AIxiv 칼럼은 본 사이트에 학술적, 기술적 내용을 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
이 연구는 10개 데이터 세트에 대한 고급 다중 모드 기본 모델의 다중 샘플 컨텍스트 학습을 평가하여 지속적인 성능 개선을 보여줍니다. 일괄 쿼리는 성능 저하 없이 예제당 대기 시간과 추론 비용을 크게 줄여줍니다. 이러한 결과는 다음을 입증합니다. 다양한 데모 예제 세트를 활용하면 기존의 미세 조정 없이도 새로운 작업과 도메인에 빠르게 적응할 수 있습니다. 
- 문서 주소: https://arxiv.org/abs/2405.09798
- 코드 주소: https://github.com/stanfordmlgroup/ManyICL
Multimodal Foundation Model에 대한 최근 연구에서 ICL(In-Context Learning)이 모델 성능을 향상시키는 효과적인 방법 중 하나로 입증되었습니다. 기본 모델의 컨텍스트 길이, 특히 이미지를 표현하기 위해 많은 수의 시각적 토큰이 필요한 다중 모드 기본 모델의 경우 기존 관련 연구는 적은 수의 샘플을 제공하는 데 국한됩니다. 문맥. 흥미롭게도 최근 기술 발전으로 인해 모델의 컨텍스트 길이가 크게 늘어났으며, 이로 인해 더 많은 예제를 사용하여 컨텍스트 학습을 탐색할 가능성이 열렸습니다. 이를 바탕으로 Stanford Ng 팀의 최신 연구인 ManyICL은 주로 소수 샘플(100개 미만)에서 다중 샘플까지 상황 학습에서 현재 최첨단 다중 모달 기본 모델을 평가합니다. 샘플(최대 2000개) 의 성능. 팀은 여러 도메인 및 작업의 데이터 세트를 테스트하여 모델 성능 향상에 있어 다중 샘플 컨텍스트 학습의 중요한 효과를 확인하고 배치 쿼리가 성능, 비용 및 대기 시간에 미치는 영향을 조사했습니다. 매니샷 ICL과 제로 샘플, 소수 샘플 ICL의 비교. 