合計 10000 件の関連コンテンツが見つかりました

コードを 1 行変更するだけで、PyTorch のトレーニングが 3 倍高速になります。これらの「先進技術」が鍵となります
記事の紹介:最近、深層学習の分野で著名な研究者であり、LightningAI の主任人工知能教育者である Sebastian Raschka 氏が、CVPR2023 で基調講演「ScalingPyTorchModelTrainingWithMinimalCodeChanges」を行いました。研究結果をより多くの人々と共有するために、セバスティアン・ラシュカはスピーチを記事にまとめました。この記事では、最小限のコード変更で PyTorch モデルのトレーニングをスケーリングする方法を検討し、低レベルのマシンの最適化ではなく、混合精度メソッドとマルチ GPU トレーニング モードを活用することに焦点を当てていることを示しています。記事の使用状況ビュー
2023-08-14
コメント 0
923

言語モデルのバイアスと自己修正方法に関する研究
記事の紹介:言語モデルのバイアスとは、テキストを生成するときに特定のグループ、テーマ、またはトピックに対してバイアスがかかる可能性があり、その結果、テキストが偏りのない、中立的、または差別的なものになる可能性があります。このバイアスは、トレーニング データの選択、トレーニング アルゴリズムの設計、モデルの構造などの要因から発生する可能性があります。この問題を解決するには、データの多様性に焦点を当て、トレーニング データにさまざまな背景や視点が含まれるようにする必要があります。さらに、生成されるテキストの品質と包括性を向上させるために、トレーニング アルゴリズムとモデルの構造を見直し、その公平性と中立性を確保する必要があります。たとえば、トレーニング データに特定のカテゴリに対する過度の偏りがあり、テキストを生成するときにモデルがそれらのカテゴリをより優先する可能性があります。このバイアスにより、他のカテゴリを扱うときにモデルのパフォーマンスが低下し、モデルのパフォーマンスに影響を与える可能性があります。また、モデルによってデザインが多少異なる場合がございます。
2024-01-22
コメント 0
432

Python がサポート ベクター マシン (SVM) 分類を実装: アルゴリズム原理の詳細な説明
記事の紹介:機械学習では、サポート ベクター マシン (SVM) がデータの分類と回帰分析によく使用され、分離超平面に基づく判別アルゴリズム モデルです。言い換えれば、ラベル付きトレーニング データが与えられると、アルゴリズムは新しい例を分類するための最適な超平面を出力します。サポート ベクター マシン (SVM) アルゴリズム モデルは、サンプルを空間内の点として表現し、マッピング後、さまざまなカテゴリのサンプルを可能な限り分割します。線形分類の実行に加えて、サポート ベクター マシン (SVM) は非線形分類を効率的に実行し、入力を高次元特徴空間に暗黙的にマッピングできます。サポートベクターマシンは何をするのでしょうか?トレーニング サンプルのセットが与えられると、各トレーニング サンプルは 2 つのカテゴリに従ってカテゴリでマークされ、サポート ベクター マシン (SVM) トレーニング アルゴリズムを通じてモデルが構築され、新しいサンプルが次のように分類されます。
2024-01-24
コメント 0
1131

X-Dreamer は次元の壁を突破し、2D 生成と 3D 生成の分野を統合し、高品質のテキストを 3D 生成にもたらします。
記事の紹介:近年、事前トレーニングされた拡散モデルの開発により、テキストの 3D コンテンツへの自動変換が大幅に進歩しました [1、2、3]。その中で、DreamFusion [4] は、事前トレーニングされた 2D 拡散モデル [5] を利用して、特殊な 3D アセット データセットを必要とせずにテキストから 3D アセットを自動的に生成する効率的な方法を導入しました。 (SDS) アルゴリズム。このアルゴリズムは、事前トレーニングされた 2D 拡散モデルを利用して、NeRF [6] などの単一の 3D 表現を評価し、それによって、どのカメラの視点からでもレンダリングされたイメージが指定されたテキストと高い一貫性を維持できるように最適化します。独創的な SDS アルゴリズムにインスピレーションを受けて、いくつかの
2023-12-15
コメント 0
559

