

로봇이 여러분의 요구 사항을 이해하고 이를 충족시키기 위해 열심히 일할 수 있다면 정말 멋지지 않을까요?
로봇이 도와주길 원한다면 일반적으로 더 정확한 명령을 내려야 하지만, 명령의 실제 구현은 이상적이지 않을 수 있습니다. 실제 환경을 고려하면 로봇이 특정 항목을 찾도록 요청하면 해당 항목이 현재 환경에 실제로 존재하지 않을 수 있으며 로봇이 해당 항목을 찾을 수 없지만 환경에 관련된 다른 항목이 있을 수 있습니다. 요청한 항목이 유사한 기능을 갖고 있으며 사용자의 요구 사항도 충족할 수 있습니까? 이는 "요구사항"을 작업 지침으로 사용하면 얻을 수 있는 이점입니다.
최근 북경대학교 동하오 팀은 새로운 내비게이션 과제를 제안했습니다. 수요 중심 내비게이션(DDN), NeurIPS 2023에서 승인되었습니다. 이 작업에서 로봇은 사용자의 요구 지시에 따라 사용자의 요구를 충족하는 품목을 찾아야 합니다. 동시에 Dong Hao 팀은 수요 지시에 따라 아이템의 속성 특성을 학습할 것을 제안했는데, 이는 로봇의 아이템 찾기 성공률을 효과적으로 향상시켰습니다.

