance and accuracy of the evaluation set. In the data collection phase, in addition to marking key nodes, the iMean Builder plug-in can also record detailed information on each step of the workflow execution, including action type, Selector path, element value, coordinate position, etc. Subsequent use of the iMean Replay SDK's element matching strategy can reproduce workflow actions and promptly detect and report any invalid conditions in the workflow or evaluation function.
Through this solution, we effectively solve the challenges caused by process failures, ensure that the evaluation data set can adapt to the continuous evolution of the online world, and provide a solid foundation for the ability of automated evaluation Agents.
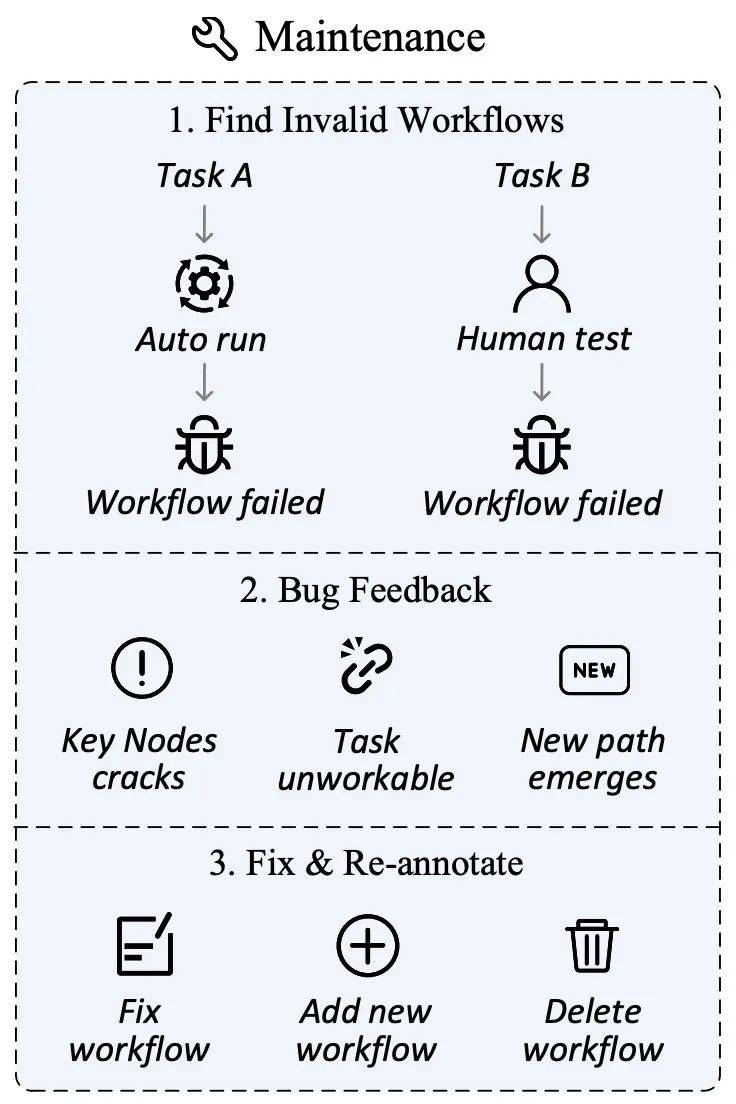
Data Management Platform
On the WebCanvas website, users can clearly browse all recorded task processes and their key nodes, and can also quickly feedback failed processes to the platform administrator to ensure the timeliness of data and accuracy.
At the same time, the author encourages community members to actively participate and jointly build a good ecosystem. Whether it's maintaining the integrity of existing data, developing more advanced agents for testing, or even creating entirely new datasets, WebCanvas welcomes contributions of all kinds. This not only promotes the improvement of data quality, but also encourages technological innovation, which can form a virtuous cycle to promote the development of the entire field.
WebCanvas Homepage
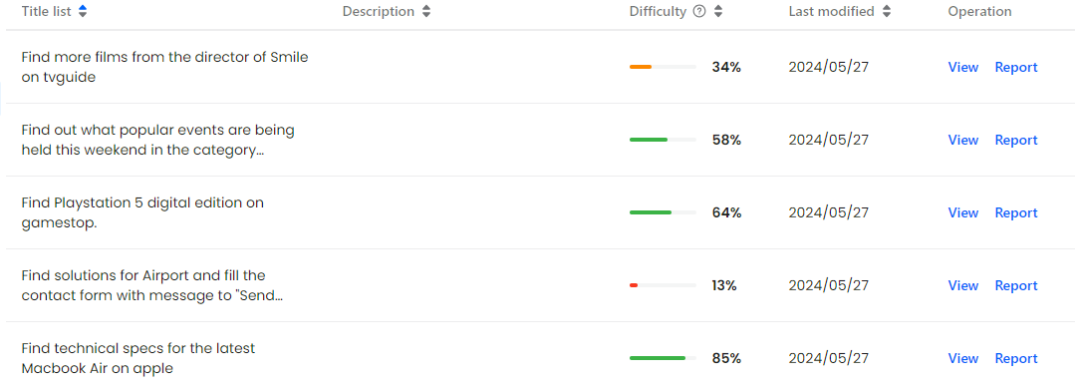
Visual display of Mind2Web-Live dataset
Basic Agent Framework
The author has built a comprehensive Agent framework designed to optimize Agents in online networks task execution efficiency in the environment. The framework is mainly composed of four key components: Planning, Observation, Memory and Reward modules.
Planning: Based on the input of Accessibility Tree, the Planning module uses the ReAct reasoning framework to perform logical inference and generate specific operation instructions. The core function of this module is to give action paths based on the current status and task goals.
Observation: Agent parses the HTML source code provided by the browser and converts it into an Accessibility Tree structure. This process ensures that the Agent can receive web page information in a standardized format for subsequent analysis and decision-making.
Memory: The Memory module is responsible for storing the Agent’s historical data during task execution, including but not limited to the Agent’s thinking process, past decisions, etc.
Reward: The Reward module can evaluate the Agent's behavior, including feedback on the quality of decision-making and giving task completion signals.

