


大規模言語モデル (llm) のトレーニングは、パラメーターが "わずか" 70 億個であっても、計算量が多いタスクです。このレベルのトレーニングには、ほとんどの個人の愛好家の能力を超えるリソースが必要です。このギャップを埋めるために、低ランク適応 (LoRA) などのパラメーター効率の高い手法が登場し、消費者向けグレードの GPU で多数のモデルを微調整できるようになりました。
GaLore は、単にパラメータの数を減らすのではなく、最適化されたパラメータ トレーニングを使用して VRAM 要件を削減する革新的な方法です。これは、GaLore が、モデルが学習のためにすべてのパラメーターを完全に活用し、LoRA よりも効率的にメモリを節約できる新しいモデル トレーニング戦略であることを意味します。
GaLore は、重要なトレーニング情報を保持しながら、これらの勾配を低次元空間にマッピングすることで、計算負荷を効果的に軽減します。バックプロパゲーション中にすべてのレイヤーを一度に更新する従来のオプティマイザーとは異なり、GaLore はバックプロパゲーションにレイヤーごとの更新方法を使用します。この戦略により、トレーニング中のメモリ使用量が大幅に削減され、パフォーマンスがさらに最適化されます。
LoRA と同様に、GaLore を使用すると、最大 24 GB の VRAM を搭載したコンシューマー グレードの GPU で 7B モデルを微調整できます。結果は、モデルのパフォーマンスがフルパラメーター微調整に匹敵し、LoRA よりも優れているように見えることを示しています。
Hugging Face の公式コードが現在存在しないよりは良いので、論文のコードをトレーニングに手動で使用して、LoRA と比較してみましょう。
まず、GaLore をインストールする必要があります
pip install galore-torch
次に、これらのライブラリも確認する必要がありますおよび version
datasets==2.18.0 transformers==4.39.1 trl==0.8.1 accelerate==0.28.0 torch==2.2.1
Galore 階層オプティマイザは次の方法でアクティブ化されることに注意してください。モデルウェイトフック。 Hugging Face Trainer を使用するため、オプティマイザーとスケジューラーの抽象クラスも自分で実装する必要があります。これらのクラスの構造は、いかなる操作も実行しません。
from typing import Optional import torch # Approach taken from Hugging Face transformers https://github.com/huggingface/transformers/blob/main/src/transformers/optimization.py class LayerWiseDummyOptimizer(torch.optim.Optimizer):def __init__(self, optimizer_dict=None, *args, **kwargs):dummy_tensor = torch.randn(1, 1)self.optimizer_dict = optimizer_dictsuper().