문서 주소: https://arxiv.org/pdf/2309.08138.pdf
프로젝트 홈페이지: https://sites.google.com/view/demand-driven-navigation/home ㅋㅋㅋ > 로봇은 "배고프다", "목마르다"와 같은 요구 명령을 수신한 다음 장면에서 요구 사항을 충족할 수 있는 항목을 찾아야 합니다. 필요. 따라서 수요중심 내비게이션은 본질적으로 아이템을 찾는 작업이며, 이전에도 비슷한 작업인 시각적 개체 내비게이션(Visual Object Navigation)이 있었습니다. 이 두 가지 작업의 차이점은 전자는 로봇에게 "나에게 필요한 것이 무엇인지" 알려주는 것이고, 후자는 "내가 원하는 품목이 무엇인지" 로봇에게 알려주는 것입니다. 
자연어로 설명된 요구사항은 설명 공간이 더 크고 더 정확하고 정확한 요구사항을 제시할 수 있습니다.
 이러한 로봇을 훈련시키기 위해서는 환경이 훈련 신호를 줄 수 있도록 수요 지시와 품목 간의 매핑 관계를 구축해야 합니다. 비용 절감을 위해 Dong Hao 팀은 대규모 언어 모델을 기반으로 한 '반자동' 생성 방법을 제안했습니다. 먼저 GPT-3.5를 사용하여 장면에 존재하는 항목이 충족할 수 있는 요구 사항을 생성한 다음 이를 수동으로 필터링합니다. 요건을 충족하지 못하는 것.
이러한 로봇을 훈련시키기 위해서는 환경이 훈련 신호를 줄 수 있도록 수요 지시와 품목 간의 매핑 관계를 구축해야 합니다. 비용 절감을 위해 Dong Hao 팀은 대규모 언어 모델을 기반으로 한 '반자동' 생성 방법을 제안했습니다. 먼저 GPT-3.5를 사용하여 장면에 존재하는 항목이 충족할 수 있는 요구 사항을 생성한 다음 이를 수동으로 필터링합니다. 요건을 충족하지 못하는 것.
동일한 요구를 충족할 수 있는 아이템은 유사한 속성을 가지고 있다는 점을 고려하면, 그러한 아이템의 속성에 대한 특성을 학습할 수 있다면 로봇은 이러한 속성 특성을 활용하여 아이템을 찾을 수 있을 것으로 보입니다. 예를 들어, "나는 목마르다"라는 요구 사항의 경우 필수 항목에는 "갈증 해소" 속성이 있어야 하며 "주스"와 "차" 모두 이 속성을 가져야 합니다. 여기서 주목해야 할 점은 항목이 다양한 필요에 따라 서로 다른 속성을 나타낼 수 있다는 것입니다. 예를 들어 "물"은 "옷 세탁"이라는 속성과 "세탁"이라는 속성을 모두 표시할 수 있습니다. 갈증 해소'('나는 목마르다'라는 요구 사항에 따라).
속성 학습 단계
그렇다면 모델이 "갈증 해소"와 "옷 청소"의 요구 사항을 이해하도록 하려면 어떻게 해야 할까요? 특정 요구 사항에 따라 항목이 표시하는 속성을 기록하는 것은 비교적 안정적인 상식입니다. 최근에는 대규모 언어 모델(LLM)이 점차 증가하면서 LLM이 보여주는 인간 사회 상식에 대한 이해가 놀랍습니다. 따라서 북경대학교 Dong Hao 팀은 LLM에서 이러한 상식을 배우기로 결정했습니다. 그들은 먼저 LLM에게 많은 요구 지침(그림에서는 언어 기반 수요, LGD라고 함)을 생성하도록 요청한 다음 이러한 요구 지침을 충족할 수 있는 항목(그림에서는 언어 기반 개체, LGO라고 함)이 무엇인지 LLM에 요청했습니다.
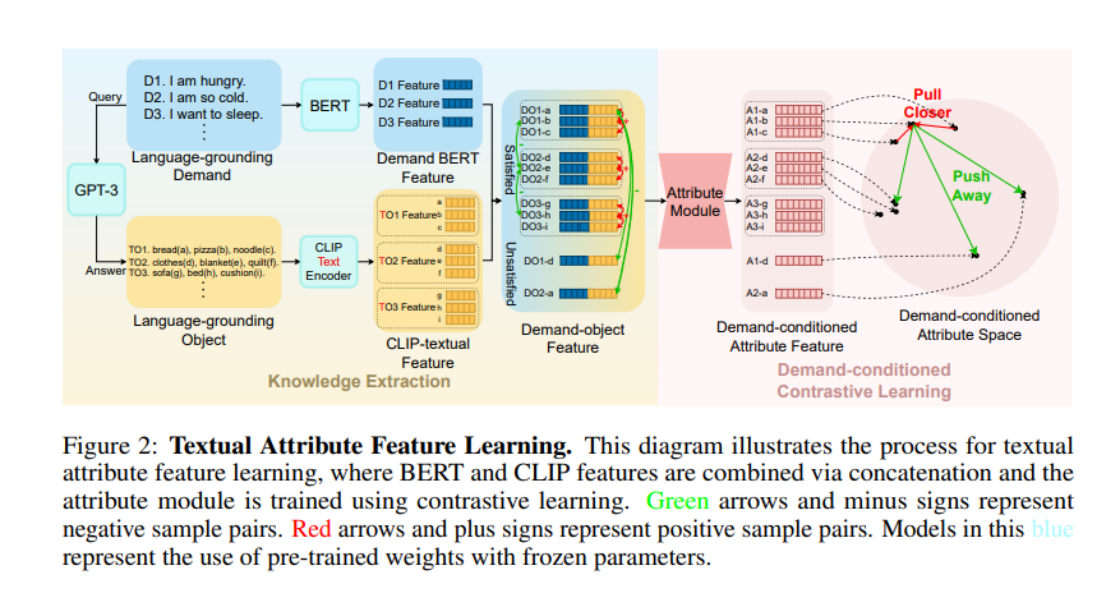
여기서 Language-grounding이라는 접두어는 이러한 수요/객체가 LLM에서 얻을 수 있음을 강조하며 아래 그림의 World-grounding은 이러한 수요/객체를 강조한다는 점에 유의해야 합니다. 특정 환경(예: ProcThor, Replica 및 기타 장면 데이터 세트)과 긴밀하게 통합됩니다.
그런 다음 LGD에서 LGO의 속성을 얻기 위해 저자는 BERT를 사용하여 LGD를 인코딩하고 CLIP-Text-Encoder를 사용하여 LGO를 인코딩한 다음 이들을 접합하여 Demand-object Feature를 얻었습니다. 저자는 처음에 항목의 속성을 도입할 때 '유사성'이 있다는 점에 주목하고 이 유사성을 사용하여 '긍정적 샘플과 부정적 샘플'을 정의한 다음 대조 학습을 사용하여 '항목 속성'을 훈련했습니다. 구체적으로, 결합된 두 개의 수요-객체 특징에 대해 두 특징에 해당하는 항목이 동일한 요구 사항을 충족할 수 있으면 두 특징은 서로 긍정적인 샘플입니다(예: 그림의 항목 a와 항목 b는 모두 요구사항 D1을 충족할 수 있으면 DO1-a와 DO1-b는 서로의 양성 샘플입니다.) 다른 접합은 서로의 음성 샘플입니다. 작성자는 TransformerEncoder 아키텍처의 속성 모듈에 수요 개체 기능을 입력한 후 InfoNCE Loss로 교육했습니다.
항법 전략 학습 단계
비교 학습을 통해 속성 모듈은 LLM에서 제공하는 상식을 학습했습니다. 항법 전략 학습 단계에서는 속성 모듈의 매개변수를 직접 가져온 후 A* 알고리즘을 적용합니다. 모방 학습을 통해 학습한 트랙입니다. 특정 시간 단계에서 작성자는 DETR 모델을 사용하여 현재 시야의 항목을 분할하여 World-grounding Object를 얻은 다음 CLIP-Visual-Endocer로 인코딩합니다. 다른 과정은 속성 학습 단계와 유사합니다. 마지막으로 필요한 명령어의 BERT 기능, 전역 이미지 기능 및 속성 기능이 결합되어 Transformer 모델에 공급되고 마지막으로 작업이 출력됩니다.

