AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
이 기사의 저자는 Shanghai Jiao Tong University, Tsinghua University, Cambridge University 및 Shanghai Artificial Intelligence Laboratory 출신입니다. 첫 번째 저자인 Chen Zhe는 Shanghai Jiao Tong University의 박사 과정 학생으로 Shanghai Jiao Tong University 인공 지능 학교의 Wang Yu 교수 밑에서 공부하고 있습니다. 교신저자는 칭화대학교 전자공학과 Wang Yu 교수(홈페이지: https://yuwangsjtu.github.io/)와 Zhang Chao 교수(홈페이지: https://mi.eng.cam.ac.uk)입니다. /~cz277). 
- 논문 링크: https://arxiv.org/abs/2403.14168
- 프로젝트 홈페이지: https://jack-zc8.github.io/M3AV-dataset-page/
- 논문 제목: M3AV: 다중 모드, 다중 장르 및 다목적 시청각 학술 강의 데이터 세트
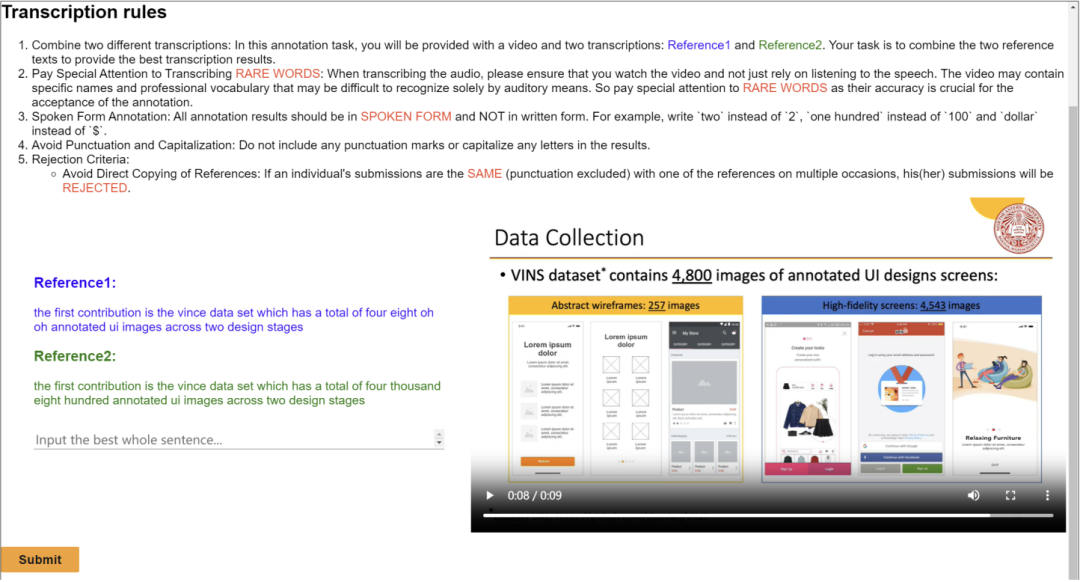
오픈 소스 학술 강의 녹음은 학술 지식을 공유하는 일반적으로 널리 사용되는 방법입니다. 온라인 방법. 이러한 비디오에는 화자의 음성, 얼굴 표정, 신체 움직임, 슬라이드의 텍스트와 이미지, 해당 종이 텍스트 정보 등 풍부한 다중 정보가 포함되어 있습니다. 현재 다중 모드 콘텐츠 인식과 작업 이해를 동시에 지원할 수 있는 데이터 세트가 거의 없습니다. 부분적으로는 고품질의 사람 주석이 부족하기 때문입니다.
