


CNN、Transformer、Uniformer に加えて、より効率的なビデオ理解テクノロジーがついに登場しました

ビデオ理解の中心的な目標は、時空間表現を正確に理解することですが、2 つの主な課題に直面しています。それは、短いビデオ クリップには大量の時空間的冗長性があり、もう 1 つは複雑な時空間依存関係です。 3 次元畳み込みニューラル ネットワーク (CNN) とビデオ トランスフォーマーは、これらの課題の 1 つを解決するのにうまく機能していますが、両方の課題に同時に対処するにはいくつかの欠点があります。 UniFormer は両方のアプローチの利点を組み合わせようとしますが、長いビデオをモデリングする際に困難に直面します。
自然言語処理の分野における S4、RWKV、RetNet などの低コスト ソリューションの出現により、ビジュアル モデルに新たな道が開かれました。 Mamba は、長期的な動的モデリングを容易にしながら、線形の複雑さを維持するバランスを実現する選択的状態空間モデル (SSM) で際立っています。このイノベーションは、多方向 SSM を利用して 2D 画像処理を強化する Vision Mamba と VMamba で実証されているように、ビジョン タスクでのアプリケーションを推進します。これらのモデルは、メモリ使用量を大幅に削減しながら、パフォーマンスにおいてはアテンションベースのアーキテクチャと同等です。
ビデオによって生成されるシーケンスが本質的に長いことを考えると、当然の疑問は、「Mamba はビデオの理解にうまく機能するのか?」ということです。
この記事は、Mamba からインスピレーションを得て、特にビデオの理解に特化した SSM (選択的状態空間モデル) である VideoMamba を紹介します。 VideoMamba は Vanilla ViT の設計哲学を利用しており、畳み込みとアテンションのメカニズムを組み合わせています。これは、動的な時空間背景モデリングのための線形複雑度手法を提供し、特に高解像度の長いビデオの処理に適しています。評価は主に、VideoMamba の 4 つの主要な機能に焦点を当てています:
視覚分野のスケーラビリティ: この記事では、VideoMamba のスケーラビリティを評価します。がテストされた結果、純粋な Mamba モデルは拡張し続けるとオーバーフィットする傾向があることがわかりました。この論文では、モデルと入力サイズが増加しても VideoMamba を使用できるように、シンプルで効果的な自己蒸留戦略を紹介しています。大規模なデータセット事前トレーニングなしで大幅なパフォーマンスの向上を実現します。
