
AIxiv コラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com。
参照画像セグメンテーション (RIS) は、非常に困難なマルチモーダル タスクであり、アルゴリズムがきめ細かい人間の言語を同時に理解できる必要があります。視覚的な画像情報と、画像内の文によって参照されるオブジェクトをピクセル レベルでセグメント化します。 RIS テクノロジーのブレークスルーは、人間とコンピューターのインタラクション、画像編集、自動運転などの多くの分野に革命的な変化をもたらすことが期待されています。人間とマシンのコラボレーションの効率とエクスペリエンスを大幅に向上させることができます。現在の最先端の RIS アルゴリズムは大幅な進歩を遂げていますが、依然としてモダリティ ギャップの問題、つまり画像とテキストの特徴の分布が完全に一致していないという問題に直面しています。この問題は、複雑な参照言語表現やまれな文脈を扱う場合に特に深刻です。 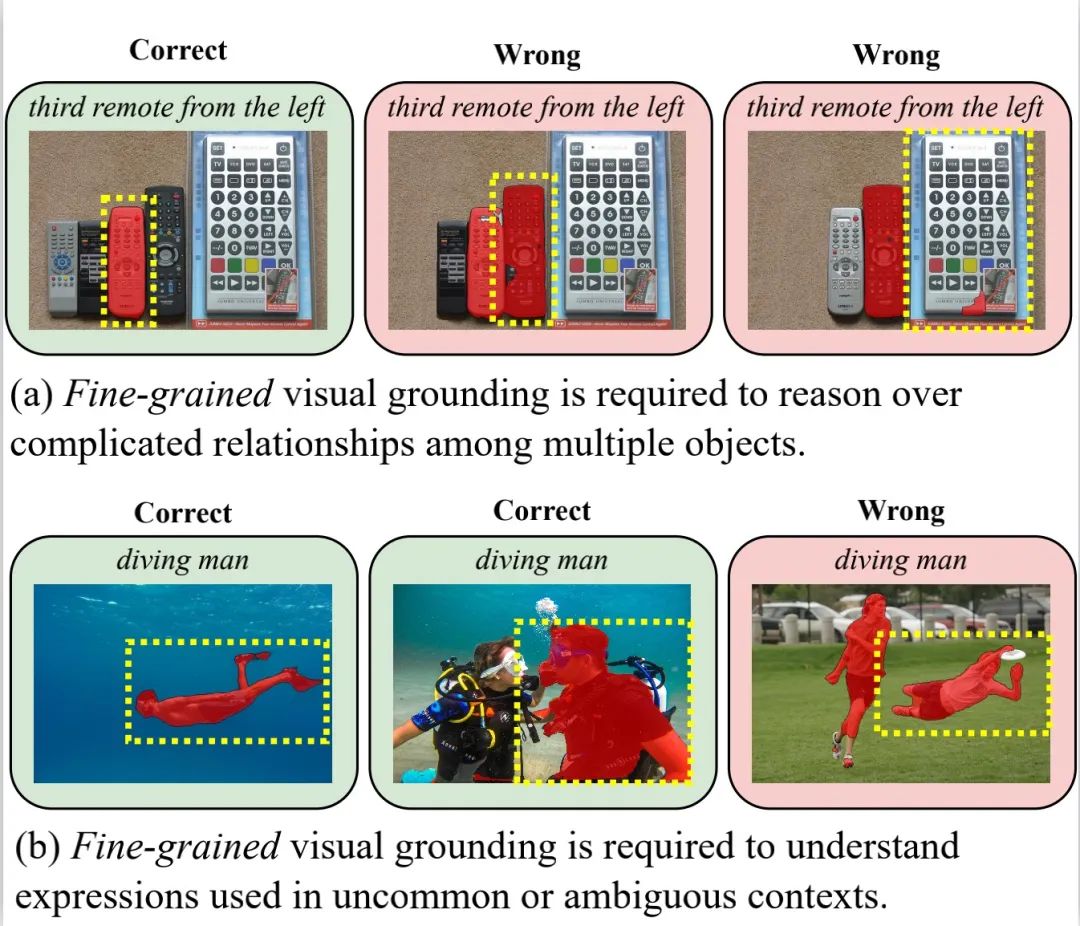
図 1: RIS におけるきめ細かい言語とイメージの調整機能の重要性を示す概略図。赤いマスクは、現在最も先進的な RIS アルゴリズムの 1 つである LAVT の予測結果であり、黄色の点線のボックスは正しいアノテーションです。 現在の RIS の研究は、主に、新しい損失関数の設計、または言語とイメージの分散調整を強化するための革新的なネットワーク アーキテクチャ/モジュールの導入に焦点を当てています。大きな進歩にもかかわらず、2 つの基本的な問題が残っており、その結果、詳細な視覚的基礎付けが不十分になります: # 1. これらの方法は、主に言語の文レベルの言語機能に依存しています。画像の位置合わせが行われるため、テキスト レベルでの言語と画像の位置合わせ機能が弱くなります。
2. これらの方法では、トレーニング プロセス中に明示的な監視信号が不足していることが多く、モデルに詳細な調整を実行するように効果的に教えることができないため、複雑な参照言語を処理する際のパフォーマンスが低下します。