이 연구를 위해 세 가지 고급 멀티모달 기본 모델이 선택되었습니다: GPT-4o, GPT4 (V)-Turbo 및 Gemini 1.5 Pro. GPT-4o의 우수한 성능으로 인해 연구팀은 본문에서 GPT-4o와 Gemini 1.5 Pro에 중점을 두었습니다. 부록에서 GPT4(V)-Turbo 관련 내용을 확인하시기 바랍니다. 데이터세트 측면에서 연구팀은 다양한 분야(자연영상, 의료영상, 원격탐사영상, 분자영상 등 포함)와 과제(다분류, 다중라벨 분류 포함)에 걸쳐 10개 데이터세트에 대한 실험을 진행했다. 세밀한 분류) 광범위한 실험. ㅋㅋㅋ ~ 벤치마크 데이터 세트 요약.
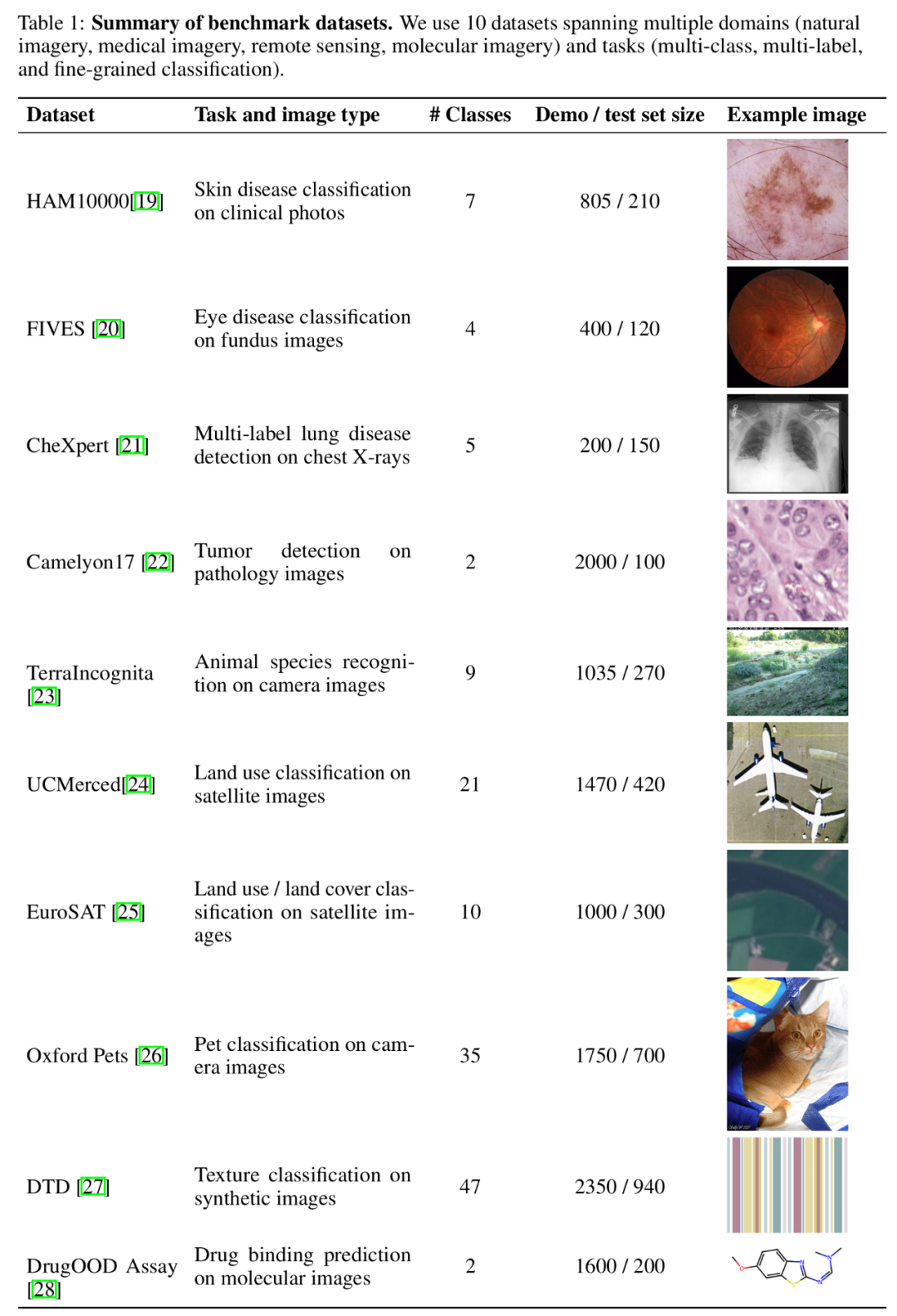 예제 수 증가가 모델 성능에 미치는 영향을 테스트하기 위해 연구팀은 컨텍스트에 제공되는 예 수를 점차적으로 최대 2,000개까지 늘렸습니다. 동시에 다중 샘플 학습의 높은 비용과 높은 대기 시간을 고려하여 연구팀은 쿼리 일괄 처리의 영향도 조사했습니다. 여기서 일괄 쿼리는 단일 API 호출로 여러 쿼리를 처리하는 것을 의미합니다. 전체 성능: 거의 2000개에 가까운 예제를 사용한 다중 샘플 상황 학습이 모든 데이터세트 퓨샷 학습 . Gemini 1.5 Pro 모델의 성능은 예제 수가 증가함에 따라 일관된 로그 선형 개선을 보이는 반면, GPT-4o의 성능은 덜 안정적입니다.
예제 수 증가가 모델 성능에 미치는 영향을 테스트하기 위해 연구팀은 컨텍스트에 제공되는 예 수를 점차적으로 최대 2,000개까지 늘렸습니다. 동시에 다중 샘플 학습의 높은 비용과 높은 대기 시간을 고려하여 연구팀은 쿼리 일괄 처리의 영향도 조사했습니다. 여기서 일괄 쿼리는 단일 API 호출로 여러 쿼리를 처리하는 것을 의미합니다. 전체 성능: 거의 2000개에 가까운 예제를 사용한 다중 샘플 상황 학습이 모든 데이터세트 퓨샷 학습 . Gemini 1.5 Pro 모델의 성능은 예제 수가 증가함에 따라 일관된 로그 선형 개선을 보이는 반면, GPT-4o의 성능은 덜 안정적입니다.
