



mentalimage#大規模言語モデル (LLM) は、言語理解とさまざまな推論タスクにおいて優れたパフォーマンスを示します。しかし、人間の認知の重要な側面である空間推論におけるそれらの役割は、依然として十分に研究されていません。人間には、心の目として知られるプロセスを通じて、目に見えない物体や行動の精神的なイメージを作成する能力があり、目に見えない世界を想像することが可能になります。この認知能力に触発されて、研究者たちは「思考の視覚化 (VoT)」 を提案しました。 VoT は、LLM の推論の兆候を視覚化することで LLM の空間推論をガイドし、それによって後続の推論ステップをガイドすることを目的としています。研究者らは、VoT を、自然言語ナビゲーション、視覚ナビゲーション、2 次元グリッド世界での視覚舗装などのマルチホップ空間推論タスクに適用しました。 実験結果は、VoT が LLM の空間推論能力を大幅に強化することを示しています。特に、VoT は、これらのタスクに関して既存のマルチモーダル大規模言語モデル (MLLM) よりも優れたパフォーマンスを発揮します。 はじめに 近年、大規模言語モデル (LLM) は、さまざまな言語関連のタスクで目覚ましいパフォーマンスを達成しています。彼らは数学的推論、常識的推論、および記号的推論や論理的推論などの他の推論タスクでは成功しているにもかかわらず、空間的推論における能力は依然として解明されていません。 空間推論は人間の認識の基本的な機能です。
これにより、私たちは環境と対話することができます。これにより、オブジェクトとその動きの間の空間的関係についての理解と推論が必要なタスクが容易になります。言語モデルの空間推論は、空間情報について推論するために言語に大きく依存しており、人間の認知能力は言語推論をはるかに超えています。人間は、視覚的な認識からタスクに関連した抽象的な表現を作成できるだけでなく、心の目を通して目に見えないシーンを想像することもできます。これは、神経科学、心の哲学、認知科学の分野で
図 1: 人間は、空間推論中に精神的なイメージを作成することで、空間認識を強化し、意思決定を導くことができます。同様に、大規模言語モデル (LLM) は内部の精神的なイメージを構築できます。研究者らは、各中間ステップで LLM の思考を視覚化することで LLM の「心の目」を引き起こし、それによって空間的推論を促進する VoT を提案しました。 この認知メカニズムに触発されて、研究者らは、LLM には空間推論のために心の目の中で心的イメージを作成および操作する能力があると推測しています。図 1 に示すように、LLM はさまざまな形式の空間情報を処理および理解できる可能性があります。彼らは内部状態を視覚化し、心の目を通してこれらの心的イメージを操作して、空間的推論を強化するためのその後の推論ステップを導くことができるかもしれません。したがって、研究者らは、この能力を引き出すための 思考の視覚化 (VoT)