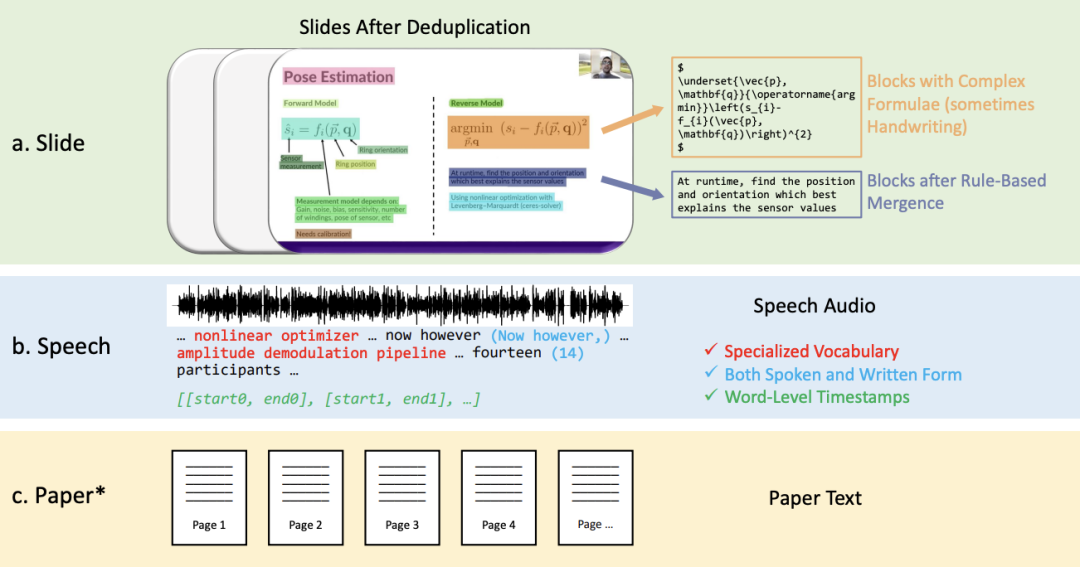
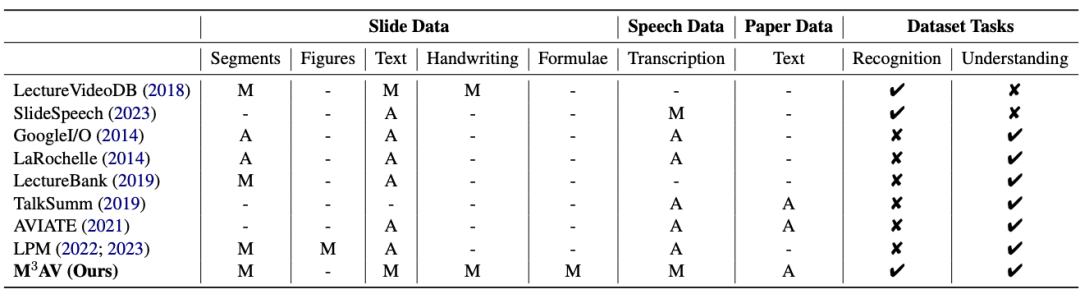
이 작업은 새로운 다중 모드, 다중 유형, 다목적 시청각 학술 음성 데이터 세트(M3AV)를 제안합니다. 여기에는 컴퓨터 과학, 수학, 의료 및 의료를 다루는 5개 소스의 약 367시간 분량의 비디오가 포함되어 있습니다. 생물학적 주제. 고품질 인간 주석, 특히 높은 가치의 명명된 엔터티를 통해 데이터 세트는 다양한 시청각 인식 및 이해 작업에 사용될 수 있습니다. 상황별 음성 인식, 음성 합성, 슬라이드 및 스크립트 생성 작업에 대한 평가에서는 M3AV의 다양성으로 인해 데이터 세트가 까다로운 것으로 나타났습니다. 이 작업은 ACL 2024 메인 컨퍼런스에서 승인되었습니다. M3AV 데이터 세트는 주로 다음 부분으로 구성됩니다. 1 복잡한 블록이 있는 슬라이드는 공간 위치에 따라 정렬됩니다. 관계가 병합됩니다. 2. 특수 어휘 및 단어 수준 타임스탬프를 포함하여 음성 및 서면 형식의 음성으로 변환된 텍스트입니다. 아래 표에서 볼 수 있듯이 M3AV 데이터 세트에는 수동으로 주석이 가장 많이 달린 슬라이드, 음성 및 종이 리소스가 포함되어 있으므로 다중 모드 콘텐츠 인식 작업을 지원할 뿐만 아니라 고급 학문도 지원합니다. 지식 작업을 이해합니다 .
