


信号機、誘導標識、トラフィック コーンなどの静的物体検出 (SOD) のほとんどのアルゴリズムはデータ駆動型のディープ ニューラル ネットワークであり、大量のトレーニングデータ。現在の実践では、ロングテールのケースを修正するために、LiDAR でスキャンした点群データ上の多数のトレーニング サンプルに手動でアノテーションを付けることが一般的に行われています。

手動のアノテーションでは、実際のシーンの変動性と複雑性を捉えるのが難しく、オクルージョン、さまざまな照明条件、さまざまな視野角を考慮できないことがよくあります (図 1 の黄色の矢印)。 。 プロセス全体には長いリンクがあり、非常に時間がかかり、エラーが発生しやすく、コストがかかります (図 2)。 したがって、現在企業は、特に純粋なビジョンに基づいた自動ラベル付けソリューションを探しています。結局のところ、すべての車に LiDAR が搭載されているわけではありません。
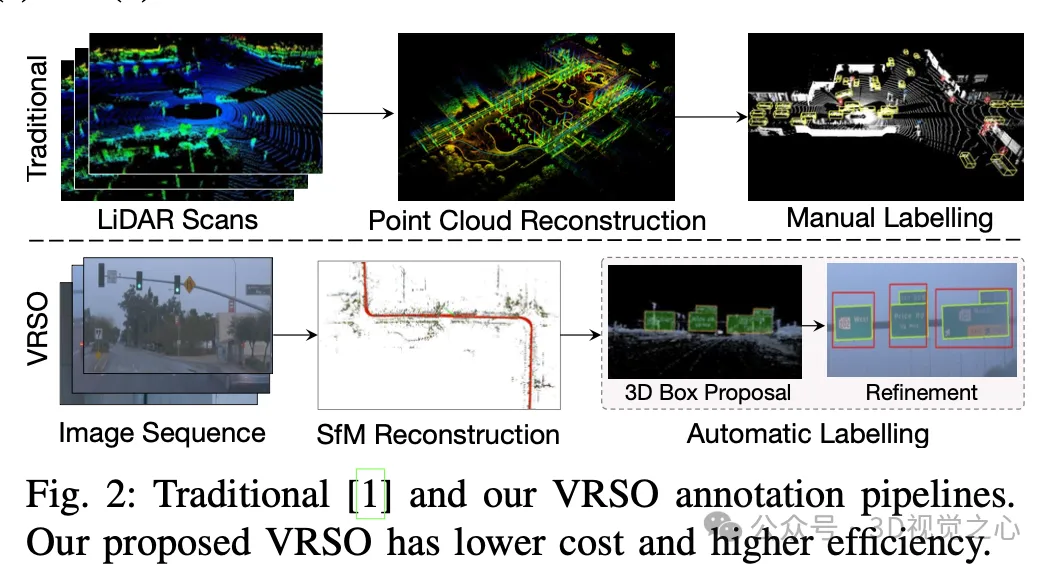
VRSO は、静的オブジェクト アノテーション用のビジョンベースのアノテーション システムです。主に SFM、2D オブジェクト検出、インスタンス セグメンテーションの結果からの情報を使用します。全体的な効果:
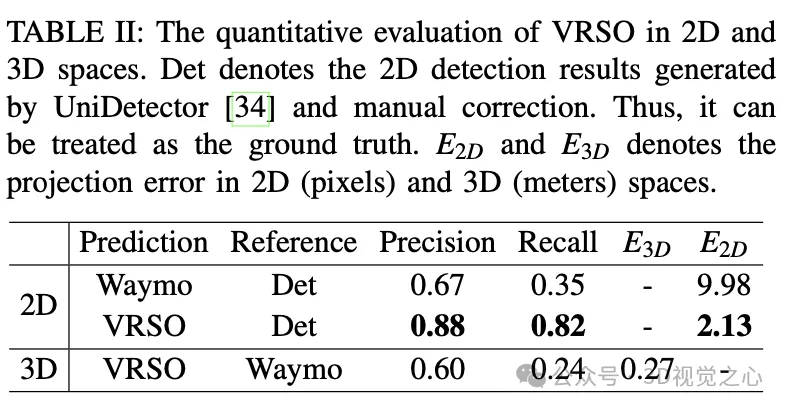
静的オブジェクトの場合、VRSO は、インスタンスのセグメンテーションとキーポイントの輪郭抽出を通じて、さまざまな視野角からの静的オブジェクトの統合と重複除去という課題、およびオクルージョンの問題による不十分な観察の困難を解決します。により、ラベルの精度が向上します。 図 1 より、Waymo Open データセットの手動アノテーション結果と比較して、VRSO はより高い堅牢性と幾何学的精度を示しています。
(皆さんもこれを見たことがあるでしょう。親指を上にスライドさせて一番上のカードをクリックして私をフォローしてみてはいかがでしょうか。 操作全体にかかる時間は 1.328 秒だけです。将来役立つ情報をすべてお届けします。うまくいったらどうなるか~)
VRSO システムは主に 2 つの部分に分かれています。 シーン再構成 および 静的オブジェクトには のマークが付けられます。
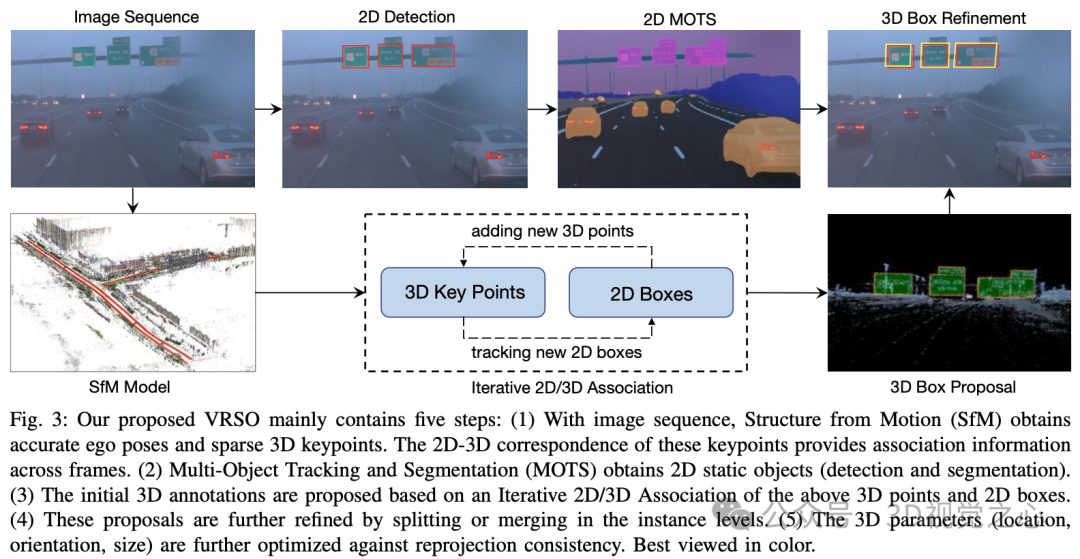
#再構築部分は焦点ではなく、SFM アルゴリズムに基づいて画像の姿勢とまばらな 3D キー ポイントを復元します。
静的オブジェクト アノテーション アルゴリズムと疑似コードの組み合わせの一般的なプロセスは次のとおりです (以下で段階的に詳しく説明します):