短期アクション認識に対する感度: この論文の分析は、短期アクションを正確に区別する VideoMamba の能力を評価するために拡張されています。 、特に開閉など、動作に微妙な違いがあるアクションを含むもの。研究結果によると、VideoMamba は既存の注意ベースのモデルよりも優れたパフォーマンスを示します。さらに重要なことは、マスク モデリングにも適しており、時間的感度がさらに向上していることです。
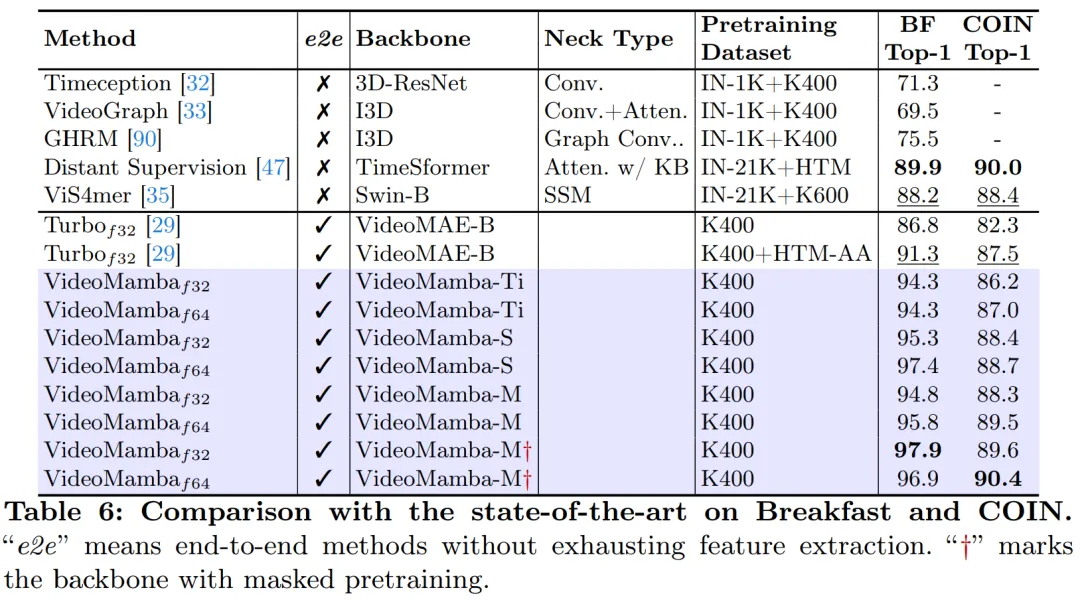
長いビデオの理解における優れた点: この記事では、VideoMamba の長いビデオを解釈する能力を評価します。エンドツーエンドのトレーニングでは、従来の機能ベースの方法に比べて大きな利点が実証されます。特に、VideoMamba は 64 フレーム ビデオ上で TimeSformer よりも 6 倍高速に動作し、必要な GPU メモリの量は 40 分の 1 です (図 1 を参照)。

他のモダリティとの互換性: 最後に、この記事では、VideoMamba の他のモダリティとの適応性を評価します。ビデオ テキスト検索の結果では、特に複雑なシナリオを含む長いビデオで、ViT と比較してパフォーマンスが向上していることがわかります。これは、その堅牢性とマルチモーダルな統合機能を強調しています。
この研究の詳細な実験により、短期 (K400 および SthSthV2) および長期 (Breakfast、COIN、LVU) のビデオ コンテンツ理解における VideoMamba の大きな可能性が明らかになりました。 VideoMamba は高い効率と精度を実証しており、長時間のビデオ理解の分野で重要なコンポーネントになることを示しています。将来の研究を促進するために、すべてのコードとモデルはオープンソースになりました。

- #論文アドレス: https://arxiv.org/pdf/2403.06977.pdf #プロジェクト アドレス: https://github.com/OpenGVLab/VideoMamba
- 論文タイトル: VideoMamba: 効率的なビデオ理解のための状態空間モデル
- #メソッドの紹介
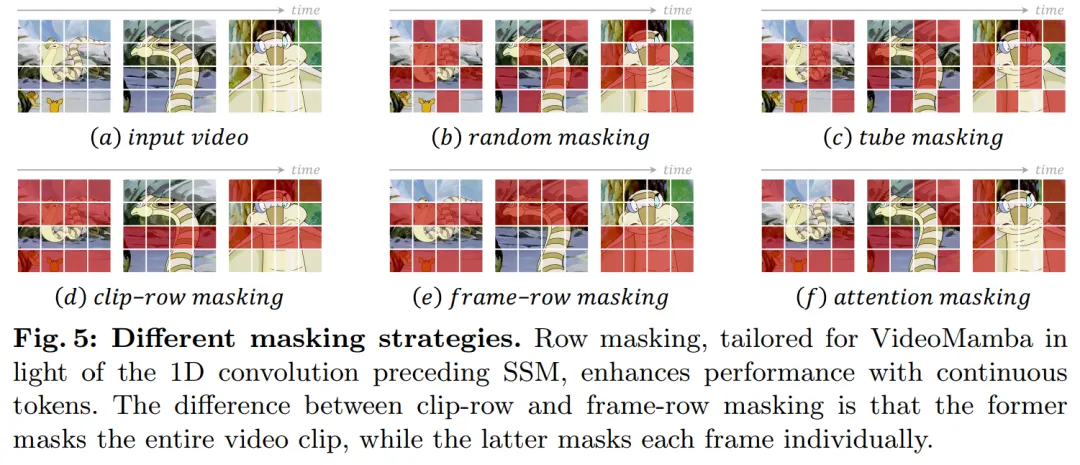
