



3 月 28 日のニュース、LMSYS Org が発表した最新のベンチマーク レポートによると、Claude-3 のスコアは僅差で GPT-4 を上回り、プラットフォームのスコアになりました。 " 「最高の」大規模言語モデル。
このウェブサイトで最初に紹介するのは、カリフォルニア大学バークレー校、カリフォルニア大学サンディエゴ校、カーネギーメロン大学が共同で設立した研究組織である LMSYS Org です。
このシステムは、大規模言語モデル (LLM) のベンチマーク プラットフォームである Chatbot Arena を起動します。これは、クラウドソーシングを使用して大規模モデル製品を匿名かつランダムにテストします。その評価は、チェスのような競技ゲームでの広範な使用に基づいています。Eloスコアリングシステム。
ユーザー投票によって生成された評価結果を通じて、システムは毎回ユーザーとチャットする 2 つの異なる大型モデル ロボットをランダムに選択し、ユーザーはどちらの大型モデル製品のパフォーマンスが優れているかを匿名で選択できるようになります。全体的には比較的公平です。
チャットボット アリーナ 昨年の発売以来、GPT-4 は常にトップの座を堅持しており、大規模モデルを評価するためのゴールドスタンダードにもなりました。
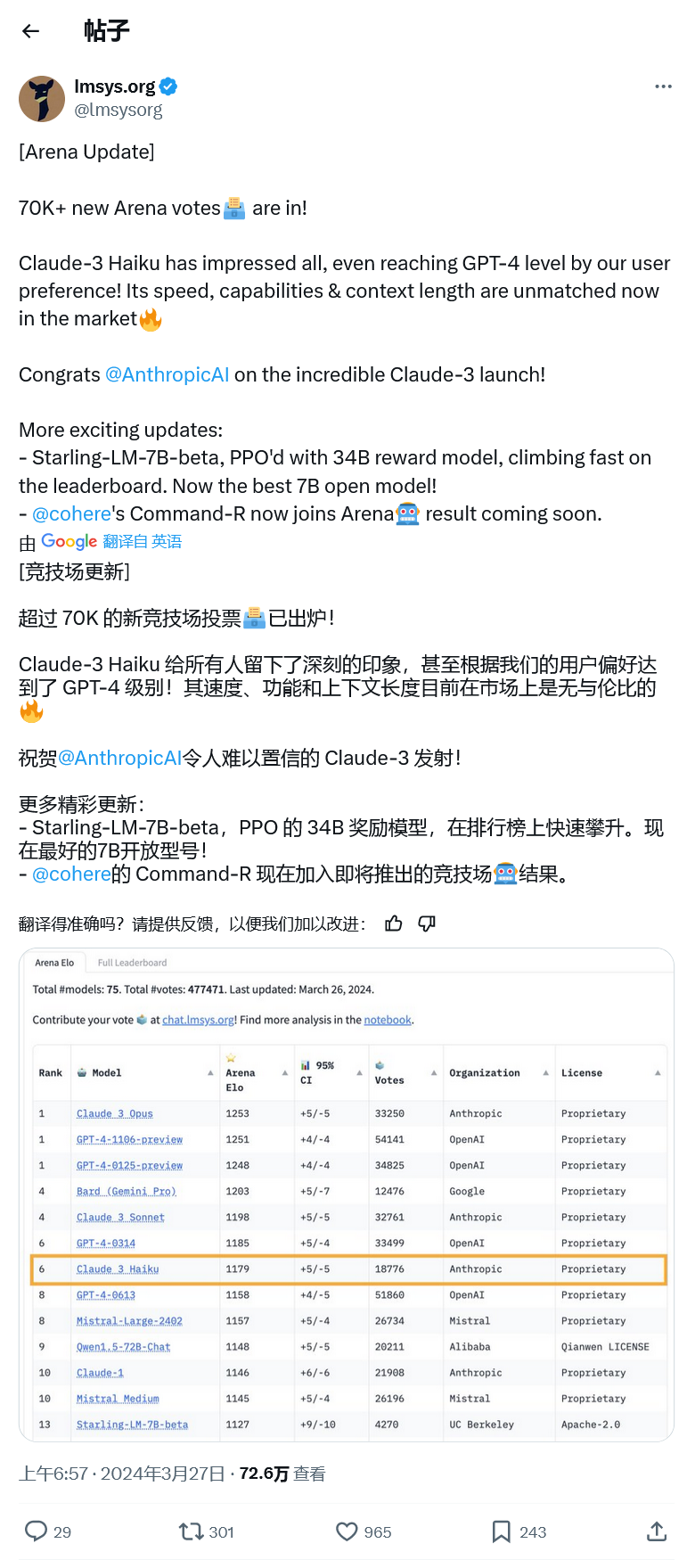
しかし昨日、Anthropic の Claude 3 Opus が 1253 対 1251 の僅差で GPT-4 を破り、OpenAI の LLM がトップの座から追いやられました。スコアが近すぎたため、代理店はエラー率を考慮してクロード 3 と GPT-4 を同率 1 位にランク付けし、GPT-4 の別のプレビュー バージョンも同率 1 位にランクしました。
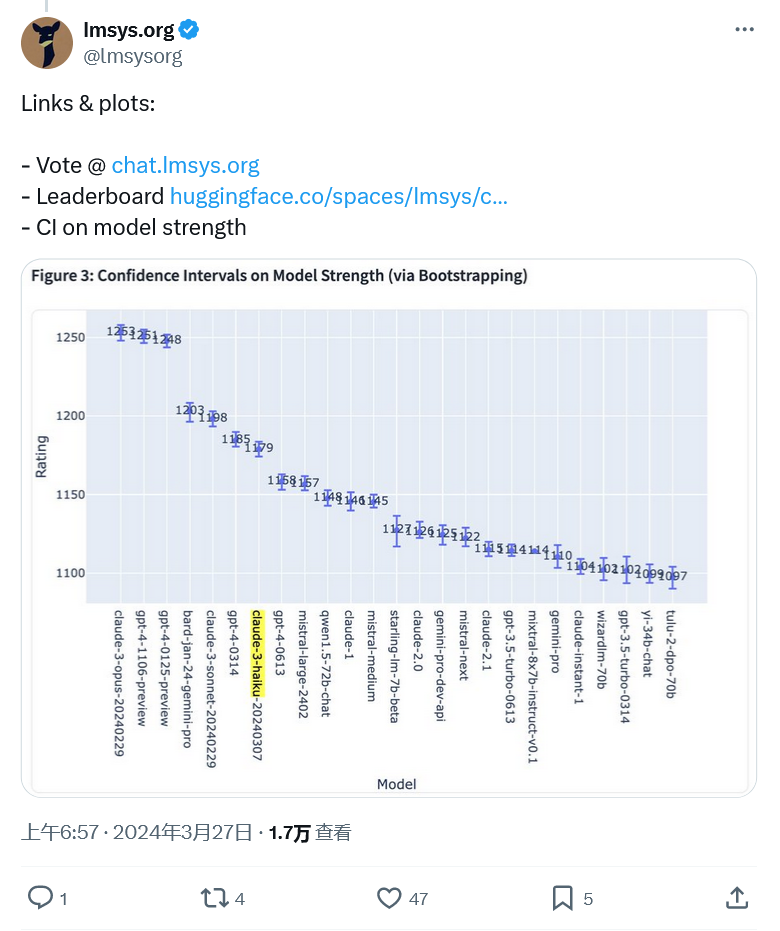
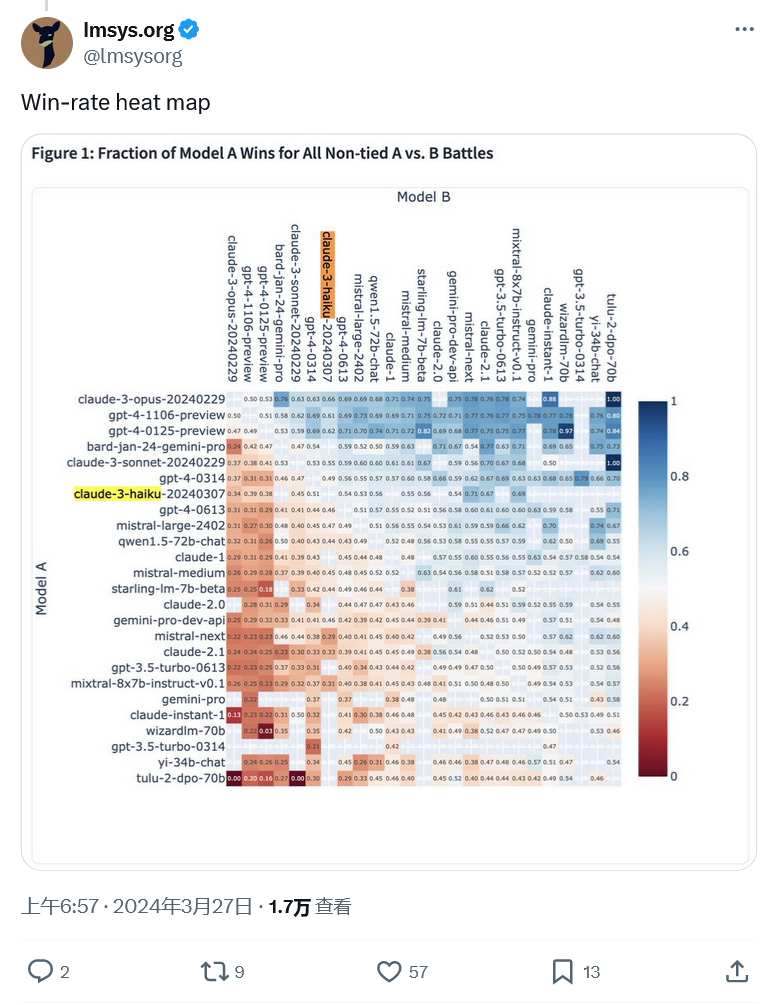
以上がGPT-4 と同率 1 位の LMSYS ベンチマークは、Claude-3 モデルが良好なパフォーマンスを示していることを示していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



