
AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
최근에는 다양한 분야에서 MLLM(Multimodal Large Language Model)을 적용하는 것이 눈부신 성공을 거두었습니다. 그러나 많은 다운스트림 작업의 기본 모델로서 현재 MLLM은 덜 효율적인 2차 계산 복잡성을 갖는 잘 알려진 Transformer 네트워크로 구성됩니다. 이러한 기본 모델의 효율성을 향상시키기 위해 많은 실험을 통해 다음과 같은 사실을 알 수 있습니다. (1) Cobra는 계산 효율성이 높은 현재의 최첨단 방법(예: LLaVA-Phi, TinyLLaVA)과 매우 경쟁력 있는 성능을 가지고 있습니다. 및 MobileVLM v2), Cobra 선형 시퀀스 모델링으로 인해 더 빠릅니다. (2) 흥미롭게도 폐쇄형 도전적 예측 벤치마크의 결과는 Cobra가 시각적 환상을 극복하고 공간적 관계 판단을 잘 수행한다는 것을 보여줍니다. (3) Cobra는 매개변수 수가 LLaVA의 약 43%에 불과한 경우에도 LLaVA와 비슷한 성능을 달성한다는 점에 주목할 가치가 있습니다. 대형 언어 모델(LLM)은 언어를 통해서만 상호 작용하는 것으로 제한되어 더 다양한 작업을 처리하기 위한 적응성이 제한됩니다. 실제 문제를 효과적으로 해결하는 모델의 능력을 향상하려면 다중 모드 이해가 중요합니다. 따라서 연구자들은 다중 모드 정보 처리 기능을 통합하기 위해 대규모 언어 모델을 확장하기 위해 적극적으로 노력하고 있습니다. GPT-4, LLaMA-Adapter 및 LLaVA와 같은 VLM(시각 언어 모델)은 LLM의 시각적 이해 기능을 향상시키기 위해 개발되었습니다. 그러나 이전 연구에서는 주로 유사한 방식으로 효율적인 VLM을 얻으려고 노력했습니다. 즉, 어텐션 기반 Transformer 구조를 변경하지 않고 기본 언어 모델의 매개변수나 시각적 토큰 수를 줄이는 것입니다. 본 논문에서는 상태 공간 모델(SSM)을 백본 네트워크로 직접 사용하여 선형 계산 복잡도를 갖는 MLLM을 얻는 다른 관점을 제안합니다. 또한 본 논문에서는 효과적인 다중 모드 Mamba를 생성하기 위해 다양한 모드 융합 방식을 탐색하고 연구합니다. 구체적으로 본 논문에서는 VLM의 기본 모델로 Mamba 언어 모델을 채택했는데, 이는 Transformer 언어 모델과 경쟁할 수 있으면서도 추론 효율이 더 높은 성능을 보여주었다. 테스트 결과 Cobra의 추론 성능은 동일한 매개변수 규모의 MobileVLM v2 3B 및 TinyLLaVA 3B보다 3~4배 빠른 것으로 나타났습니다. 매개변수 수가 훨씬 많은 LLaVA v1.5 모델(7B 매개변수)과 비교해도 Cobra는 매개변수 수가 약 43%로 여러 벤치마크에서 여전히 일치하는 성능을 달성했습니다. ㅋㅋ ~ . 
기존 다중 모달 대규모 언어 모델(MLLM)을 조사한 결과 2차 계산 복잡성을 나타내는 Transformer 네트워크에 의존하는 경우가 많습니다. 이러한 비효율성을 해결하기 위해 이 문서에서는 선형 계산 복잡성을 갖춘 새로운 MLLM인 Cobra를 소개합니다.
Mamba 언어 모델에서 시각적 정보와 언어적 정보의 통합을 최적화하기 위해 다양한 모달 융합 체계를 살펴봅니다. 실험을 통해 이 논문에서는 다양한 융합 전략의 효율성을 조사하고 가장 효과적인 다중 모드 표현을 생성하는 방법을 결정합니다.
기본 MLLM의 계산 효율성을 향상시키기 위한 병렬 연구를 통해 Cobra의 성능을 평가하기 위해 광범위한 실험이 수행되었습니다. 특히 Cobra는 더 적은 매개변수로도 LLaVA와 비슷한 성능을 달성하여 효율성을 강조합니다.