Schematic diagram of the basic Agent framework
Main experiments
The author uses the basic Agent framework and accesses different LLMs for evaluation (excluding Reward module). The experimental results are shown in the figure below, where Completion Rate refers to the achievement rate of key nodes, and Task Success Rate refers to the task success rate.

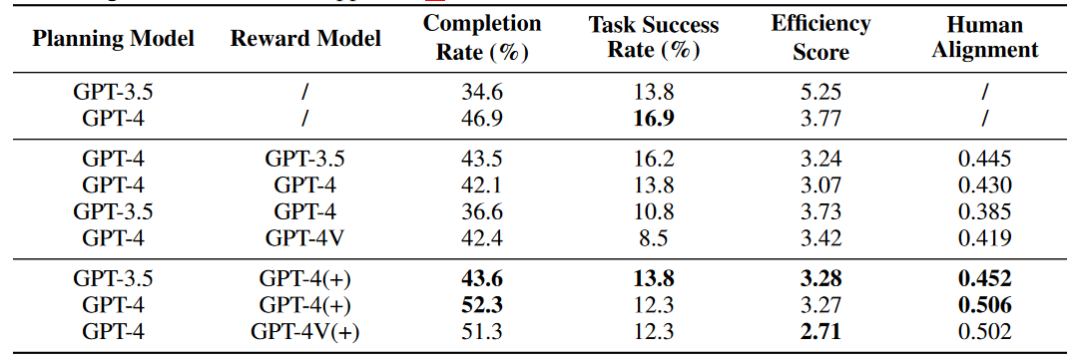
In addition, the author also explored the impact of the Reward module on the Agent's ability. The (+) sign represents that the Reward information contains human annotation data and key node information for the Agent's reference, and the Human Alignment score represents How aligned the agent is with humans. The results of preliminary experiments show that in an online network environment, Agent cannot improve its capabilities through the Self Reward module, but the Reward module that integrates the original annotation data can enhance the Agent's capabilities.
Experimental analysis
In the appendix, the author analyzes the experimental results. The following figure is the relationship between task complexity and task difficulty. The orange line depicts the key node achievement rate with task complexity. The trajectory of increasing changes, while the blue line reflects the trajectory of task success rate with task complexity.
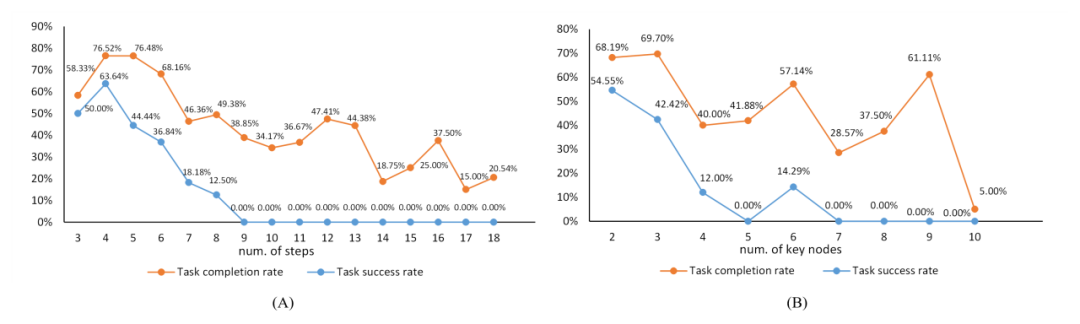
The relationship between task complexity and task difficulty. "num of steps" refers to the length of the action sequence in the annotated data, which together with the number of key nodes serves as a reference for task complexity.
The following table shows the relationship between the experimental results and regions, equipment, and systems.

Summary
On the journey to promote the development of LLM and Agent technology, it is crucial to build an evaluation system that adapts to the real network environment. This article focuses on effectively evaluating Agent performance in the rapidly changing Internet world. We faced the challenge head-on and achieved this goal by defining key nodes and corresponding evaluation functions in an open environment, and developed a data maintenance system to reduce subsequent maintenance costs.
Through unremitting efforts, we have taken substantial steps towards establishing a robust and accurate online evaluation system. However, conducting reviews in dynamic cyberspace is not easy, and it introduces a series of complex issues not encountered in closed, offline scenarios. During the evaluation of the Agent, we encountered difficulties such as unstable network connections, restricted website access, and limitations of the evaluation functions. These problems highlight the arduous task of evaluating Agents in complex real-world environments, requiring us to continuously refine and adjust the Agent's reasoning and evaluation framework.
We call on the entire scientific research community to work together to cope with unknown challenges and promote the innovation and improvement of evaluation technology. We firmly believe that only through continued research and practice can these obstacles be gradually overcome. We look forward to working hand in hand with our peers to create a new era of LLM Agent.
위 내용은 Agent의 실제 성능을 효과적으로 평가하기 위해 새로운 온라인 평가 프레임워크인 WebCanvas가 출시되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