## 以下の図 2a は、Mamba モジュールの詳細を示しています。



(a) まず空間的に、空間トークンを位置ごとに整理し、次にそれらをフレームごとに積み重ねます。
(b) 時間優先、フレームに従って時間トークンを配置し、空間次元に沿って積み重ねます;
(c) 空間- 時間混合、空間優先と時間優先の両方あり、v1 は半分を実行し、v2 はすべて (計算量の 2 倍) を実行します。
図 7a の実験は、スペースファーストの双方向スキャンが最も効率的でありながら最も単純であることを示しています。 Mamba の直線的な複雑さにより、この記事の VideoMamba は高解像度の長いビデオを効率的に処理できます。
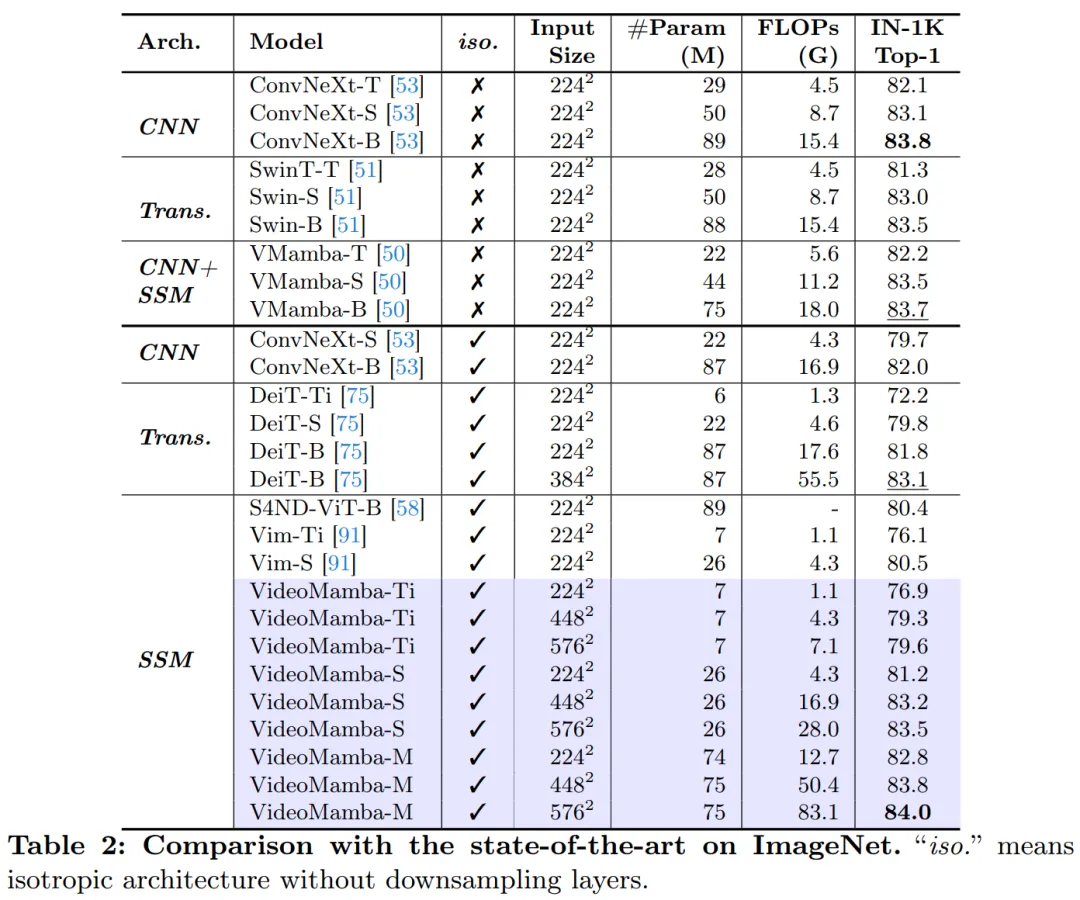
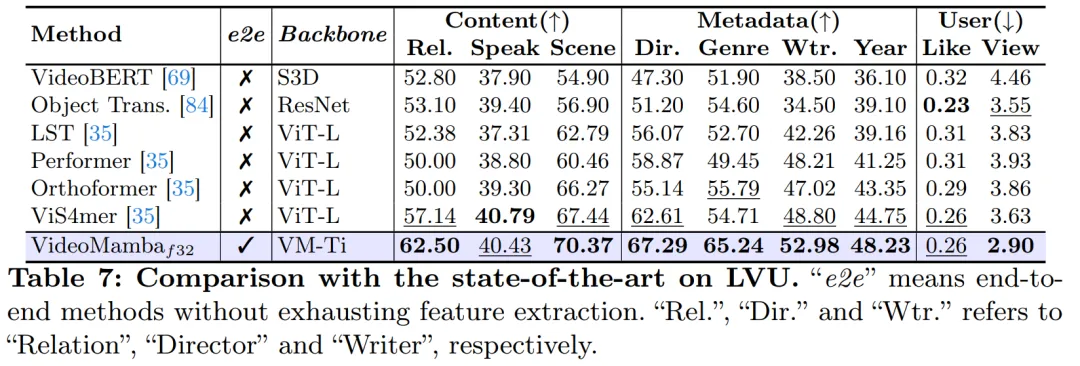
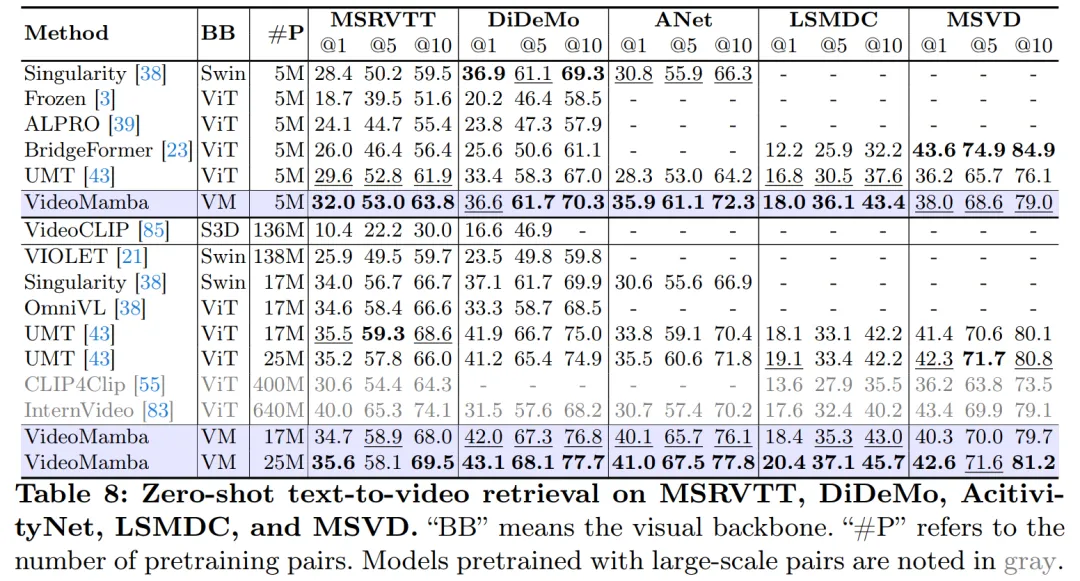
B-Mamba レイヤーの SSM の場合、この記事では Mamba と同じデフォルトのハイパーパラメーター設定を使用し、状態次元と拡張率をそれぞれ 16 と 2 に設定します。 ViT のアプローチに従い、この論文では深さと埋め込み次元を調整して、VideoMamba-Ti、VideoMamba-S、VideoMamba-M など、表 1 のモデルと同等のサイズのモデルを作成します。ただし、実験では、大きな VideoMamba は実験でオーバーフィットする傾向があり、図 6a に示すように次善のパフォーマンスが得られることが観察されました。この過学習の問題は、この論文で提案したモデルだけでなく、VMamba にも存在し、VMamba-B の最高のパフォーマンスは総トレーニング期間の 4 分の 3 で達成されます。大規模な Mamba モデルの過学習問題に対処するために、この論文では、より小規模で十分にトレーニングされたモデルを「教師」として使用し、より大規模な「生徒」モデルのトレーニングをガイドする効果的な自己蒸留戦略を紹介します。図 6a に示す結果は、この戦略が期待どおりのより良い収束につながることを示しています。 # マスキング戦略に関して、この記事では、図 5 に示すように、具体的にはさまざまな行マスキング手法を提案します。 B-Mamba ブロックの連続トークンの優先順位。 表 2 は、ImageNet-1K データセットでの結果を示しています。特に、VideoMamba-M は他の等方性アーキテクチャよりも大幅に優れており、使用するパラメータが少ないにもかかわらず、ConvNeXt-B と比較して 0.8%、DeiT-B と比較して 2.0% 向上しています。 