ConvNeXt V2 は、最も単純な畳み込みアーキテクチャのみを使用し、Transformer に劣らないパフォーマンスを実現します。
記事の紹介:数十年にわたる基礎研究を経て、視覚認識の分野は大規模な視覚表現学習の新時代を迎えました。事前トレーニングされた大規模ビジョン モデルは、特徴学習およびビジョン アプリケーションにとって不可欠なツールとなっています。視覚表現学習システムのパフォーマンスは、モデルのニューラル ネットワーク アーキテクチャ、ネットワークのトレーニングに使用される方法、トレーニング データという 3 つの主な要素によって大きく影響されます。各要素の改善は、モデル全体のパフォーマンスの向上に貢献します。ニューラル ネットワーク アーキテクチャ設計の革新は、表現学習の分野で常に重要な役割を果たしてきました。畳み込みニューラル ネットワーク アーキテクチャ (ConvNet) は、コンピューター ビジョンの研究に大きな影響を与え、人工知能に依存せずにさまざまな視覚認識タスクで普遍的な特徴学習手法を使用できるようにしました。
2023-04-11
コメント 0
1416

KNN アルゴリズム分類の基本原理と例
記事の紹介:KNN アルゴリズムは、小規模なデータセットや低次元の特徴空間に適した、シンプルで使いやすい分類アルゴリズムです。画像分類やテキスト分類などの分野で優れたパフォーマンスを発揮し、実装の簡単さと理解のしやすさで人気があります。 KNN アルゴリズムの基本的な考え方は、分類されるサンプルの特性とトレーニング サンプルの特性を比較することによって最も近い K 個の近傍を見つけ、これらのカテゴリに基づいて分類されるサンプルのカテゴリを決定することです。近所のKさん。 KNN アルゴリズムは、ラベル付けされたカテゴリを含むトレーニング セットと分類されるテスト セットを使用します。 KNN アルゴリズムの分類プロセスには次のステップが含まれます: まず、分類されるサンプルとすべてのトレーニング サンプルの間の距離を計算します。次に、K 個の最近傍を選択します。次に、K 個の最近傍のカテゴリに従って投票して、分類サンプル カテゴリ; ほとんどの
2024-01-23
コメント 0
745

「White Wattle Corridor」共同訓練場ゲームプレイ紹介
記事の紹介:白京回廊合同訓練場でのプレー方法は?合同訓練場は、White Wattle Corridor のゲームプレイ モードの 1 つです。多くのプレイヤーは、具体的なプレイ方法を知りません。プレイヤーは、記事の内容を参照して、合同訓練場のゲームプレイについて学ぶことができます。詳細は、こちらをご覧ください。 White Wattle Corridor Joint Training Ground のゲームプレイ紹介です。必ず役立つと思いますので、見てみましょう。 「白京回廊」共同訓練場 ゲームプレイ紹介 ゲームプレイ紹介: 1. まず、プレイヤーは時間順に 4 つの防衛ゾーン A、B、C、D を占領する必要があります。A、B、C、D の下には 3 つのパーティションがあります。 2. プレイヤーは戦うキャラクターを四角いキャンプコーナーとひし形の職業にそれぞれ配置し、ここに配置することになります。 3. 最後に、戦闘結果に基づいてスコアが決定されます。採点ルール: 1. 1,000 点ごとに減点枠の数が 5% 増加し、減点の進行状況が最大値を示します。
2024-01-12
コメント 0
1191

原点回帰のための記号アルゴリズム
記事の紹介:シンボリック回帰アルゴリズムは、数学的モデルを自動的に構築する機械学習アルゴリズムです。その主な目的は、入力データ内の変数間の関数関係を分析することによって、出力変数の値を予測することです。このアルゴリズムは、遺伝的アルゴリズムと進化的戦略の考え方を組み合わせたもので、数式をランダムに生成して組み合わせることでモデルの精度を徐々に向上させます。モデルを継続的に最適化することで、シンボリック回帰アルゴリズムは、複雑なデータの関係をより深く理解し、予測するのに役立ちます。シンボリック回帰アルゴリズムのプロセスは次のとおりです。 1. 問題を定義します。入力変数と出力変数を決定します。 2. 母集団の初期化: 母集団として一連の数式をランダムに生成します。適応度の評価:各個人の数式を使用してトレーニングセット内のデータを予測し、予測値と実際の値の誤差を適応度として計算します
2024-01-23
コメント 0
1406