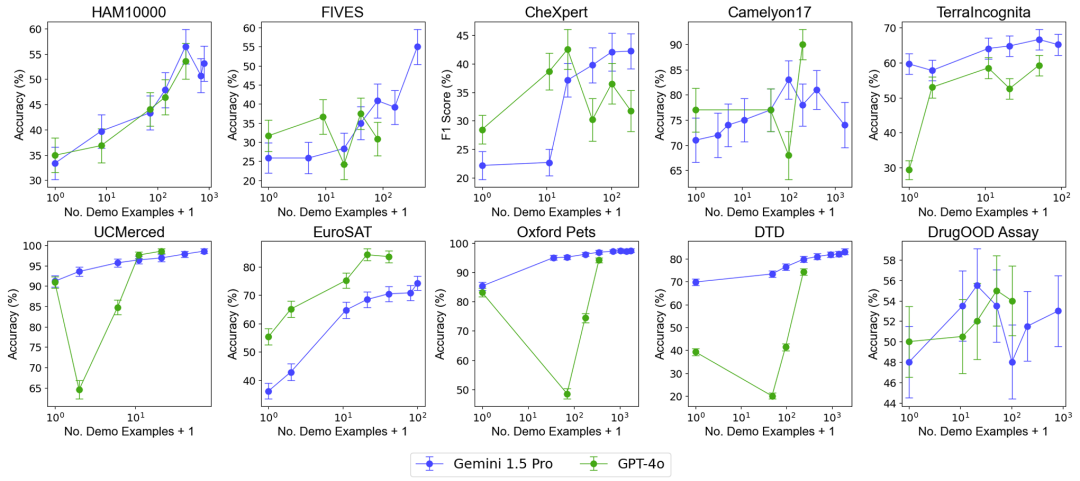
데이터 효율성: 이 연구는 모델의 상황별 학습 데이터 효율성, 즉 모델이 예제에서 얼마나 빨리 학습하는지를 측정했습니다. 결과에 따르면 Gemini 1.5 Pro는 대부분의 데이터 세트에서 GPT-4o보다 더 높은 상황 학습 데이터 효율성을 보여주며, 이는 예제를 통해 더 효과적으로 학습할 수 있음을 의미합니다. 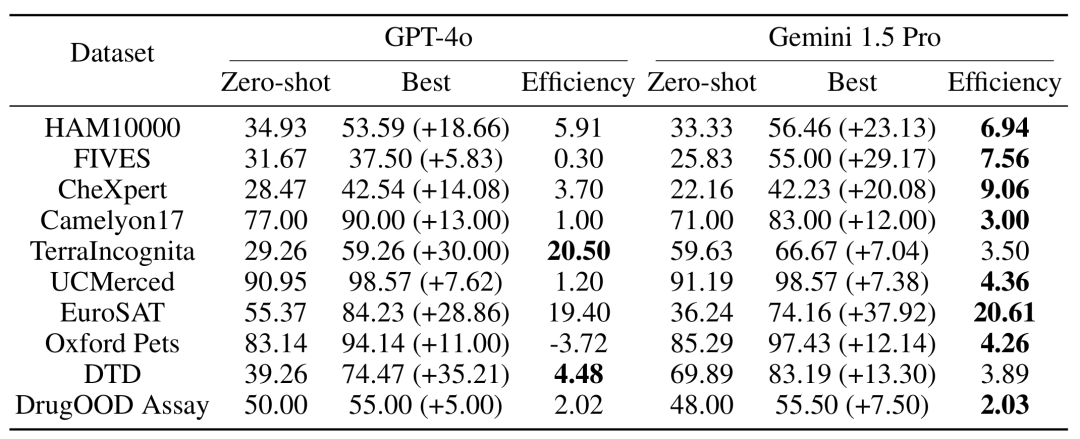
전체 성능: 최적의 샘플 세트 크기가 선택된 제로 샘플 및 다중 샘플 시나리오에서는 여러 쿼리를 하나의 요청으로 병합해도 성능이 저하되지 않습니다. 제로 샷 시나리오에서는 단일 쿼리가 많은 데이터 세트에서 제대로 작동하지 않는다는 점에 주목할 가치가 있습니다. 이와 대조적으로 일괄 쿼리는 성능을 향상시킬 수도 있습니다. 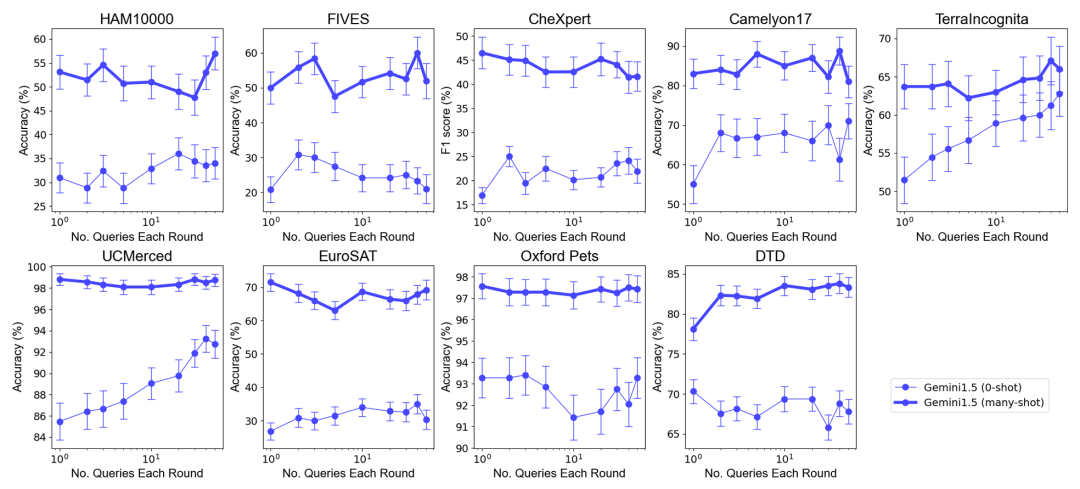
제로 샘플 시나리오의 성능 향상: 일부 데이터 세트(예: UCMerced)의 경우 일괄 쿼리는 제로 샘플 시나리오의 성능을 크게 향상시킵니다. 연구팀은 이는 주로 도메인 교정(Domain Calibration), 클래스 교정(Class Calibration), 자가학습(Self-ICL)에 따른 것으로 분석했다. 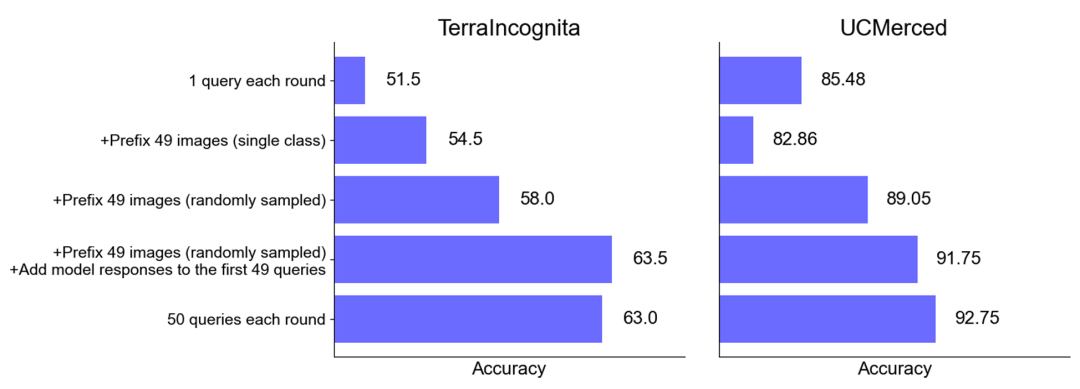