동시에 M3AV 데이터 세트는 모든 측면에서 다른 학술 데이터 세트보다 콘텐츠가 풍부하고 접근 가능한 리소스이기도 합니다.
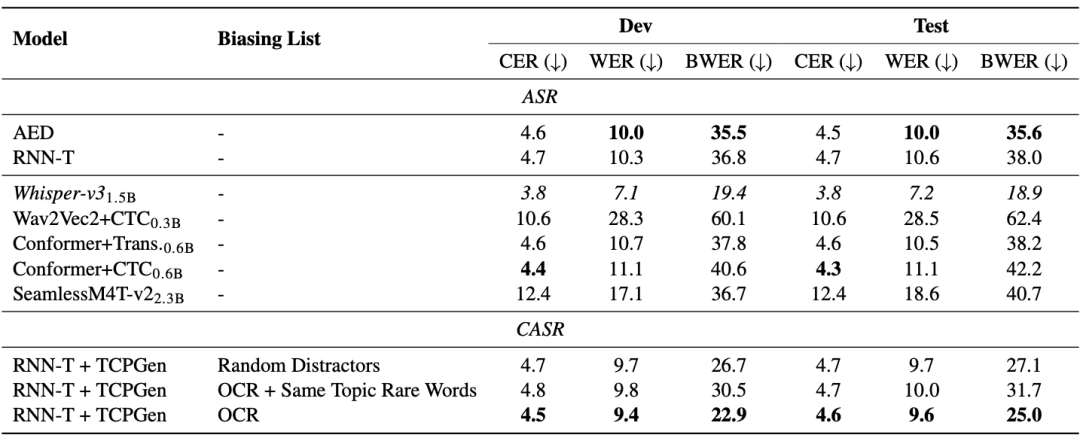
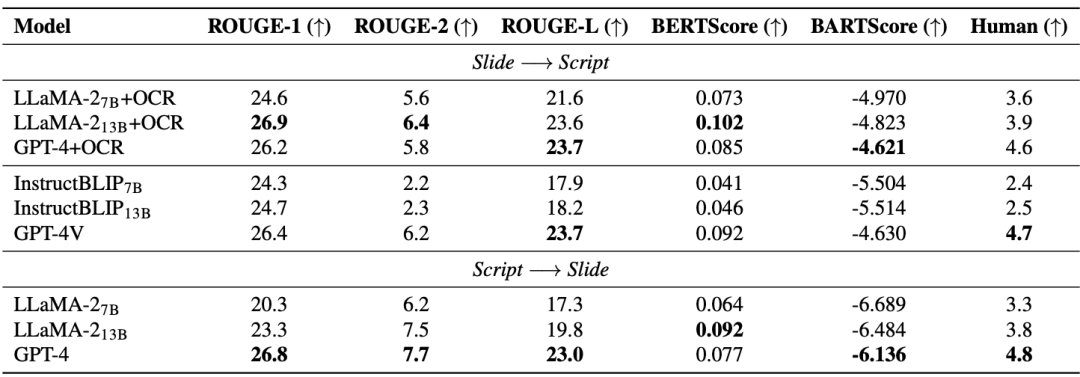
M3AV 데이터 세트는 다중 모드 인식 및 이해의 세 가지 작업, 즉 상황 기반 음성 인식, 자발적인 스타일 음성 합성, 슬라이드 및 스크립트 생성으로 설계되었습니다. 일반적인 엔드투엔드 모델은 드문 단어 인식에 문제가 있습니다. 아래 표의 AED와 RNN-T 모델에서 볼 수 있듯이 BWER(희귀어 단어 오류율)은 전체 단어 오류율(WER)에 비해 2배 이상 증가했습니다. TCPGen을 사용하여 상황 기반 음성 인식을 위한 OCR 정보를 활용함으로써 RNN-T 모델은 개발 세트와 테스트 세트에서 BWER을 각각 37.8%와 34.2%의 상대적 감소를 달성했습니다.