ハイパーパラメータを最適化するための関数とメソッド
記事の紹介:ハイパーパラメータは、モデルをトレーニングする前に設定する必要があるパラメータです。トレーニング データから学習することはできず、手動で調整するか、自動検索によって決定する必要があります。一般的なハイパーパラメータには、学習率、正則化係数、反復回数、バッチ サイズなどが含まれます。ハイパーパラメータ調整は、アルゴリズムのパフォーマンスを最適化するプロセスであり、アルゴリズムの精度とパフォーマンスを向上させるために非常に重要です。ハイパーパラメータ調整の目的は、ハイパーパラメータの最適な組み合わせを見つけて、アルゴリズムのパフォーマンスと精度を向上させることです。調整が不十分な場合、アルゴリズムのパフォーマンスが低下し、過学習や過小学習などの問題が発生する可能性があります。チューニングによりモデルの汎化能力が強化され、新しいデータに対するパフォーマンスが向上します。したがって、ハイパーパラメータを完全に調整することが重要です。ハイパーパラメータ調整にはさまざまな方法があり、一般的な方法には、グリッド検索、ランダム検索、ベイズ最適化などがあります。
2024-01-22
コメント 0
764

自動学習機械(AutoML)
記事の紹介:自動機械学習 (AutoML) は、機械学習の分野における変革をもたらします。アルゴリズムを自動的に選択して最適化できるため、機械学習モデルのトレーニング プロセスがよりシンプルかつ効率的になります。機械学習の経験がなくても、AutoML を利用して優れたパフォーマンスのモデルを簡単にトレーニングできます。 AutoML は、モデルの解釈可能性を高めるための説明可能な AI アプローチを提供します。このようにして、データ サイエンティストはモデルの予測プロセスについての洞察を得ることができます。これは、ヘルスケア、金融、自律システムの分野で特に役立ちます。データのバイアスを特定し、誤った予測を防ぐのに役立ちます。 AutoML は機械学習を活用して、アルゴリズムの選択、ハイパーパラメータの最適化、特徴量エンジニアリングなどのタスクを含む現実世界の問題を解決します。一般的に使用されるいくつかの方法を次に示します。
2024-01-22
コメント 0
908

深い思考 | 大規模モデルの機能境界はどこにあるのでしょうか?
記事の紹介:無限のデータ、無限の計算能力、無限のモデル、完璧な最適化アルゴリズム、汎化パフォーマンスなどの無限のリソースがある場合、結果として得られる事前トレーニングされたモデルを使用してすべての問題を解決できるでしょうか?これは誰もが非常に懸念している質問ですが、既存の機械学習理論では答えることができません。モデルは無限であり、表現能力も当然無限であるため、表現能力理論とは何の関係もありません。また、アルゴリズムの最適化と一般化のパフォーマンスは完璧であると仮定しているため、最適化と一般化の理論とは無関係です。言い換えれば、これまでの理論研究の問題はここではもはや存在しません。今日は、私が ICML'2023 で発表した論文 OnthePowerofFoundationModels を圏論の観点から紹介したいと思います。
2023-09-08
コメント 0
1267

RLHF なしで人間の位置合わせが可能、ChatGPT に匹敵するパフォーマンス!中国チームがウォンバットモデルを提案
記事の紹介:OpenAI の ChatGPT は、さまざまな人間の指示を理解し、さまざまな言語タスクで適切に実行できます。これは、RLHF (Aligned Human Feedback via Reinforcement Learning) と呼ばれる新しい大規模言語モデル微調整手法のおかげで可能になります。 RLHF メソッドは、人間の指示に従う言語モデルの能力を解放し、言語モデルの能力を人間のニーズや価値観と一致させます。現在、RLHF の研究作業では主に PPO アルゴリズムを使用して言語モデルを最適化しています。ただし、PPO アルゴリズムには多くのハイパーパラメータが含まれており、アルゴリズムの反復プロセス中に複数の独立したモデルが相互に連携する必要があるため、実装の詳細が間違っているとトレーニング結果が低下する可能性があります。同時に、人間の調整の観点からは、強化学習アルゴリズムは必要ありません。口論
2023-05-03
コメント 0
1323

機械学習アルゴリズムにおける過学習問題
記事の紹介:機械学習アルゴリズムの過学習問題には、特定のコード例が必要です。機械学習の分野では、モデルの過学習問題は一般的な課題の 1 つです。モデルがトレーニング データにオーバーフィットすると、ノイズや外れ値に過度に敏感になり、新しいデータに対するモデルのパフォーマンスが低下します。過学習問題を解決するには、モデルのトレーニング プロセス中にいくつかの効果的な方法を採用する必要があります。一般的なアプローチは、L1 正則化や L2 正則化などの正則化手法を使用することです。これらの手法は、モデルが過剰な処理を行わないようにペナルティ項を追加することでモデルの複雑さを制限します。
2023-10-09
コメント 0
984