다중 샘플 컨텍스트 학습 추론 중에 더 긴 입력 컨텍스트를 처리해야 하지만 일괄 쿼리를 통해 각 예제의 지연 시간 및 추론 비용을 크게 줄일 수 있습니다. 예를 들어, HAM10000 데이터 세트에서 350개 예시의 일괄 쿼리에 Gemini 1.5 Pro 모델을 사용하면 대기 시간이 17.3초에서 0.54초로 줄어들고 비용도 예시당 $0.842에서 $0.0877로 감소했습니다. 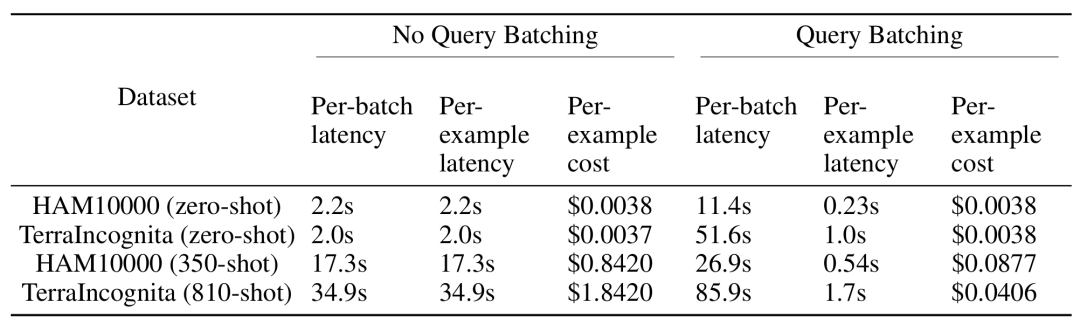
연구 결과에 따르면 다중 샘플 컨텍스트 학습은 다중 모드 기본 모델의 성능을 크게 향상시킬 수 있으며, 특히 Gemini 1.5 Pro 모델은 다중 데이터 세트에서 지속적인 성능 향상을 보여줍니다. 기존의 미세 조정 없이도 새로운 작업과 영역에 보다 효과적으로 적응할 수 있습니다. 둘째, 쿼리의 일괄 처리는 추론 비용과 대기 시간을 줄이는 동시에 유사하거나 더 나은 모델 성능을 달성하여 실제 애플리케이션에서 큰 잠재력을 보여줄 수 있습니다. 일반적으로 Andrew Ng 팀의 이 연구는 특히 새로운 작업과 분야에 대한 신속한 적응 측면에서 다중 모드 기본 모델을 적용할 수 있는 새로운 길을 열어줍니다. 위 내용은 Andrew Ng 팀의 새로운 작업: 다중 모드 및 다중 샘플 컨텍스트 학습, 미세 조정 없이 새로운 작업에 빠르게 적응.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!





































![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