VideoMamba-M は、パフォーマンスを向上させるために階層化された機能を採用した非等方性バックボーン構造でも優れたパフォーマンスを発揮します。長いシーケンスの処理における Mamba の効率を考慮して、この論文では解像度を高めることでパフォーマンスをさらに向上させ、わずか 74M のパラメータを使用して 84.0% のトップ 1 精度を達成しました。 図 1 に示すように、VideoMamba は直線的に複雑であるため、長いビデオを使用したエンドツーエンドのトレーニングに非常に適しています。表 6 と 7 の比較は、これらのタスクにおける従来の機能ベースの方法と比較した VideoMamba のシンプルさと有効性を強調しています。これによりパフォーマンスが大幅に向上し、より小さいモデル サイズでも SOTA の結果が得られます。 VideoMamba-Ti は、Swin-B 機能を使用することで ViS4mer と比較して 6.1% の大幅な改善を示し、さらに Turbo のマルチモーダル アライメント方法と比較して 3.0% の改善を示しています。特に、この結果は、長期タスクに対するモデルとフレーム レートのスケーリングのプラスの影響を強調しています。 LVU によって提案された 9 つの多様で困難なタスクに関して、この論文では、VideoMamba-Ti を微調整するためのエンドツーエンドのアプローチを採用し、現在の SOTA 手法と同等またはそれを上回る結果を達成しています。これらの結果は、VideoMamba の有効性を強調するだけでなく、将来の長時間ビデオの理解に対するその大きな可能性も示しています。 #表 8 に示すように、同じ事前トレーニング コーパスと同様のトレーニング戦略の下で、VideoMamba Itゼロサンプルビデオ取得パフォーマンスでは、ViT ベースの UMT よりも優れています。これは、マルチモーダル ビデオ タスクの処理において、ViT と比較して Mamba が同等の効率とスケーラビリティを備えていることを強調しています。特に、VideoMamba は、より長いビデオ長のデータセット (ANet や DiDeMo など) やより複雑なシナリオ (LSMDC など) で大幅な改善を示しています。これは、クロスモーダル調整が必要な場合でも、困難なマルチモーダル環境における Mamba の機能を示しています。 研究の詳細については、元の論文を参照してください。 