__init__([dummy_tensor], {"lr": 1e-03}) def zero_grad(self, set_to_none: bool = True) -> None: pass def step(self, closure=None) -> Optional[float]: pass class LayerWiseDummyScheduler(torch.optim.lr_scheduler.LRScheduler):def __init__(self, *args, **kwargs):optimizer = LayerWiseDummyOptimizer()last_epoch = -1verbose = Falsesuper().__init__(optimizer, last_epoch, verbose) def get_lr(self): return [group["lr"] for group in self.optimizer.param_groups] def _get_closed_form_lr(self): return self.base_lrsGaLore オプティマイザーは、主に attn という名前の線形パラメーターの特定のパラメーターをターゲットとします。またはレイヤー内のmlp。これらのターゲット パラメーターに関数を体系的にフックすることで、GaLore 8 ビット オプティマイザーが機能するようになります。
from transformers import get_constant_schedule from functools import partial import torch.nn import bitsandbytes as bnb from galore_torch import GaLoreAdamW8bit def load_galore_optimizer(model, lr, galore_config):# function to hook optimizer and scheduler to a given parameter def optimizer_hook(p, optimizer, scheduler):if p.grad is not None: optimizer.step()optimizer.zero_grad()scheduler.step() # Parameters to optimize with Galoregalore_params = [(module.weight, module_name) for module_name, module in model.named_modules() if isinstance(module, nn.Linear) and any(target_key in module_name for target_key in galore_config["target_modules_list"])] id_galore_params = {id(p) for p, _ in galore_params} # Hook Galore optim to all target params, Adam8bit to all othersfor p in model.parameters():if p.requires_grad:if id(p) in id_galore_params:optimizer = GaLoreAdamW8bit([dict(params=[p], **galore_config)], lr=lr)else:optimizer = bnb.optim.Adam8bit([p], lr = lr)scheduler = get_constant_schedule(optimizer) p.register_post_accumulate_grad_hook(partial(optimizer_hook, optimizer=optimizer, scheduler=scheduler)) # return dummies, stepping is done with hooks return LayerWiseDummyOptimizer(), LayerWiseDummyScheduler()オプティマイザーを準備した後、トレーニングに Trainer を使用し始めます。