- 원본 링크: https://arxiv.org/pdf/2403.14520v2.pdf
- 프로젝트 링크: https://sites.google.com/view/cobravlm/
- 논문 제목: Cobra: 효율적인 추론을 위해 Mamba를 다중 모달 대형 언어 모델로 확장
Cobra는 클래식 시각적 인코더를 사용하여 두 모델을 연결합니다. LM 구조 상태 저장 프로젝터와 LLM 언어 백본으로 구성됩니다. LLM의 백본 부분은 600B 토큰으로 SlimPajama 데이터 세트에서 사전 훈련되고 대화 데이터의 지침으로 미세 조정된 2.8B 매개변수 사전 훈련된 Mamba 언어 모델을 사용합니다.网络 Cobra 네트워크 구조 다이어그램 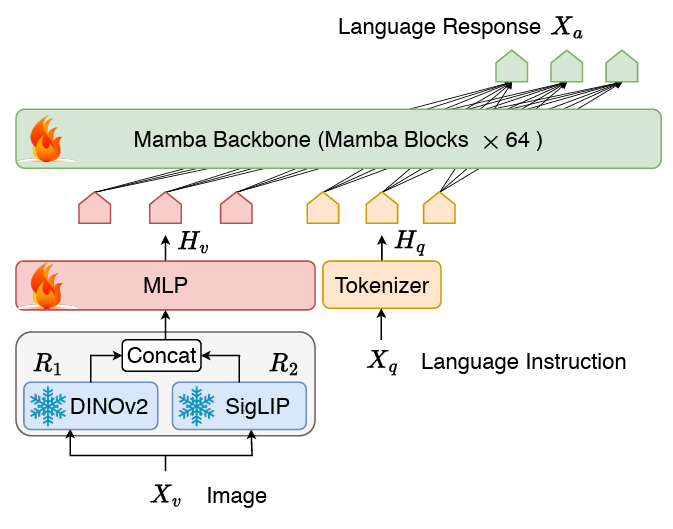
COBRA는 LLAVA 등과는 달리 Dinov2 및 SIGLIP 융합의 시각적 표현을 사용합니다. 두 개의 시각적 코더의 출력을 함께 연결하여 모델이 더 잘 캡처할 수 있습니다. SigLIP에서 가져온 높은 수준의 의미론적 기능과 DINOv2에서 추출한 낮은 수준의 세분화된 이미지 기능입니다. 훈련 계획
최근 연구에 따르면 LLaVA를 기반으로 하는 기존 훈련 패러다임의 경우(예: 투영 계층의 사전 정렬 단계와 LLM 백본의 미세 조정 단계만 한 번 훈련함) 각각) 사전 정렬 단계가 불필요할 수 있으며 미세 조정된 모델이 여전히 과소적합될 수 있습니다. 따라서 Cobra는 사전 정렬 단계를 버리고 전체 LLM 언어 백본과 프로젝터를 직접 미세 조정합니다. 이 미세 조정 프로세스는 다음으로 구성된 결합된 데이터 세트에서 무작위 샘플링을 사용하여 두 에포크 동안 수행되었습니다. LLaVA v1.5에서 사용된 하이브리드 데이터 세트에는 학술을 포함하여 총 655,000개의 시각적 다단계 대화가 포함되어 있습니다. VQA 샘플, LLaVA-Instruct의 시각적 명령 튜닝 데이터 및 ShareGPT의 일반 텍스트 명령 튜닝 데이터. LVIS-Instruct-4V에는 GPT-4V에서 생성된 시각적 정렬 및 상황 인식 지침이 포함된 220K 이미지가 포함되어 있습니다.
-
LRV-Instruct는 환각 현상 완화를 목표로 하는 16가지 시각적 언어 작업을 다루는 400K 시각적 지침이 포함된 데이터 세트입니다.
- 전체 데이터 세트에는 약 120만 개의 이미지와 해당하는 여러 라운드의 대화 데이터 및 일반 텍스트 대화 데이터가 포함되어 있습니다.