저자는 속성 학습 단계에서 CLIP-Text-Encoder를, 탐색 정책 학습 단계에서는 CLIP-Visual-Encoder를 사용했다는 점에 주목할 필요가 있습니다. 여기에서는 CLIP 모델의 강력한 시각적 및 텍스트 정렬 기능을 교묘하게 사용하여 LLM에서 배운 텍스트 상식을 각 단계의 비전으로 전달합니다.
실험 결과
실험은 AI2Thor 시뮬레이터와 ProcThor 데이터 세트에서 수행되었습니다. 실험 결과는 이 방법이 다양한 시각적 항목 탐색 알고리즘과 대규모 언어 모델에서 지원되는 알고리즘의 이전 변형보다 훨씬 높다는 것을 보여줍니다.

VTN は、プリセット項目に対してのみナビゲーション タスクを実行できるクローズドボキャブラリー ナビゲーション アルゴリズムです。著者らはアルゴリズムのいくつかのバリエーションを作成しましたが、必要な命令の BERT 機能が入力として使用されるか、命令の GPT 解析結果が入力として使用されるかにかかわらず、アルゴリズムの結果はあまり理想的ではありません。オープン語彙ナビゲーション アルゴリズムである ZSON に切り替えると、デマンド命令と画像の間の CLIP の位置合わせ効果が不十分なため、ZSON のいくつかのバリアントはデマンド ナビゲーション タスクを適切に完了できません。ヒューリスティック検索 + LLM に基づく一部のアルゴリズムは、Procthor データセットのシーン領域が大きいため探索効率が低く、成功率はあまり高くありません。 GPT-3-Prompt や MiniGPT-4 などの純粋な LLM アルゴリズムは、シーン内の目に見えない場所に対する推論機能が不十分であり、その結果、要件を満たすアイテムを効率的に検出できなくなります。
アブレーション実験により、属性モジュールがナビゲーションの成功率を大幅に向上させることが示されました。著者らは、t-SNE グラフが、属性モジュールが要求条件付き対比学習を通じてアイテムの属性特徴を首尾よく学習していることをよく示していることを示しています。属性モジュール アーキテクチャを MLP に置き換えた後、パフォーマンスが低下しました。これは、TransformerEncoder アーキテクチャが属性特性のキャプチャにより適していることを示しています。 BERT は必要な命令の特徴を適切に抽出できるため、目に見えない命令の一般化が向上します。

