

データ形式は次のとおりです:
リーリー要件の説明:
各データを 1 日の座標マップ (00:00 ~ 24:00) にプロットし、
考えられる回路図は次のとおりです:
1. データの startTime と endTime に応じて、データの Y 軸上の座標を取得できます ( は上端と高さで表されます)実装されている値 )
2. 各期間は交差する場合があるため (あるイベントの期間の一部 (startTime - endTime) が別のイベントの期間内にあるため、これを交差と呼びます)、X 軸上の交差はイベントの幅は、交差して等分する場合、order が大きくなるほど、位置が高くなります。#2.3 イベントは、別のイベントと交差することも、他の複数のイベントと交差することもあります。
私の質問は、X 軸の幅を二等分して左に配置するアルゴリズムをどのように実装するかです。つまり、各要素の左と幅はアルゴリズムの価値があります
補足内容:AとBが交差、BとCが交差、AとCが交差しない場合、ABCも均等に分割されます















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




ざっくり書くと、基本的な考え方は
まず、すべてのタスクを大きいものから小さいものに並べ替えます(この部分は省略します)
start endを押してタスクオブジェクトを生成し、Figureオブジェクトのadd_oneを使って順番にFigureに追加します。
オブジェクトを挿入する際、既存のオブジェクトの中で重なっているオブジェクトを判断し、その左を最も重なっている最大のオブジェクトの左+1に等しくし、同時に最大幅を更新します
最後に、is_overlap メソッドを使用して、どのイベントとも交差しないタスク内のイベントを検出し、これらのイベントの左側を 0 に設定し、これらのイベント以外のイベントの幅を 100% に設定します。 , 幅は 1/max_width に設定され、左 1/max_width*(left-1) に設定されます (この部分は省略されています)
次のコードはステップ 2 と 3 です
リーリー2D グループ化
-
このようにして、2 つの次元を垂直方向と水平方向にグループ化した後、それらをグラフィックスに変換するのは簡単です。最初に縦方向にグループ化します (
VGroups)。交差する関係を持つイベントは同じグループにグループ化されます。各グループは独立しています (グループは交差しません)。グループ化アルゴリズムは次のとおりです。各イベントをノードとして扱い、2 つのノードが交差する場合、エッジが接続されます。このようにしてグラフが得られ、グループ化とはこのグラフの連結成分を見つけることです。深さ優先検索や幅優先検索などのアルゴリズムを使用して、連結成分を見つけることができます。垂直グループ内で水平方向にグループ化します (
HGroups)。 交差関係がないイベントは、同じグループにグループ化されます (グループは交差しません)。このステップの目的は、並べて表示できるイベントの数を圧縮し、空きスペースを利用することです。
テスト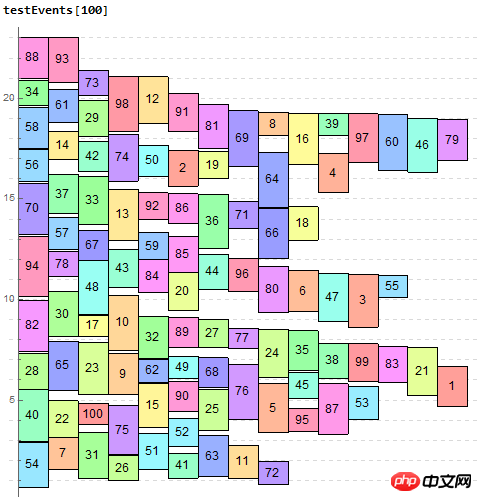
添付:Mahematica コード リーリー
@saigyouyou
こんな感じかも