#実験


以上がCNN、Transformer、Uniformer に加えて、より効率的なビデオ理解テクノロジーがついに登場しましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7364
7364
 15
1628
14
1353
52
1265
25
1214
29
15
1628
14
1353
52
1265
25
1214
29

 C言語でchar配列の使用方法
Apr 03, 2025 pm 03:24 PM
C言語でchar配列の使用方法
Apr 03, 2025 pm 03:24 PM
Char Arrayは文字シーケンスをC言語で保存し、char array_name [size]として宣言されます。アクセス要素はサブスクリプト演算子に渡され、要素は文字列のエンドポイントを表すnullターミネーター「\ 0」で終了します。 C言語は、strlen()、strcpy()、strcat()、strcmp()など、さまざまな文字列操作関数を提供します。
 Cスイッチステートメントでデフォルトに起因するエラーを避けてください
Apr 03, 2025 pm 03:45 PM
Cスイッチステートメントでデフォルトに起因するエラーを避けてください
Apr 03, 2025 pm 03:45 PM
Cスイッチステートメントでデフォルトに起因するエラーを回避するための戦略:定数の代わりに列挙を使用し、ケースステートメントの値を列挙の有効なメンバーに制限します。最後のケースステートメントでフォールスルーを使用して、プログラムが以下のコードを引き続き実行できるようにします。フォールスルーなしのスイッチステートメントの場合、エラー処理のためのデフォルトステートメントを常に追加するか、デフォルトの動作を提供します。
 スイッチケースステートメントのデフォルトの重要性(C言語)
Apr 03, 2025 pm 03:57 PM
スイッチケースステートメントのデフォルトの重要性(C言語)
Apr 03, 2025 pm 03:57 PM
デフォルトステートメントは、変数値がケースステートメントと一致しない場合にコードブロックが実行されることを保証するデフォルトの処理パスを提供するため、スイッチケースステートメントで重要です。これにより、予期しない動作やエラーが防止され、コードの堅牢性が向上します。
 C言語関数の返品値の種類は何ですか? C言語関数の返品値のタイプの概要?
