


大規模モデルの実装プロセスにおいて、エンドサイド AI は非常に重要な方向性です。
最近、スタンフォード大学の研究者によって発表された Octopus v2 が人気を博し、開発者コミュニティから大きな注目を集めており、このモデルは一晩で 2,000 回以上ダウンロードされました。
20 億パラメータの Octopus v2 はスマートフォン、自動車、PC などで実行でき、精度と遅延の点で GPT-4 を上回り、コンテキストの長さを 95% 削減します。さらに、Octopus v2 は Llama7B RAG スキームより 36 倍高速です。 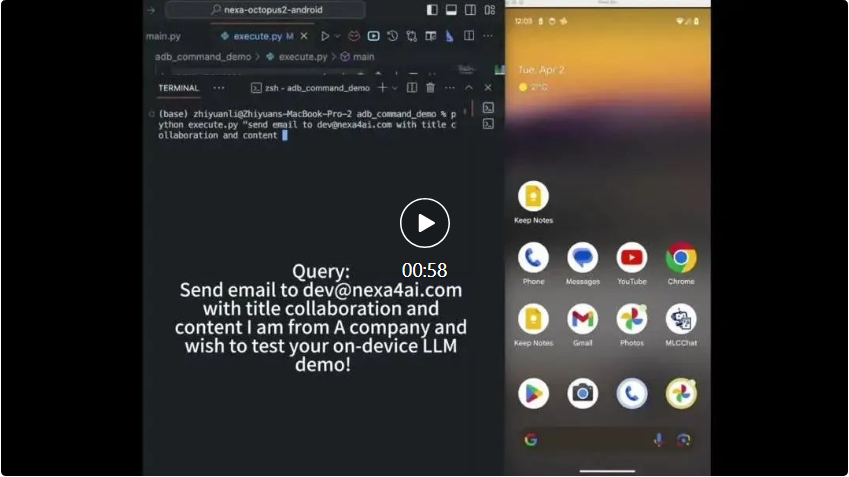

論文: Octopus v2: スーパー エージェントのオンデバイス言語モデル
論文のアドレス: https ://arxiv.org/abs/2404.01744
モデルのホームページ: https://huggingface.co/NexaAIDev/Octopus-v2
モデルの概要
Octopus-V2-2B は、Android API 向けに調整された 20 億のパラメーターを備えたオープンソース言語モデルです。 Android デバイス上でシームレスに実行され、そのユーティリティは Android システム管理から複数のデバイスのオーケストレーションに至るまで、さまざまなアプリケーションに拡張されます。
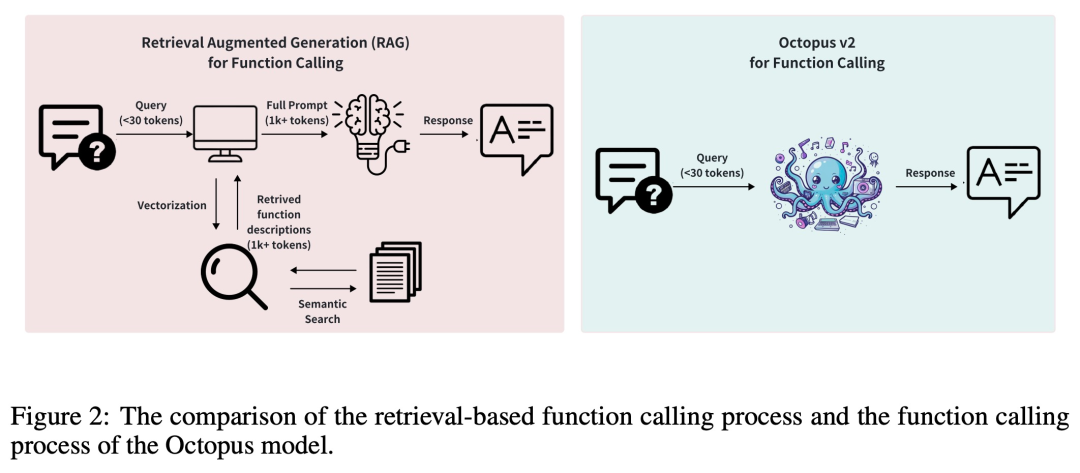
通常、検索拡張生成 (RAG) メソッドでは、潜在的な関数パラメーターの詳細な記述が必要です (最大で数万の入力トークンが必要になる場合もあります)。これに基づいて、Octopus-V2-2B は、トレーニングおよび推論フェーズに独自の関数トークン戦略を導入します。これにより、GPT-4 に匹敵するパフォーマンス レベルを達成できるだけでなく、推論速度が大幅に向上し、RAG ベースを上回ります。これは、エッジ コンピューティング デバイスにとって特に有益です。
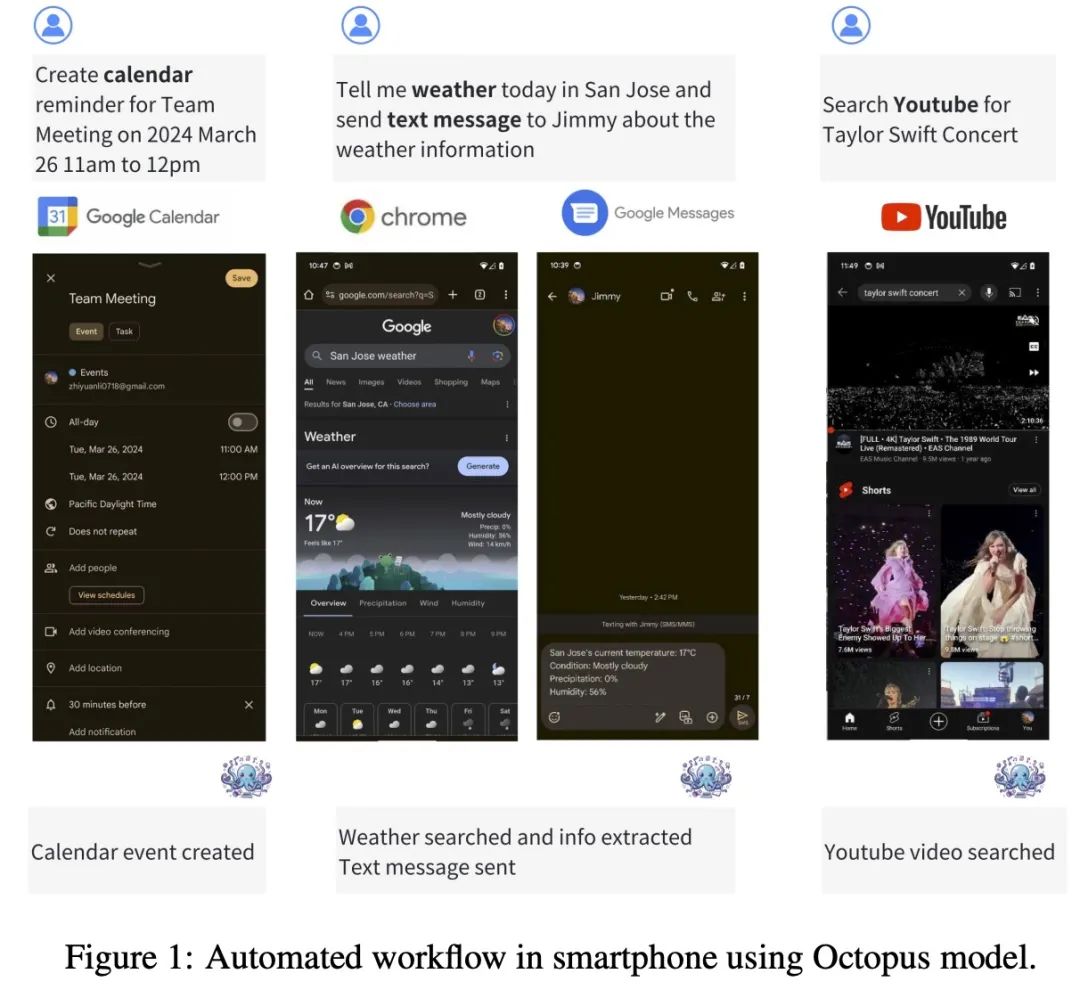
Octopus-V2-2B は、さまざまな複雑なシナリオで個別のネストされた並列関数呼び出しを生成できます。
データセット
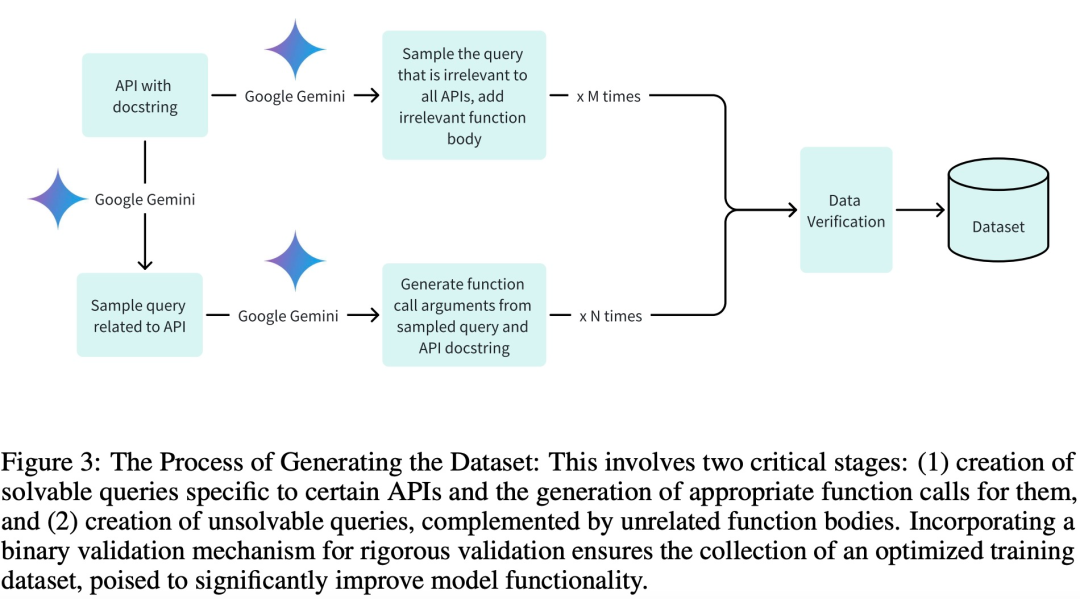