機能はモデル タイプの選択にどのような影響を与えますか?
記事の紹介:特徴は機械学習において重要な役割を果たします。モデルを構築するときは、トレーニング用の特徴を慎重に選択する必要があります。機能の選択は、モデルのパフォーマンスとタイプに直接影響します。この記事では、機能がモデル タイプにどのような影響を与えるかを説明します。 1. 特徴量の数 特徴量の数は、モデルの種類に影響を与える重要な要素の 1 つです。特徴の数が少ない場合は、通常、線形回帰、決定木などの従来の機械学習アルゴリズムが使用されます。これらのアルゴリズムは少数の特徴の処理に適しており、計算速度は比較的高速です。ただし、特徴の数が非常に多くなると、高次元データの処理が困難になるため、通常、これらのアルゴリズムのパフォーマンスが低下します。したがって、この場合、サポート ベクター マシン、ニューラル ネットワークなどのより高度なアルゴリズムを使用する必要があります。これらのアルゴリズムは高次元を処理できます。
2024-01-24
コメント 0
998
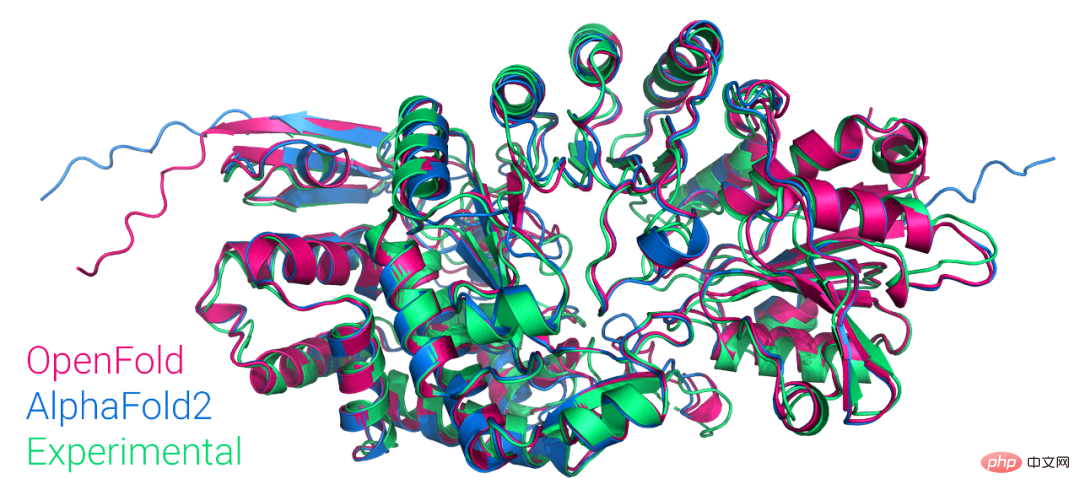
AlphaFold2 の最初の一般公開された PyTorch バージョンはコロンビア大学によって再作成され、オープンソース化されており、1,000 個以上のスターが付いています。
記事の紹介:ちょうど今、コロンビア大学のシステム生物学の助教授、モハメッド・アルクライシ氏が Twitter で、OpenFold と呼ばれるモデルをゼロからトレーニングしたと発表しました。これは、AlphaFold2 のトレーニング可能な PyTorch 再現バージョンです。 Mohammed AlQuraishi 氏は、これが一般に入手可能な AlphaFold2 の最初の複製であるとも述べました。 AlphaFold2 は、複数の配列アラインメントと深層学習アルゴリズムを活用するように設計されたテクノロジーを使用し、タンパク質構造に関する物理的および生物学的知識と組み合わせて、予測を向上させることで、原子の精度でタンパク質構造を定期的に予測できます。タンパク質の 2/3 構造の予測において優れた結果を達成します。
2023-04-13
コメント 0
1206

Python での機械学習モデル評価のヒント
記事の紹介:機械学習は、現実世界の問題を解決する際にモデルのパフォーマンスを頻繁にテストして評価する必要がある、多数の技術や手法を含む複雑な分野です。機械学習モデルの評価テクニックは、開発者がモデルがいつ信頼できるか、また特定のデータセットでどのように機能するかを判断するのに役立つため、Python の非常に重要なスキルです。ここでは、Python での一般的な機械学習モデルの評価手法をいくつか紹介します。 相互検証 相互検証は、機械学習アルゴリズムのパフォーマンスを評価するために一般的に使用される統計手法です。データセットはトレーニングに分割されています
2023-06-10
コメント 0
1670