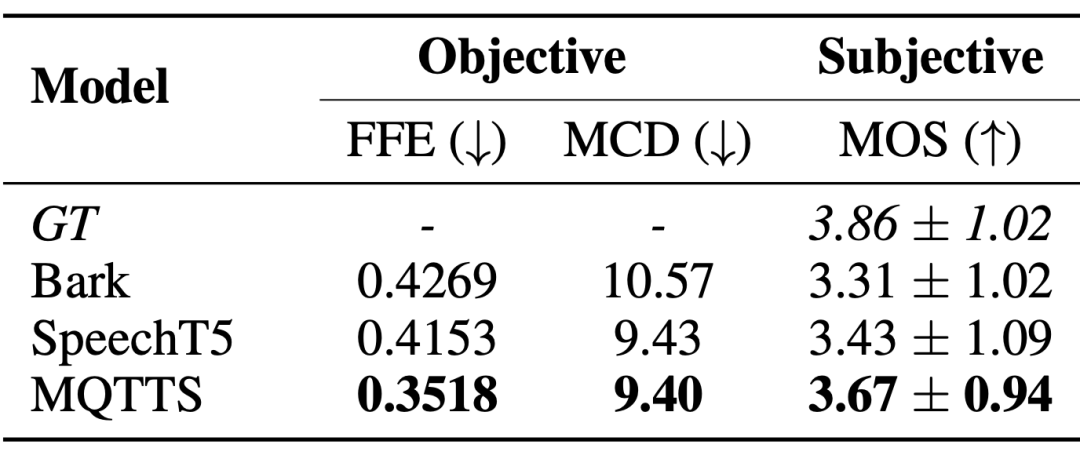
자발적 스타일 음성 합성 시스템은 자연스러운 대화 패턴에 더 가까운 음성을 생성하기 위해 실제 시나리오의 음성 데이터가 시급히 필요합니다. 논문의 저자는 MQTTS를 실험 모델로 소개했고, 다양한 사전 학습 모델과 비교했을 때 MQTTS가 가장 좋은 평가 지표를 가지고 있음을 발견했습니다. 이는 M3AV 데이터 세트의 실제 음성이 AI 시스템을 구동하여 보다 자연스러운 음성을 시뮬레이션할 수 있음을 보여줍니다.
슬라이드 및 스크립트 생성(SSG) 작업은 AI 모델이 고급 학술 지식을 이해하고 재구성하여 연구자가 빠르게 처리할 수 있도록 돕기 위해 설계되었습니다. 학술연구를 효과적으로 수행하기 위해 학술자료를 반복적으로 활용합니다. 아래 표에서 볼 수 있듯이 오픈 소스 모델(LLaMA-2, InstructBLIP)의 성능 향상은 7B에서 13B로 증가할 때 제한적이며 폐쇄 소스 모델(GPT-4 및 GPT-4V)에 비해 뒤떨어집니다. ). 따라서 논문의 저자는 모델 크기를 늘리는 것 외에도 고품질의 다중 모드 사전 학습 데이터도 필요하다고 생각합니다. 특히, 고급 다중 모드 대형 모델(GPT-4V)은 다중 단일 모드 모델로 구성된 계단식 모델보다 성능이 뛰어납니다.
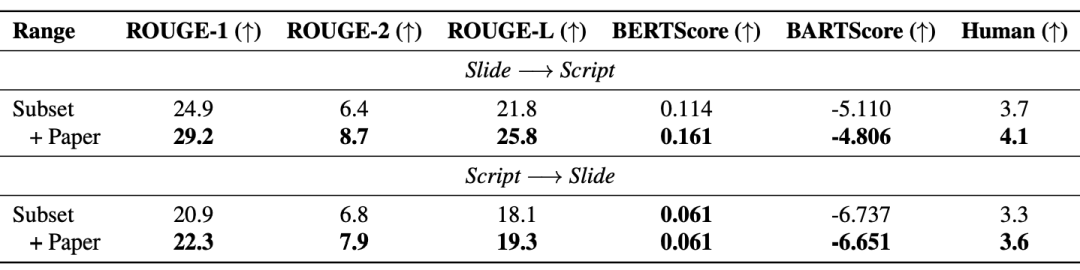
또한 RAG(Retrieval Enhanced Generation)는 모델 성능을 효과적으로 향상시킵니다. 아래 표는 도입된 종이 텍스트가 생성된 슬라이드와 스크립트의 품질도 향상한다는 것을 보여줍니다.