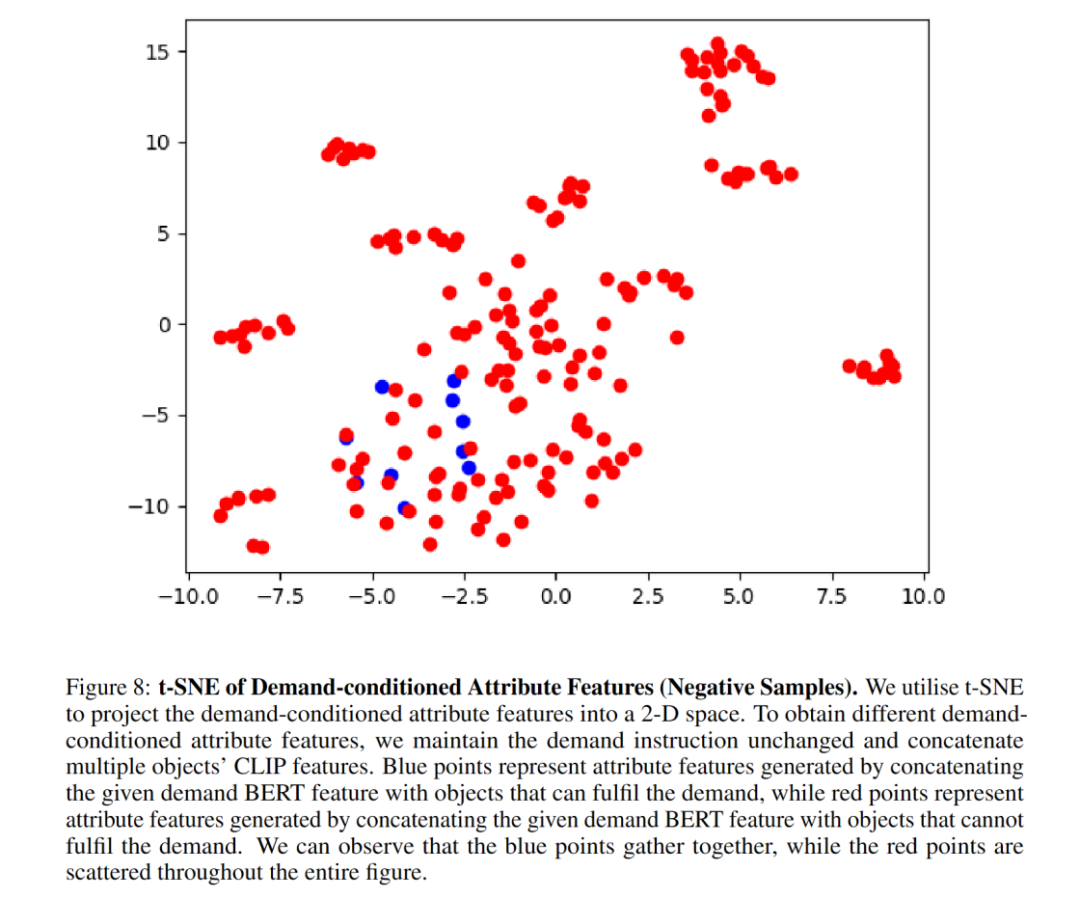
ここにいくつかの視覚化があります: 



この研究の責任著者である Dong Hao 博士は、現在、北京のフロンティア コンピューティング研究センターの助教授です。大学、博士課程の指導教官、リベラルアーツの青少年学者および知的学者である彼は、2019 年に北京大学ハイパープレーン研究所を設立し、率いています。NeurIPS、ICLR、CVPR、ICCV などの主要な国際会議/ジャーナルに 40 以上の論文を発表しています。 、ECCV など。Google Scholar 4,700 回以上引用されており、ACM MM Best Open Source Software Award と OpenI Outstanding Project Award を受賞しています。また、NeurIPS、CVPR、AAAI、ICRA などの主要な国際会議のフィールドチェアマンおよび副編集委員を何度も務め、多くの国家および地方プロジェクトに携わり、科学技術省の新世代会議の議長を務めてきました。人工知能 2030 の主要プロジェクト。

この論文の筆頭著者であるWang Honzhenは現在、北京大学コンピューターサイエンス学部の博士課程2年生です。彼の研究対象は、ロボット工学、コンピューター ビジョン、心理学に焦点を当てており、人間の行動、認知、動機の側面から始めて、人間とロボットの関係を調整したいと考えています。

参考リンク:
[1] https://zsdonghao.github.io/
[2] https://whcpumpkin.github.io/
위 내용은 Peking University의 구체화된 지능 팀은 인간의 요구 사항을 조정하고 로봇을 보다 효율적으로 만들기 위해 수요 중심 탐색을 제안합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



