


大規模な言語モデルの可能性が刺激される -
大規模な言語モデルをトレーニングすることなく、従来のすべての時系列モデルを超える高精度の時系列予測を実現できます。
モナシュ大学、Ant、IBM Research は共同で、モダリティ全体で配列データを処理する大規模言語モデルの機能を促進する一般的なフレームワークを開発しました。このフレームワークは重要な技術革新となっています。

時系列予測は、都市、エネルギー、交通、リモート センシングなどの典型的な複雑なシステムにおける意思決定に役立ちます。
それ以来、大規模モデルは時系列/時空間データマイニングの方法を完全に変えることが期待されています。
研究チームは、トレーニングなしで一般的な時系列予測に大規模言語モデルを簡単に使用するための一般的なフレームワークを提案しました。
主に 2 つの主要なテクノロジを提案します: タイミング入力再プログラミング、プロンプト プレフィックス。
Time-LLM は、まずテキスト プロトタイプ (テキスト プロトタイプ) を使用して入力時間データを再プログラムし、自然言語表現を使用して時間データの意味情報を表し、次に 2 つの異なるデータ モダリティを調整して、大規模な言語を実現します。モデルは、変更を加えることなく、別のデータ モダリティの背後にある情報を理解できます。同時に、大規模な言語モデルでは、さまざまなデータ モダリティの背後にある情報を理解するために特定のトレーニング データ セットを必要としません。この方法により、モデルの精度が向上するだけでなく、データの前処理プロセスも簡素化されます。
入力時系列データの分析とそれに対応するタスクをより適切に処理するために、著者は Prompt-as-Prefix (PaP) パラダイムを提案しました。このパラダイムは、時間データの表現の前に追加のコンテキスト情報とタスク命令を追加することにより、時間タスクに対する LLM の処理機能を完全にアクティブにします。この方法では、タイミング データ テーブルの前に追加のコンテキスト情報とタスク命令を追加することで、タイミング タスクに関するより洗練された分析を実現し、タイミング タスクに関する LLM の処理機能を完全にアクティブにすることができます。
主な貢献は次のとおりです。
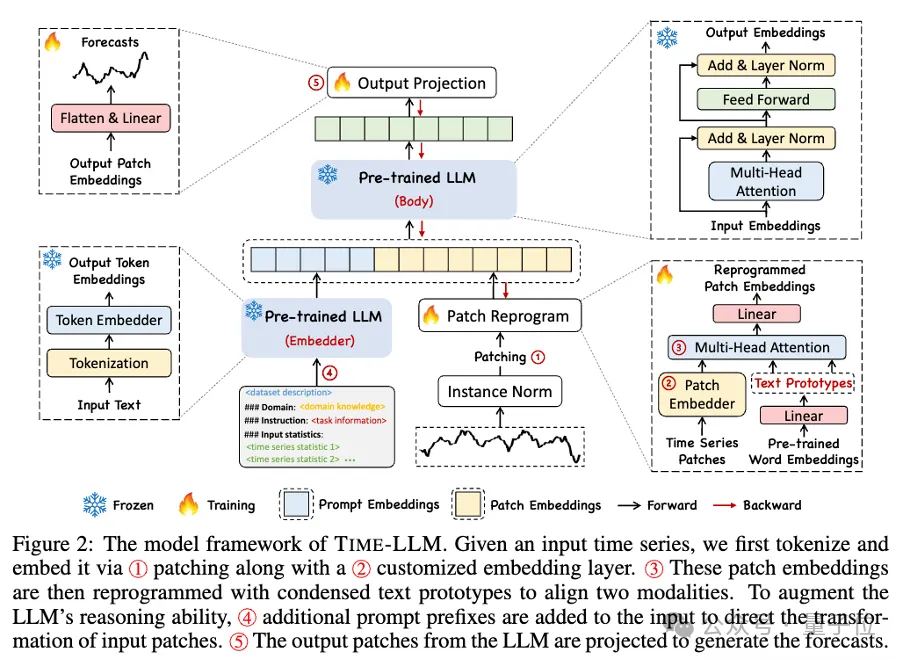
このフレームワークを具体的に見ると、まず、入力時系列データが RevIN によって正規化され、次に異なるパッチに分割されて潜在空間にマッピングされます。
時系列データとテキストデータでは表現方法に大きな違いがあり、異なるモダリティに属します。
時系列を直接編集したり、自然言語でロスレスに記述したりすることはできません。したがって、時間的入力特徴を自然言語テキスト領域に合わせる必要があります。