清華大学オートメーション学部とボッシュ中央研究所の共同研究チームは、最近のCVPR 2024の研究で、新しい補助タスク「マスク」を設計しました。接地。このタスクの目的は、テキスト単語の一部をランダムにマスクし、アルゴリズムにそれらの本当のアイデンティティを予測することを学習させることで、テキストと視覚オブジェクトの間のきめ細かい対応関係を学習するようにモデルに明示的に教えることです。さらに、言語と画像間のモーダルギャップをさらに包括的に削減するための、新しいクロスモーダルアライメントモジュールと新しいクロスモーダルアライメントロス関数(クロスモーダルアライメントロス)も提案しました。これらのテクノロジーに基づいて、新しいインスタンス セグメンテーション ネットワーク アーキテクチャである Mask-grounded Network (MagNet) を設計しました。 論文タイトル: 参照画像セグメンテーションのためのマスクグラウンディング
 論文アドレス: https://arxiv .org/abs/2312.12198
論文アドレス: https://arxiv .org/abs/2312.12198
- RefCOCO、RefCOCO、および G-Ref データセットでは、MagNet は以前のすべての最適アルゴリズムを大幅に上回りました。 Interaction over Union (oIoU) 全体の割合は 2.48 パーセント ポイントと大幅に増加しました。視覚化の結果は、MagNet が複雑なシーンや言語表現の処理において優れたパフォーマンスを備えていることも確認しています。
##MagNet は 3 つの独立した補完的なもので構成されます。モジュールは、マスク グラウンディング、クロスモーダル アライメント モジュール、クロスモーダル アライメント ロスで構成されます。
図 3 に示すように、入力画像が与えられると、対応する指示表現とセグメンテーション マスクの場合、作成者は文内の特定の単語をランダムに選択し、それらを特別な学習可能なマスク トークンに置き換えます。次に、これらの置換された単語の実際のアイデンティティを予測するためにモデルがトレーニングされます。マスクされたトークンの身元を正しく予測することで、モデルはテキスト内のどの単語が画像のどの部分に対応するかを理解することができ、その過程できめ細かい言語と画像の位置合わせ機能を学習します。この補助タスクを実行するには、まずマスク領域の中心座標が抽出され、2 層 MLP に渡されて、セグメンテーション マスクの特徴がエンコードされます。同時に、線形レイヤーを使用して、言語特徴を画像特徴と同じ次元にマッピングします。次に、これらの特徴は、提案されたマスク トークン予測器を使用して共同処理され、マスク トークンの予測にはアテンション メカニズム モジュールが使用されます。マスク グランディングでは、マスクされた式を処理するために言語エンコーダーを通過する追加の順方向パスが必要ですが、言語エンコーダーが非常に小さいため、全体の計算コストはほとんど無視できます。 2.クロスモーダル アライメント モジュール (CAM)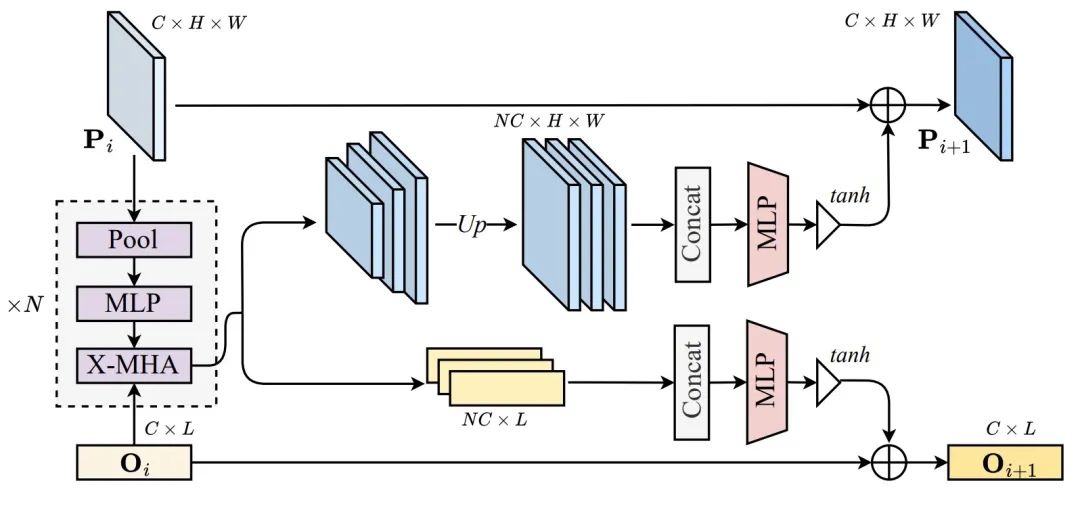