4 ビット浮動小数点量子化をサポートする最初の LLM は、LLaMA、BERT などの展開上の問題を解決するために登場しました。
記事の紹介:大規模言語モデル (LLM) 圧縮は常に大きな注目を集めており、トレーニング後の量子化 (Post-training Quantization) は一般的に使用されるアルゴリズムの 1 つですが、既存の PTQ 手法のほとんどは整数量子化であり、ビット数が量子化後は 8 未満です。モデルの精度は大幅に低下します。整数 (INT) 定量化と比較して、浮動小数点 (FP) 定量化はロングテール分布をより適切に表現できるため、FP 定量化をサポートするハードウェア プラットフォームが増えています。この記事では、大規模モデルの FP 定量化のソリューションを提供します。この記事はEMNLP2023に掲載されました。論文アドレス: https://arxiv.org/abs/2310.16
2023-11-18
コメント 0
1122

Xiaomi Night Owl アルゴリズムのおかげで、Redmi K70 Pro の夜間撮影パフォーマンスが大幅に向上しました
記事の紹介:11月27日のニュースによると、Redmiは最近最新の携帯電話K70Proをリリースしました。この携帯電話は、OIS 光学手ぶれ補正技術を搭載しているだけでなく、Xiaomi が開発した Night Owl アルゴリズムを初めて導入し、ユーザーに前例のない夜間撮影体験を提供します。編集者の理解によると、Night Owl アルゴリズムはもともとデビューしたものですXiaomi 11 Ultra の重要な機能です。このアルゴリズムは、夜間撮影における一般的なノイズ問題の解決に焦点を当てており、独自に開発した夜景ノイズ校正システムを通じて、夜景ノイズの分布と形状を正確に数学的にモデリングします。 Night Owl アルゴリズムの効果を向上させるために、Xiaomi のエンジニアリング チームは、シミュレーションにノイズを追加することでシミュレートされたノイズ データの多様性を高める革新的な方法を採用しました。これにより、アルゴリズムのトレーニング データが強化され、ノイズ除去プロセスが強化されます。
2023-11-27
コメント 0
1646

強化学習とその応用シナリオを理解する
記事の紹介:犬を訓練する最良の方法は、ご褒美システムを使用して、良い行動にはご褒美を与え、悪い行動には罰を与えることです。同じ戦略は、強化学習と呼ばれる機械学習にも使用できます。強化学習は、問題に対する最適な解決策を見つけるための意思決定を通じてモデルをトレーニングする機械学習の分野です。モデルの精度を向上させるために、正の報酬を使用してアルゴリズムが正解に近づくように促し、負の報酬を使用して目標からの逸脱を罰することができます。目標を明確にしてからデータをモデル化するだけで、モデルはデータとの対話を開始し、手動介入なしで独自にソリューションを提案します。強化学習の例 犬のトレーニングを例に挙げると、犬用ビスケットなどのご褒美を与えて犬にさまざまな動作をさせます。犬は一定の戦略に従って報酬を追求するため、命令に従い、おねだりなどの新しい行動を学習します。
2024-01-22
コメント 0
1377

チャイナユニコム、テキストから画像やビデオクリップを生成できる大規模な画像およびテキストAIモデルをリリース
記事の紹介:中国ニュースを牽引する2023年6月28日、上海で開催中のモバイルワールドコングレス期間中の本日、チャイナユニコムはグラフィックモデル「Honghu Graphic Model 1.0」をリリースした。チャイナユニコムは、Honghuグラフィックモデルは通信事業者の付加価値サービス向けの初の大型モデルであると述べた。 China Business Newsの記者は、Honghuのグラフィックモデルには現在、8億個のトレーニングパラメータと20億個のトレーニングパラメータの2つのバージョンがあり、テキストベースの画像、ビデオ編集、画像ベースの画像などの機能を実現できることを知りました。さらに、チャイナユニコムの劉立紅会長も本日の基調講演で、生成型AIは発展の特異点を到来させており、今後2年間で雇用の50%が人工知能によって大きな影響を受けるだろうと述べた。
2023-06-29
コメント 0
1476