Experiment
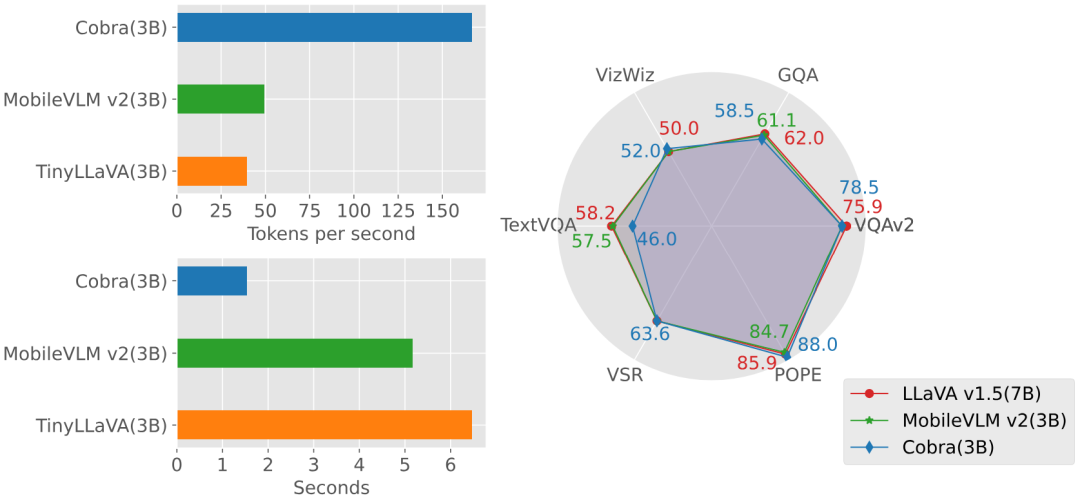
실험 부분에서는 기본 벤치마크에서 제안한 Cobra 모델과 오픈 소스 SOTA VLM 모델을 비교하고, 동일 크기는 Transformer 아키텍처 기반 VLM 모델의 응답 속도를 기반으로 합니다. 동시에 그래프의 생성 속도와 성능 비교를 통해 COBRA는 VQA-V2, GQA, Vizwiz, TextVQA 및 VSR의 4가지 개방형 VQA 작업, POPE 2개 폐쇄 세트 예측 작업에 대해 , 점수는 총 6개의 벤치마크에서 비교되었습니다. 벤치마크와 기타 오픈 소스 모델의 지도 비교 정성 테스트
또한 Cobra는 객체의 Cobra를 정성적으로 설명하기 위해 두 가지 VQA 예제도 제공합니다. 공간 관계를 인식하고 모델 환상을 줄이는 능력이 우수합니다.和 객체 공간 관계를 판단하는 COBRA 및 기타 기본 모델을 그림 收到則在兩個問題上都做出了精確的描述,尤其在第二個實例中,Cobra 準確的辨識出了圖片是來自於機器人的模擬環境。 消融實驗
本文從性能和生成速度這兩個維度對 Cobra 採取的方案進行了消融研究。實驗方案分別對投影機、視覺編碼器、LLM 語言主幹進行了消融實驗。 時所採取的實驗性對比圖
7557575% 所採取的實驗性測量的實驗性對比投影機在效果上顯著優於致力於減少視覺token 數量以提升運算速度的LDP 模組,同時,由於Cobra 處理序列的速度和運算複雜度均優於Transformer,在生成速度上LDP 模組並沒有明顯優勢,因此在Mamba 類模型中使用透過犧牲精度減少視覺token 數量的採樣器可能是不必要的。 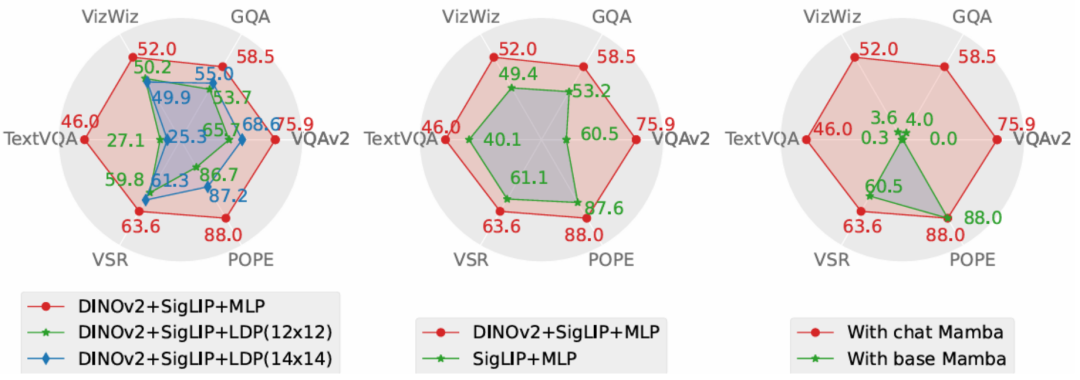
圖中 Cobra v2 特徵的融合有效的提升了 Cobra 的性能。而在語言主幹的實驗中,未經指令微調的 Mamba 語言模型在開放問答的測驗中完全無法給出合理的答案,而經過微調的 Mamba 語言模型則可以在各類任務上達到可觀的表現。 結論

本文提出了 Cobra,它解決了現有依賴具有二次計算複雜度的 Transformer 網路的多模態大型語言模型的效率瓶頸。本文探討了具有線性計算複雜度的語言模型與多模態輸入的結合。在融合視覺和語言資訊方面,本文透過對不同模態融合方案的深入研究,成功優化了 Mamba 語言模型的內部資訊整合,實現了更有效的多模態表徵。實驗表明,Cobra 不僅顯著提高了計算效率,而且在性能上與先進模型如 LLaVA 相當,尤其在克服視覺幻覺和空間關係判斷方面表現出色。它甚至顯著減少了參數的數量。這為未來在需要高頻處理視覺訊息的環境中部署高性能 AI 模型,例如基於視覺的機器人回饋控制,開啟了新的可能性。 위 내용은 최초의 Mamba 기반 MLLM이 출시되었습니다! 모델 가중치, 학습 코드 등은 모두 오픈 소스입니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
































![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



