


OpenAIの大型モデルの恩恵を受けたロボットが深夜にやってくる!
これは図 01 と呼ばれるものです。聞いたり、話したり、柔軟に動くことができます。

人間が見ているものすべてを説明できます:
テーブルの上に赤いリンゴがあり、水切りラックの上にさらにいくつかありました。お皿とカップ、あなたはその隣に立ち、両手をテーブルの上に軽く置きます。
 写真
写真
人間が「食べたい」と言うと、すぐにリンゴを渡します。
 写真
写真
そして、彼は自分が何をしているのかを明確に理解しており、テーブルの上にある唯一の食べられるものであるため、リンゴを与えます。
ちなみに私も整理整頓をしており、2つのタスクを同時に処理することができます。
 写真
写真
最も重要なことは、これらのデモはいずれも加速されていないということであり、ロボットの本来の動きは非常に速いです。
(誰も舞台裏にはいません)

今、ネチズンは黙っていられず、すぐに@ボストンダイナミクス:
老人皆さん、この男は本当に興奮しています。研究室に戻って、古いロボット (ボストン ダイナミクス) をもう少し踊らせなければなりません。
 写真
写真
OpenAIが大規模な言語モデルを展開し、Vincentのビデオを公開したのを見てため息をつき、ロボットを狙撃したネチズンもいた:
これは厳しい競争です; OpenAl と協力すれば、Apple は Tesla を超える可能性があります。
しかし、ハードウェアの観点から見ると、オプティマス プライムの方が美しく、フィギュア 01 にはまだ「美容整形」が必要です。 (doge)
 写真
写真
次に、図 01 の詳細を見ていきましょう。
創設者の紹介によると、Figure 01 はエンドツーエンドのニューラル ネットワークを通じて人間と自由に会話できます。
OpenAI が提供する視覚的理解と言語理解機能に基づいて、高速、シンプル、そして器用なアクションを実行できます。
このモデルは大型ビジュアル言語モデルとだけ言われており、GPT-4Vなのかは不明です。
 写真
写真
また、行動を計画し、短期記憶能力を持ち、推論プロセスを言語で説明することもできます。
 写真
写真
たとえば、「そこに置いてもらえますか?」というダイアログでは、
「それら」、「そこ」この曖昧な表現の理解は、ロボットの短期記憶能力を反映しています。
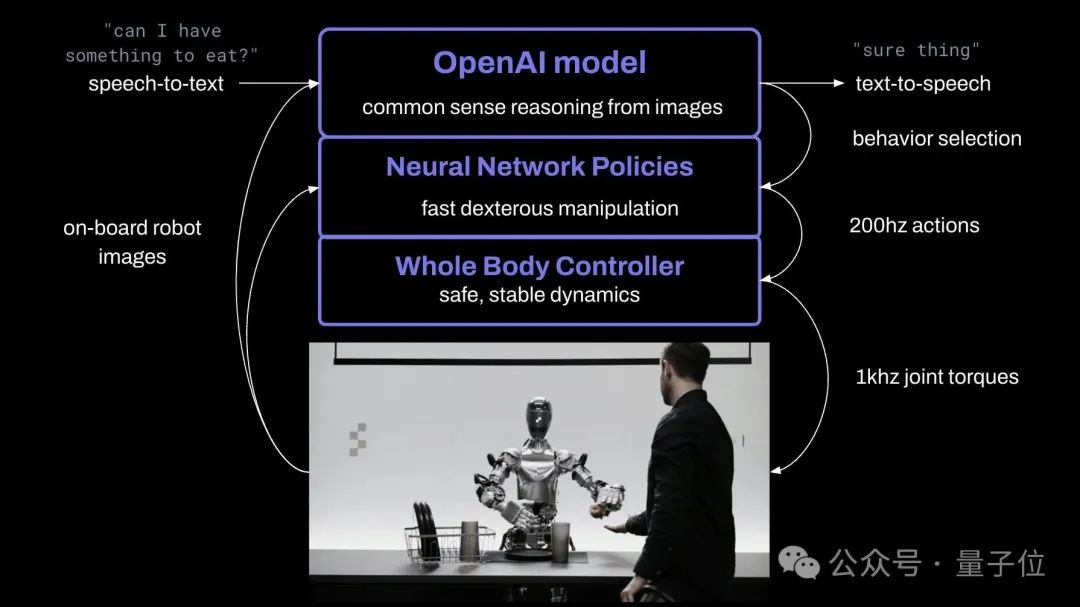
OpenAIによって学習された視覚言語モデルを使用しており、ロボットカメラが10Hzで画像をキャプチャし、ニューラルネットワークが24自由度の動き(手指関節角度)を200Hzで出力します。
具体的な分業という点では、ロボットの戦略も人間の戦略と非常に似ています。
複雑なアクションは大規模な AI モデルに引き渡されます。事前トレーニングされたモデルは、画像とテキストに対して常識的な推論を実行し、アクション プランを提供します。
ビニール袋をつかむなどの単純なアクション(どこでも掴むことができます)、ロボットは、学習したビジョンアクション実行戦略に基づいて、いくつかの「潜在意識」の素早い反応アクションを実行できます。
同時に、全身コントローラーは体のバランスと安定した動きを維持する責任を負います。
 写真
写真
ロボットの音声機能は、大規模なテキスト音声モデルに基づいて微調整されています。
 写真
写真