プロンプトを提案しました。この方法では、視覚空間スケッチパッドを LLM に追加して、推論ステップを視覚化し、後続のステップをガイドします。 VoT は、少数のデモンストレーションに依存したり、テキストから画像への視覚化に CLIP を使用したりするのではなく、デモンストレーション プロンプトを一切使用しません。この選択は、テキストベースのビジュアル アートからさまざまな心的イメージを取得する LLM の能力に由来しています。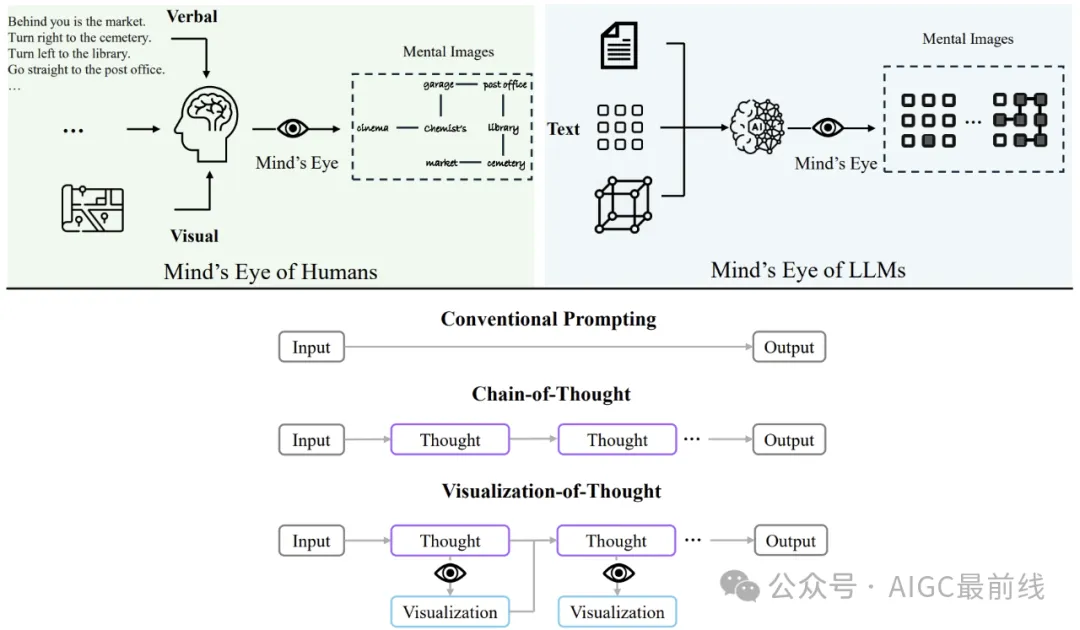 空間推論における VoT の有効性を評価するために、研究者らは、
空間推論における VoT の有効性を評価するために、研究者らは、
を含む、LLM の空間認識を必要とする 3 つのタスクを選択しました。これらのタスクでは、空間的、方向的、および幾何学的形状の推論を理解する必要があります。人間のような多感覚知覚をシミュレートするために、研究者らは、LLM の視覚ナビゲーションおよび視覚敷設タスクで豊富な入力形式として特殊文字を使用する 2D グリッド世界を設計しました。これら 3 つのタスクについて、さまざまなモデル (GPT-4、GPT-4V) とプロンプト手法を比較しました。研究結果によると、
VoT プロンプトは一貫して LLM に推論ステップを視覚化し、後続のステップをガイドするよう促します。したがって、この方法では、対応するタスクのパフォーマンスが大幅に向上します。
図 2: さまざまな設定でのナビゲーション マップの例。家の絵文字が出発地を表し、オフィスの絵文字が目的地を表しています。 空間的推論とは、オブジェクト間の空間的関係、その動き、相互作用を理解し推論する能力を指します。このスキルは、ナビゲーション、ロボット工学、自動運転など、現実世界の幅広いアプリケーションにとって重要です。これらの領域では、視覚認識と空間次元の詳細な理解に基づいた行動計画が必要です。テキストに埋め込まれた空間意味論を調査するためにいくつかのタスクとデータセットが開発されていますが、研究努力は一般に、空間用語が言語的にどのように構造化されているかに焦点を当てています。最近、空間用語を論理形式に変換し、論理プログラミングを採用することによって、これらのベンチマークで重要な成果と印象的な結果が達成されました。これは、これらのタスクをうまく実行しても、必ずしも大規模言語モデル (LLM) が空間情報を真に理解していることを意味するわけではなく、空間認識の正確な尺度を提供するわけでもないことを意味します。空間認識には、空間関係、方向、距離、幾何学を理解することが含まれます。これらは、物理世界での行動を計画するために不可欠です。 LLM の空間認識能力と空間推論能力を評価するために、研究者らは、自然言語ナビゲーション、視覚ナビゲーション、視覚舗装など、ナビゲーションと幾何学的推論のスキルをテストするいくつかのタスクを選択しました。 自然言語ナビゲーションには、以前に訪問した場所を特定することを目的として、ランダム ウォークを通じて基礎となる空間構造を参照することが含まれます。このコンセプトは、グラフ構造に沿ったランダム ウォークに似たアプローチを使用した、人間の認知に関する以前の研究からインスピレーションを得ています。このプロセスでは、空間ナビゲーションにとって重要なループ クロージャーを理解する必要があります。 思考視覚的なヒント
空間的推論
自然言語ナビゲーション