Apr 03, 2025 pm 11:18 PM
C言語関数の返品値の種類は何ですか? C言語関数の返品値のタイプの概要?
Apr 03, 2025 pm 11:18 PM
c言語関数の返品値タイプには、int、float、double、char、void、およびポインタータイプが含まれます。 intは整数を返すために使用され、フロートとダブルはフロートを返すために使用され、charは文字を返します。 voidとは、関数が値を返さないことを意味します。ポインタータイプはメモリアドレスを返し、メモリの漏れを避けるように注意してください。構造またはコンソーシアムは、複数の関連データを返すことができます。
 Cで理解する方法!x?
Apr 03, 2025 pm 02:33 PM
Cで理解する方法!x?
Apr 03, 2025 pm 02:33 PM
!X理解!Xは、C言語の論理的な非操作者です。 Xの値をブーリングします。つまり、虚偽の真の変化、trueへの誤った変更です。ただし、Cの真実と虚偽はブール型ではなく数値で表されていることに注意してください。非ゼロは真であると見なされ、0のみが偽と見なされます。したがって、!xは正の数と同じ負の数を扱い、真実と見なされます。
 C言語のcharの値の範囲は何ですか
Apr 03, 2025 pm 03:39 PM
C言語のcharの値の範囲は何ですか
Apr 03, 2025 pm 03:39 PM
C言語のCHARの値範囲は、実装方法に依存します:署名型CHAR:-128〜127 Unsigned Char:0〜255特定の範囲は、コンピューターアーキテクチャとコンパイラオプションの影響を受けます。デフォルトでは、charは署名型タイプに設定されています。
 C言語関数の概念
Apr 03, 2025 pm 10:09 PM
C言語関数の概念
Apr 03, 2025 pm 10:09 PM
C言語関数は再利用可能なコードブロックです。彼らは入力を受け取り、操作を実行し、結果を返すことができます。これにより、再利用性が改善され、複雑さが軽減されます。関数の内部メカニズムには、パラメーターの渡し、関数の実行、および戻り値が含まれます。プロセス全体には、関数インラインなどの最適化が含まれます。単一の責任、少数のパラメーター、命名仕様、エラー処理の原則に従って、優れた関数が書かれています。関数と組み合わせたポインターは、外部変数値の変更など、より強力な関数を実現できます。関数ポインターは機能をパラメーターまたはストアアドレスとして渡し、機能への動的呼び出しを実装するために使用されます。機能機能とテクニックを理解することは、効率的で保守可能で、理解しやすいCプログラムを書くための鍵です。
 C言語の!xの一般的なアプリケーションシナリオは何ですか?
Apr 03, 2025 pm 02:42 PM
C言語の!xの一般的なアプリケーションシナリオは何ですか?
Apr 03, 2025 pm 02:42 PM
C言語の!xの目的は逆に限定されません:論理的判断:0であるかどうかはx == 0よりも簡潔か。プログラムの流れを制御するか、ステータスを表す:0および非0を使用してtrueまたはfalseを表す。ビット操作:すべてのビットをすばやく反転させます(注意して使用)。