最先端の AI モデルに加えて、Figure 01 の背後にある会社 Figure の創設者兼 CEO もツイートで次のように述べています。図 ロボットのすべての主要コンポーネントを統合します。
モーター、ミドルウェア オペレーティング システム、センサー、機械構造などが含まれており、すべてフィギュア エンジニアによって設計されています。
このロボット工学の新興企業は 2 週間前に OpenAI との協力を正式に発表したばかりであると理解されていますが、このような大きな成果をもたらしたのは 13 日後のことでした。多くの人が今後の協力を期待し始めています。
 写真
写真
このようにして、身体化されたインテリジェンスの分野でまた新たなスターが脚光を浴びています。
フィギュアといえば、2022年に設立された会社。前述の通り、つい十数日前に再び社外から注目を集めた――。 —
新たな資金調達ラウンドで6億7,500万米ドルを調達し、その評価額は26億米ドルに達したと正式発表 投資家はマイクロソフト、OpenAI、Nvidia、Amazon創設者のベゾスを含むシリコンバレーのほぼ半分を集めている等
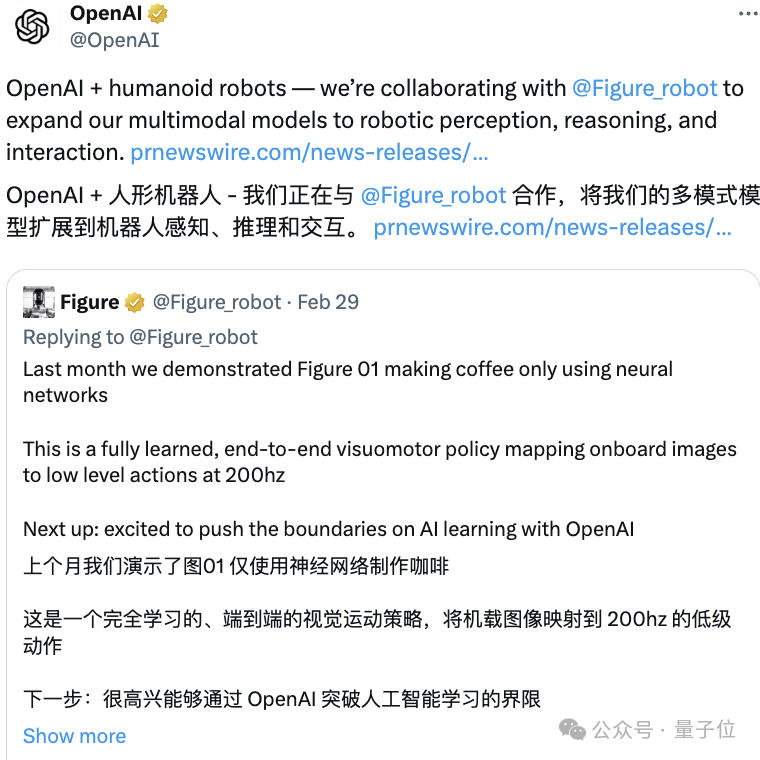
さらに重要なのは、OpenAI が Figure とのさらなる協力計画も明らかにしたことです。マルチモーダルな大規模モデルの機能をロボットの認識、推論、対話に拡張し、「肉体労働において人間に代わる能力を開発する」というものです。人型ロボット」。
現在最も注目されているテクノロジーの語彙を使用するには、身体化されたインテリジェンスを開発するために協力する必要があります。
 写真
写真
当時、図 01 の最新の進歩は江おばさんのものでした。
人間のデモンストレーション ビデオを見て、直後に10 時間のエンドツーエンドのトレーニングにより、Figure 01 はカプセル コーヒー マシンを使用してコーヒーを淹れる方法を学ぶことができます。
 写真
写真
FigureとOpenAIの協力が公になるとすぐに、ネチズンはすでに将来の躍進への期待でいっぱいでした。
 写真
写真
結局のところ、ブレット・アドコックは、「唯一の焦点は、人類の将来にプラスの影響を与える30年の展望を持ったフィギュアを確立することです」と述べました。 」 私の個人ホームページにすべて書いてあります。
しかし、わずか約 2 週間で新たな進歩がもたらされるとは、おそらく誰も想像できなかったでしょう。
ここまでは、とても早いです。そして、それは今後も一般化され、規模が拡大していく可能性があります。
 写真
写真
フィギュアの採用情報が爆撃サイトのデモと同時に公開されたことは言及する価値があります:
私たちは人型ロボットに命を吹き込んでいます。参加しませんか。
 写真
写真
参考リンク:
[1]//m.sbmmt.com/link/59bbfbe0d3922ccd1d167661a26d8353
[2]//m.sbmmt.com/link/a3fc34dce15cda93287496c84af5203c
[3]//m.sbmmt.com/link/194585b5215aea447389c5fefca09c61
以上がOpenAI大型モデル上半身ロボットが全速力で爆発を発揮!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