トレーニング、検証、テストのフェーズに高品質のデータセットを採用するため、特に効率的なトレーニングを実現するために、研究チームは次のデータセットを作成しました。 3 つの主要な段階:
関連するクエリとそれに関連する関数呼び出しパラメータを生成する;
適切な関数コンポーネントから無関係なクエリを生成する;
Google Gemini によるバイナリ検証のサポート。
研究チームは、モデルをトレーニングするために 20 の Android API 記述を作成しました。以下は Android API 記述の例です:
def get_trending_news (category=None, region='US', language='en', max_results=5):"""Fetches trending news articles based on category, region, and language.Parameters:- category (str, optional): News category to filter by, by default use None for all categories. Optional to provide.- region (str, optional): ISO 3166-1 alpha-2 country code for region-specific news, by default, uses 'US'. Optional to provide.- language (str, optional): ISO 639-1 language code for article language, by default uses 'en'. Optional to provide.- max_results (int, optional): Maximum number of articles to return, by default, uses 5. Optional to provide.Returns:- list [str]: A list of strings, each representing an article. Each string contains the article's heading and URL. """
モデル開発とトレーニング
この調査では、Google Gemma-2B モデルをフレームワーク内のプリプロセッサ 2 つの異なるトレーニング方法 (フル モデル トレーニングと LoRA モデル トレーニング) を使用してモデルをトレーニングします。
完全なモデル トレーニングでは、このスタディでは AdamW オプティマイザーを使用し、学習率は 5e-5 に設定され、ウォームアップ ステップの数は 10 に設定され、線形学習率スケジューラーが使用されます。
LoRA モデル トレーニングでは、完全なモデル トレーニングと同じオプティマイザーと学習率構成が使用され、LoRA ランクは 16 に設定され、LoRA は次のモジュールに適用されます: q_proj、k_proj、v_proj、o_proj、up_proj、down_proj 。このうち、LoRA alpha パラメータは 32 に設定されています。
どちらのトレーニング方法でも、エポック数は 3 に設定されます。
次のコードを使用すると、単一の GPU で Octopus-V2-2B モデルを実行できます。
from transformers import AutoTokenizer, GemmaForCausalLMimport torchimport timedef inference (input_text):start_time = time.time ()input_ids = tokenizer (input_text, return_tensors="pt").to (model.device)input_length = input_ids ["input_ids"].shape [1]outputs = model.generate (input_ids=input_ids ["input_ids"], max_length=1024,do_sample=False)generated_sequence = outputs [:, input_length:].tolist ()res = tokenizer.decode (generated_sequence [0])end_time = time.time ()return {"output": res, "latency": end_time - start_time}model_id = "NexaAIDev/Octopus-v2"tokenizer = AutoTokenizer.from_pretrained (model_id)model = GemmaForCausalLM.from_pretrained (model_id, torch_dtype=torch.bfloat16, device_map="auto")input_text = "Take a selfie for me with front camera"nexa_query = f"Below is the query from the users, please call the correct function and generate the parameters to call the function.\n\nQuery: {input_text} \n\nResponse:"start_time = time.time () print ("nexa model result:\n", inference (nexa_query)) print ("latency:", time.time () - start_time,"s")評価
Octopus-V2-2B はベンチマーク テストで優れた推論速度を実証し、単一の A100 GPU RAG ソリューションで「Llama7B」を上回りました。 36 倍高速です。さらに、Octopus-V2-2B は、クラスター化された A100/H100 GPU に依存する GPT-4-turbo と比較して 168% 高速です。この効率性の飛躍的な進歩は、Octopus-V2-2B の機能トークン設計によるものです。
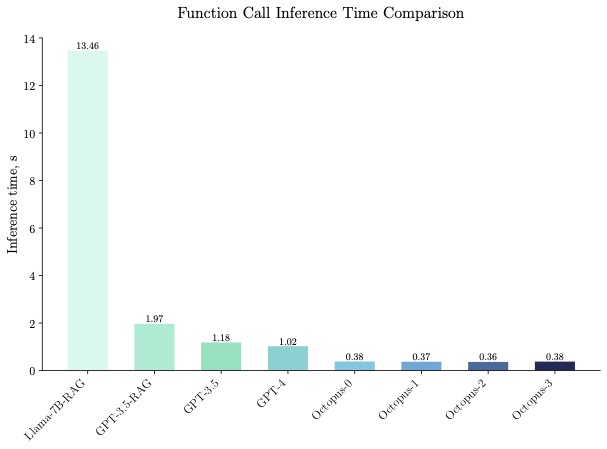
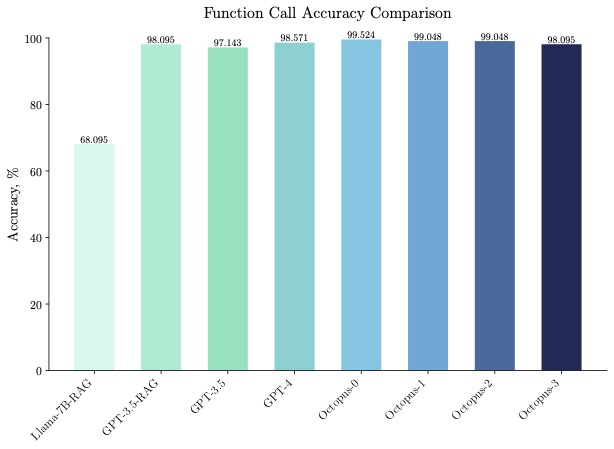
Octopus-V2-2B は速度だけでなく精度も優れており、関数呼び出し精度では「Llama7B RAG ソリューション」を 31% 上回っています。 Octopus-V2-2B は、GPT-4 および RAG GPT-3.5 に匹敵する関数呼び出し精度を実現します。
興味のある読者は、論文の原文を読んで研究内容をさらに詳しく知ることができます。
以上がGPT-4 を超えて、携帯電話で実行できるスタンフォード チームの大規模モデルが人気を博し、一晩で 2,000 件を超えるダウンロードが行われましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