# #図 4 に示すように、モデルのパフォーマンスをさらに向上させるには、著者も提案したクロスモーダル アライメント モジュール モダリティ アライメント モジュール (CAM)。言語と画像の融合を実行する前に、グローバル コンテキスト事前分布を画像特徴に注入することで、言語と画像のアライメントを強化します。 CAM はまず、異なるウィンドウ サイズのプーリング操作を使用して、異なるピラミッド スケールの K 個の特徴マップを生成します。次に、各特徴マップは 3 層 MLP を通過して、グローバル情報をより適切に抽出し、別のモダリティとのクロスアテンション操作を実行します。次に、すべての出力特徴が双一次補間によって元の特徴マップ サイズにアップサンプリングされ、チャネル次元で連結されます。その後、2 層 MLP を使用して、連結されたフィーチャ チャネルの数を元のサイズに戻します。マルチモーダル信号が元の信号を圧倒するのを防ぐために、タン非線形性を持つゲート ユニットを使用して最終出力を変調します。最後に、このゲートされた特徴は入力特徴に追加され、画像または言語エンコーダーの次の段階に渡されます。著者らの実装では、CAM は画像および音声エンコーダの各段階の最後に追加されます。 # #図 5: クロスモーダル アライメント損失の式 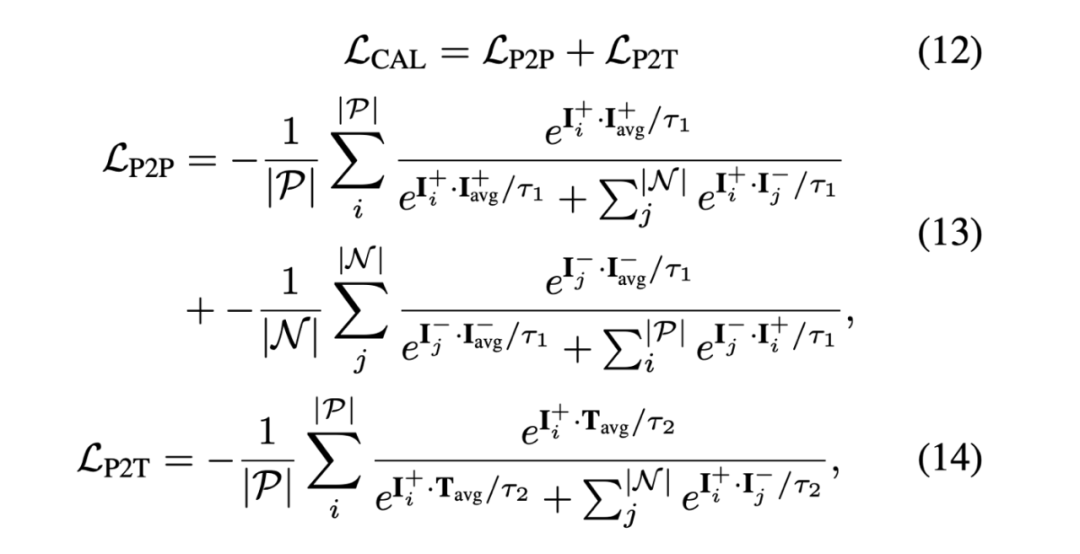
言語と画像の特徴のモデルの整合性を監視するために、著者は新しい交差を提案します。 -modal アライメント損失の式 状態アライメント損失関数 (CAL)。図 5 に、この損失関数の数式を示します。以前の作品とは異なり、CAL ではピクセルからピクセル (P2P) とピクセルからテキスト (P2T) の両方の位置合わせが考慮されます。正確なピクセル間の位置合わせにより、モデルは正確な形状と境界を持つセグメンテーション マスクをセグメント化して出力できるようになります。一方、正確なピクセル間の位置合わせにより、モデルはテキストの説明と一致する画像領域を正しく関連付けることができます。