さまざまなモダリティを調整する一般的な方法は相互注意ですが、LLM に固有の語彙は非常に大きいため、時間的特徴をすべての単語に効果的に直接調整することは不可能ですすべての単語が時系列と意味論的な関係を揃えているわけではありません。
この問題を解決するために、この研究では、語彙の線形結合を実行してテキスト プロトタイプを取得します。テキスト プロトタイプの数は、元の語彙サイズよりもはるかに少なくなります。この組み合わせは、変化する特性を表現するために使用できます。時系列データの。
タイミング タスクを指定する際の LLM の機能を完全にアクティブにするために、この研究ではプロンプト プレフィックス パラダイムを提案しています。
平たく言えば、時系列データ セットの事前情報をプレフィックス プロンプトとして自然言語で入力し、それを調整された時系列特徴と LLM に接続することを意味します。予知効果?
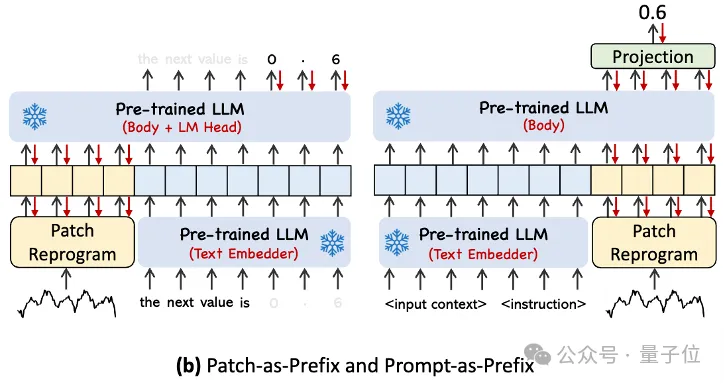
実際には、著者らは効果的なプロンプトを構築するための 3 つの重要なコンポーネントを特定しました:
データセットのコンテキスト; (2) LLM を適切なものにするためのタスクの指示下流タスク; (3) 傾向、遅延などの統計的記述により、LLM は時系列データの特性をより深く理解できるようになります。

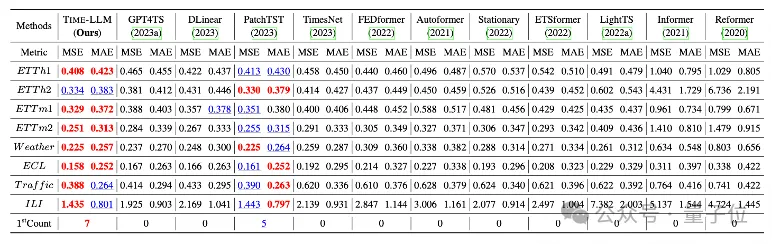
チームは、長期予測のために 8 つの古典的な公開データセットに対して包括的なテストを実施しました。
結果 Time-LLM は、ベンチマーク比較において、この分野におけるこれまでの最高結果を大幅に上回りました。たとえば、GPT-2 を直接使用する GPT4TS と比較して、Time-LLM は大幅に改善されており、この効果が示されています。方法。
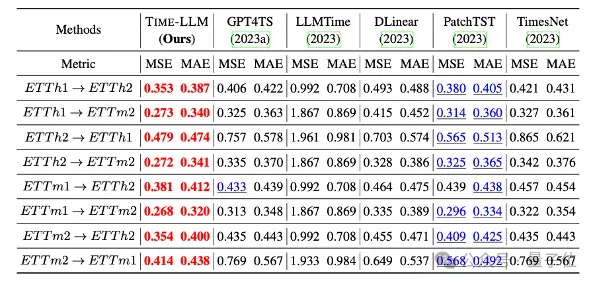
#さらに、ゼロショットシナリオでも強力な予測能力を示します。
このプロジェクトは、Ant Group のインテリジェント エンジン部門の AI イノベーション研究開発部門である NextEvo によってサポートされています。
興味のあるお友達は、下のリンクをクリックして論文の詳細をご覧ください~
論文のリンクhttps://arxiv.org/abs/2310.01728。
以上が大規模モデルは時系列予測にも非常に強力です。中国チームがLLMの新機能を有効にし、従来のモデルを超えたSOTAを達成の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