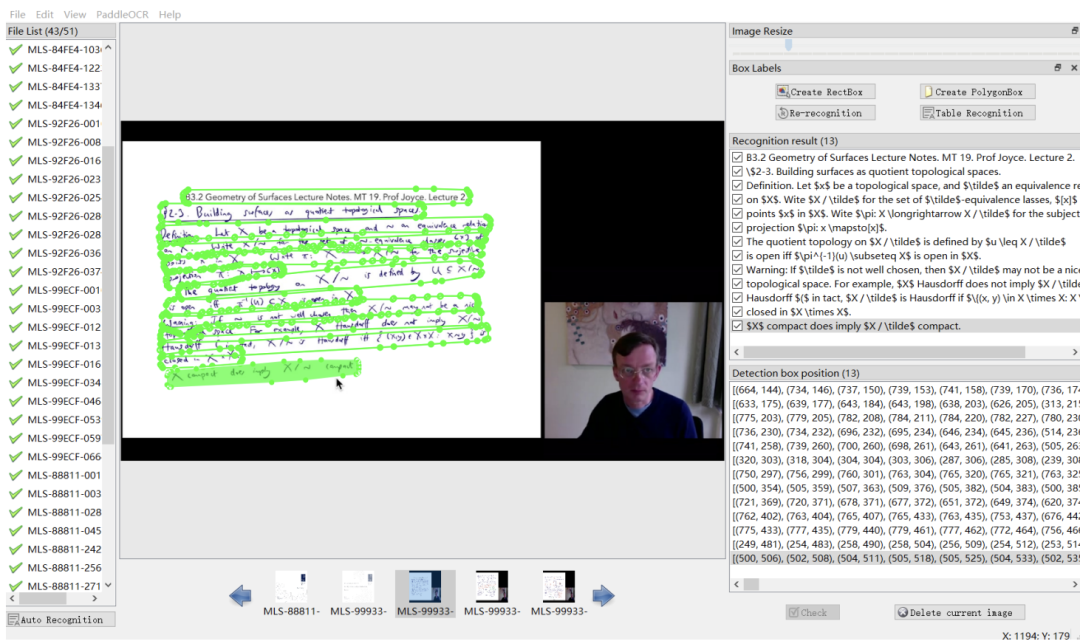
이 작업은 여러 학문 분야를 포괄하는 다중 모드, 다중 유형, 다목적 시청각 데이터 세트(M3AV)를 출시합니다. 데이터 세트에는 사람이 주석을 추가한 음성 전사, 슬라이드 및 추가로 추출된 에세이 텍스트가 포함되어 있어 AI 모델이 다중 모드 콘텐츠를 인식하고 학문적 지식을 이해하는 능력을 평가하기 위한 기반을 제공합니다. 논문의 저자는 생성 과정을 자세히 설명하고 데이터 세트에 대한 다양한 분석을 수행합니다. 또한 벤치마크를 구축하고 데이터 세트를 중심으로 여러 실험을 수행했습니다. 궁극적으로 논문의 저자들은 기존 모델이 학술 강의 영상을 인식하고 이해하는 데 여전히 개선의 여지가 있음을 발견했습니다. 부분 주석 인터페이스
위 내용은 ACL 2024 | 상하이 자오퉁 대학교(Shanghai Jiao Tong University), 칭화 대학교(Tsinghua University), 캠브리지 대학교(Cambridge University), 상하이 AILAB가 공동으로 학술 시청각 데이터 세트 M3AV를 발표했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