表 1 では、著者は oIoU メトリクスを使用して MagNet を評価しています。既存の最先端アルゴリズムとのパフォーマンスの比較。テストデータはRefCOCO、RefCOCO、G-Refです。単一データセット設定と複数/追加データセット設定の両方で、MagNet のパフォーマンスはこれらのデータセット上ですべて SOTA です。
# 可能  ## 図 6 では、MagNet の可視化結果がも際立っており、多くの困難なシナリオにおけるベースライン LAVT。
## 図 6 では、MagNet の可視化結果がも際立っており、多くの困難なシナリオにおけるベースライン LAVT。
この記事では、参照セグメンテーション (RIS) の分野の課題について詳しく説明します。そして現在の問題、特に言語とイメージをきめ細かく調整する際の欠点。これらの問題に対応して、清華大学とボッシュ中央研究所の研究者は、MagNet と呼ばれる新しい方法を提案しました。これは、補助タスクであるマスク グランディング、クロスモーダル アライメント モジュール、およびクロスモーダル アライメント損失関数を導入することで言語を包括的に改善します。画像間の位置合わせ効果。実験では、MagNet が RefCOCO、RefCOCO、および G-Ref データ セットで大幅に優れたパフォーマンスを達成し、以前の最先端のアルゴリズムを上回り、強力な一般化機能を示していることが証明されています。視覚化の結果は、複雑なシーンや言語表現の処理における MagNet の優位性も裏付けています。この研究は、参照セグメンテーションの分野のさらなる発展に有益なインスピレーションを提供し、この分野でのさらなる進歩を促進することが期待されています。
この論文は清華大学オートメーション学科からのものです ( https://www.au.tsinghua.edu.cn) およびボッシュ中央研究所 (https://www.bosch.com/research/)。論文の最初の著者の一人である Zhuang Rongxian 氏は、清華大学の博士課程の学生であり、ボッシュ中央研究所のインターンです。プロジェクトリーダーは、ボッシュ中央研究所の上級研究開発科学者である Qiu Xuchong 博士です。著者は清華大学オートメーション学科の黄高教授です。
以上がCVPR 2024 | 複雑なシーンと言語表現の処理が得意な清華&ボッシュは、新しいインスタンス セグメンテーション ネットワーク アーキテクチャを提案しました MagNetの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