ビジュアル ナビゲーション タスクでは、LLM に合成 2D グリッドの世界を提示し、視覚的な手がかりのナビゲートを活用するように要求します。モデルは、障害物を回避しながら開始点から目的地まで 4 方向 (左、右、上、下) に移動するためのナビゲーション命令を生成する必要があります。これには、ルート計画と次のステップの予測という 2 つのサブタスクが含まれます。これらにはマルチホップの空間推論が必要ですが、前者の方がより複雑です。

ビジュアル タイル化は、古典的な空間推論の課題です。この概念を拡張して、限られた領域内の形状を理解し、整理し、推論する LLM の能力をテストすると、空間推論スキルの評価が強化されます。このタスクには、塗りつぶされていないセルを含む長方形と、4 つの整列した正方形で構成される I-ドミノ ブロックなどのさまざまなドミノ ブロックが含まれます。モデルは、質疑応答パズルを解くために、I-domino ブロックの方向を選択するなど、適切なドミノ ブロックのバリエーションを選択する必要があります。

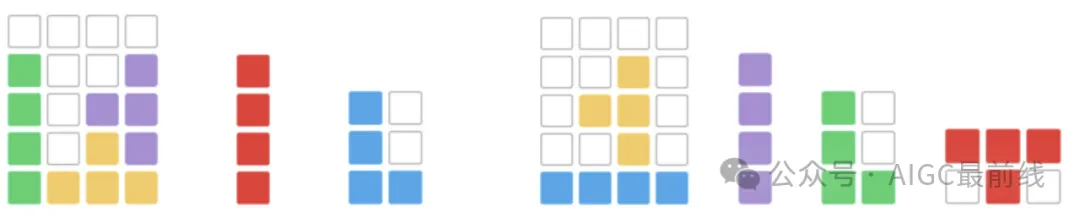 # 図 3: マスクされたドミノ ブロックを使用した視覚的な配置の例。この画像には、ドミノ ブロックの回転およびミラー化されたバリエーションは示されていません。
# 図 3: マスクされたドミノ ブロックを使用した視覚的な配置の例。この画像には、ドミノ ブロックの回転およびミラー化されたバリエーションは示されていません。 人間がナビゲーションなどのタスクで空間情報を処理する方法を考えると、地図などの心的イメージは空間を強化するために作成されることがよくあります。意思決定を導くための認識またはシミュレートされた動き。研究の目標は、LLM の空間認識を喚起し、中間推論ステップを視覚化することで実際の状況に基づいた推論を可能にすることです。
研究者は、「思考の視覚化 (VoT)」というプロンプトを導入しました。「各推論ステップ後の状態を視覚化します。」この新しい空間推論パラダイムは、推論記号と視覚化結果を交互に生成することを目的としています。

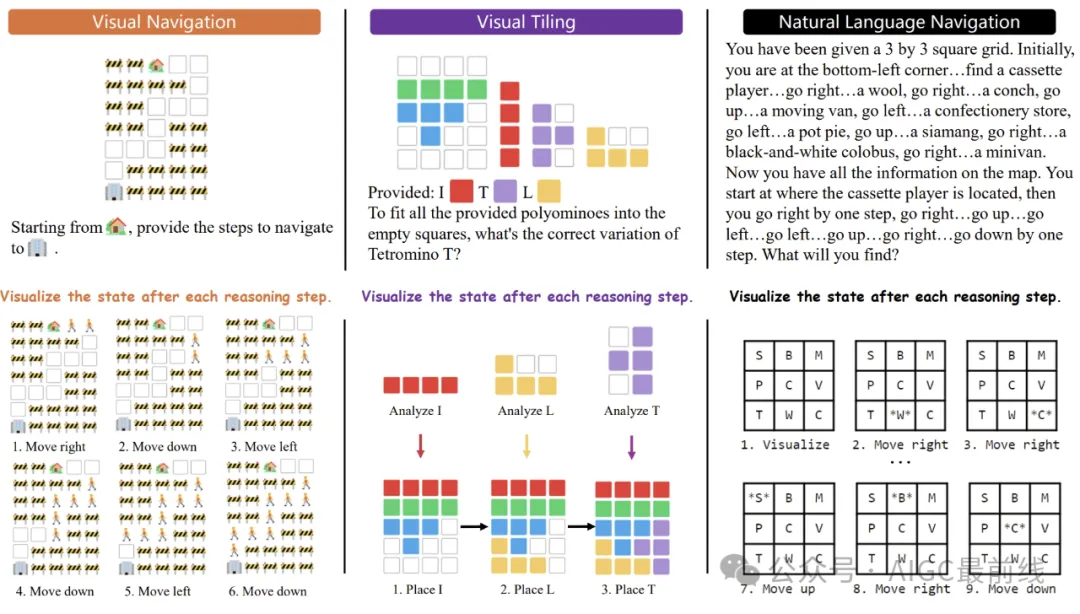 図 4: LLM が交互に追跡する推論記号と視覚化を生成する 3 つのタスクにおける VoT プロンプトの例時間の経過とともに変化する状態。
図 4: LLM が交互に追跡する推論記号と視覚化を生成する 3 つのタスクにおける VoT プロンプトの例時間の経過とともに変化する状態。  論文: https://arxiv.org/pdf/2404.03622.pdf
論文: https://arxiv.org/pdf/2404.03622.pdf
以上が大規模言語モデルの空間推論能力を刺激する: 思考の視覚化のヒントの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