ビデオ クリップ全体の静的オブジェクトの 3D フレーム パラメーター (位置、方向、サイズ) を初期化します。 SFM の各キー ポイントには、正確な 3D 位置と対応する 2D 画像があります。 2D インスタンスごとに、2D インスタンス マスク内の特徴点が抽出されます。次に、対応する 3D キーポイントのセットを 3D 境界ボックスの候補として考慮できます。
道路標識は空間内の方向をもつ長方形として表され、移動 (,,)、方向 (θ)、サイズ (幅と高さ) を含む 6 つの自由度があります。その奥行きを考慮すると、信号機には 7 つの自由度があります。トラフィック コーンは信号機と同様に表されます。
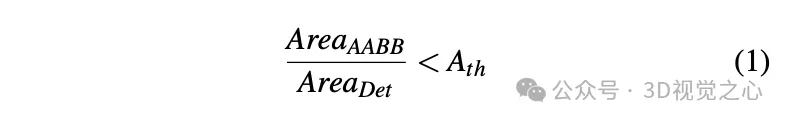
三角形分割を通じて 3D 条件下で静的オブジェクトの初期頂点値を取得します。
シーン再構築中に SFM とインスタンス セグメンテーションによって取得された 3D バウンディング ボックス内のキーポイントの数をチェックすることにより、キーポイントの数がしきい値を超えるインスタンスのみが、安定した有効な観測であると見なされます。これらのインスタンスでは、対応する 2D 境界ボックスが有効な観測値とみなされます。複数の画像の 2D 観察を通じて、2D バウンディング ボックスの頂点が三角形分割され、バウンディング ボックスの座標が取得されます。
マスク上の「左下、左上、右上、右上、および右下」の頂点を区別しない円形標識の場合、これらの円形標識を識別する必要があります。 2D 検出結果は円形オブジェクトの観察として使用され、2D インスタンス セグメンテーション マスクは輪郭抽出に使用されます。中心点と半径は、最小二乗フィッティング アルゴリズムを通じて計算されます。円形標識のパラメータには、中心点 (,,)、方向 (θ)、半径 () が含まれます。
SFMに基づいて特徴点マッチングを追跡します。 3D バウンディング ボックスの頂点と 2D バウンディング ボックスの投影 IoU のユークリッド距離に基づいて、これらの分離されたインスタンスをマージするかどうかを決定します。マージが完了すると、インスタンス内の 3D 特徴点をクラスタリングして、より多くの 2D 特徴点を関連付けることができます。 2D 特徴点を追加できなくなるまで、反復的な 2D-3D 関連付けが実行されます。
長方形の記号を例に挙げると、最適化できるパラメータには位置 (,,) と方向 (θ) が含まれます。 ) とサイズ (,)、合計 6 つの自由度。主な手順は次のとおりです。



以上が効率16倍アップ! VRSO: 純粋に視覚的な静的オブジェクトの 3D アノテーションにより、データの閉ループが開かれます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