以下は、TRL の SFTTrainer (Trainer のサブクラス) を使用し、RTX 3090/4090 などの 24 GB VRAM GPU で実行される Open Assistant データセットで llama2-7b を微調整する簡単な例です。
GaLore オプティマイザーには、次のように設定する必要があるいくつかのハイパーパラメーターがあります:
target_modules_list: GaLore ターゲットのレイヤーを指定します
ランク: 射影行列のランク。 LoRA と同様に、ランクが高くなるほど、微調整はフルパラメータ微調整に近づきます。 GaLore の作成者は、7B を使用することを推奨しています。 1024
update_proj_gap: 投影を更新するステップの数。これは高価な手順であり、7B の場合は約 15 分かかります。投影を更新する間隔を定義します。推奨範囲は 50 ~ 1000 ステップです。
scale: LoRA のアルファに似たスケーリング係数。更新の強度を調整するために使用されます。いくつかの値を試した結果、scale=2 が従来のフルパラメータ微調整に最も近いことがわかりました。
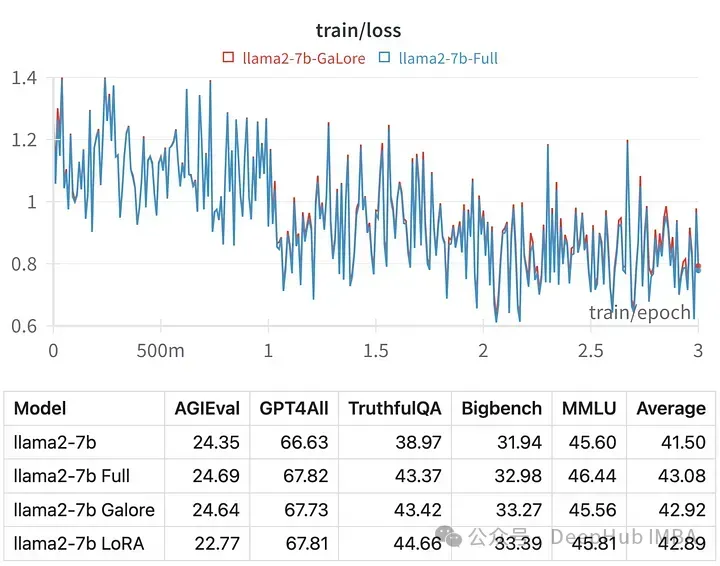
特定のハイパーパラメータのトレーニング損失は、フルパラメータ調整の軌跡と非常に似ており、次のことがわかります。 GaLore 階層化メソッドは実際に同等であることがわかります。
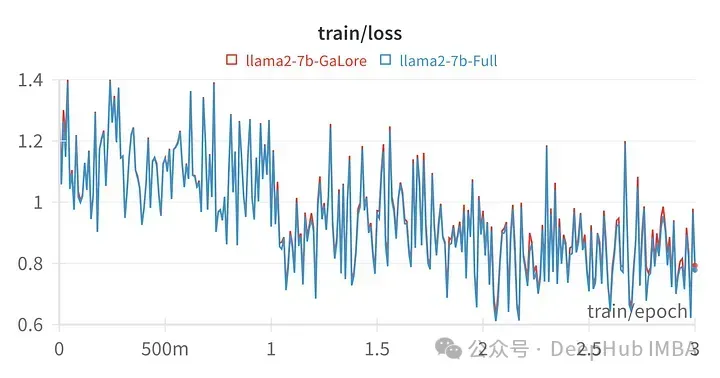
GaLore でトレーニングされたモデルのスコアは、完全なパラメーター微調整と非常によく似ています。
GaLore では約 15 GB の VRAM を節約できますが、定期的に投影が更新されるため、トレーニングに時間がかかります。
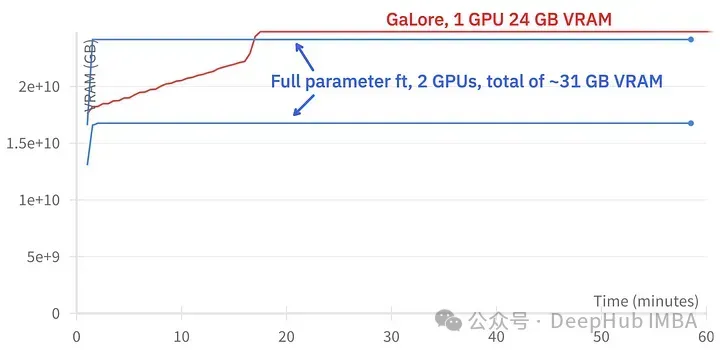
#上の図は、2 つの 3090
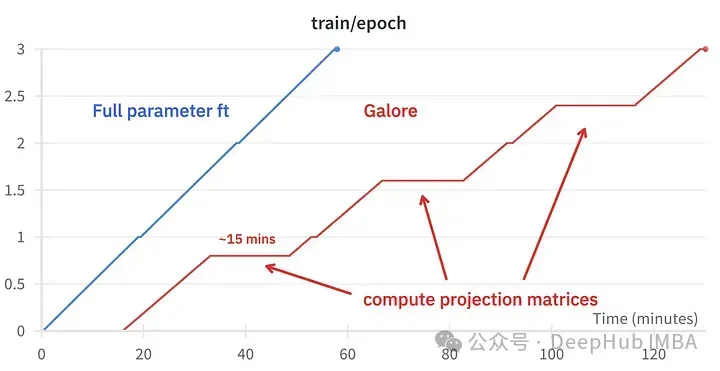
トレーニング イベントの比較、微調整: ~58 分。 GaLore: 約 130 分
最後に GaLore と LoRA の比較を見てみましょう
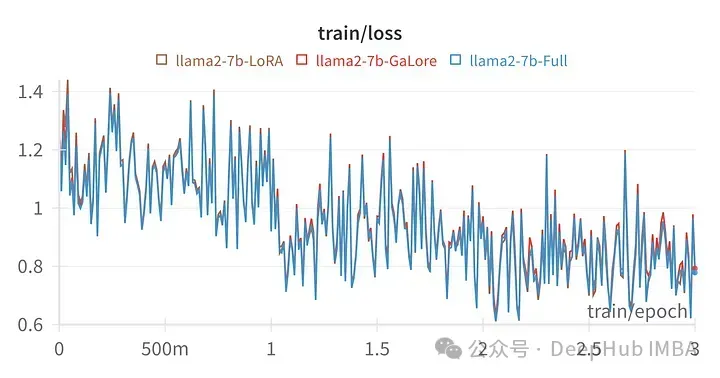
上の図 LoRA 用にすべての線形レイヤーを微調整、ランク 64 の損失マップ、アルファ 16
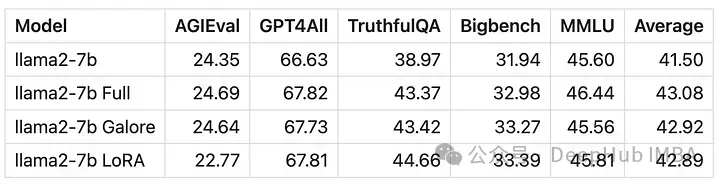
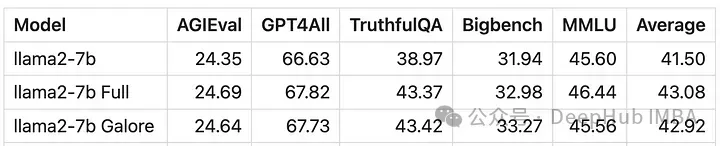
GaLore がほぼ完全であることが数値的にわかります。 -パラメータトレーニング 新しいメソッドのパフォーマンスは微調整に匹敵し、LoRA よりもはるかに優れています。
GaLore は VRAM を節約できるため、コンシューマー グレードの GPU で 7B モデルのトレーニングが可能ですが、微調整や LoRA よりも遅くなります。ほぼ2倍の時間がかかります。
以上がGaLore を使用したローカル GPU での効率的な LLM チューニングの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



