



#自動運転のためのエンドツーエンドの微分可能学習は、最近、顕著なパラダイムとなっています。大きなボトルネックは、3D ボックスやセマンティック セグメンテーションなどの高品質のラベル付きデータへの需要が膨大であることです。これらのデータは、手動で注釈を付けるのに費用がかかることで知られています。この問題は、AD におけるサンプル内挙動が長い尾部分布を持つことが多いという顕著な事実によってさらに悪化します。言い換えれば、収集されるデータのほとんどは取るに足らないもの (直線道路での前進走行など) であり、安全上重要な状況はほんのわずかです。この論文では、エンドツーエンドの AD でサンプルとラベルの効率をどのように達成するかという、実用上重要だが十分に研究されていない問題を検討します。
具体的には、この論文は、提案された計画ルートの多様性と有用性の基準に基づいて、収集された生データの一部に徐々に注釈を付ける計画指向のアクティブ ラーニング手法を設計します。経験的には、提案された計画指向のアプローチは、一般的なアクティブ ラーニング アプローチよりも大幅に優れたパフォーマンスを発揮できます。特に、私たちの手法は、nuScenes データのわずか 30% を使用して、最先端のエンドツーエンド AD 手法と同等のパフォーマンスを達成します。私たちの研究が、方法論的な取り組みに加えて、データ中心の観点からの将来の研究にインスピレーションを与えることを願っています。
論文リンク: https://arxiv.org/pdf/2403.02877.pdf
この記事の主な貢献:
ActiveAD はエンドツーエンド AD フレームワークで詳細に説明され、データの特性に基づいて多様性と不確実性の指標が設計されます。 ADの。
コンピュータ ビジョンのアクティブ ラーニングの場合、最初のサンプル選択は通常、追加情報や学習特性を含まない元の画像のみに基づいて行われます。そのため、ランダムな初期化が一般的に行われるようになりました。 AD の場合、追加の事前情報が利用可能です。具体的には、センサーからデータを収集する際に、自車の速度や軌跡といった従来の情報も同時に記録できる。さらに、天候や照明の状態は継続的なことが多く、フラグメント レベルで注釈を付けるのが簡単です。この情報により、初期セット選択の情報に基づいた選択が容易になります。したがって、初期選択のための自己多様性尺度を設計しました。
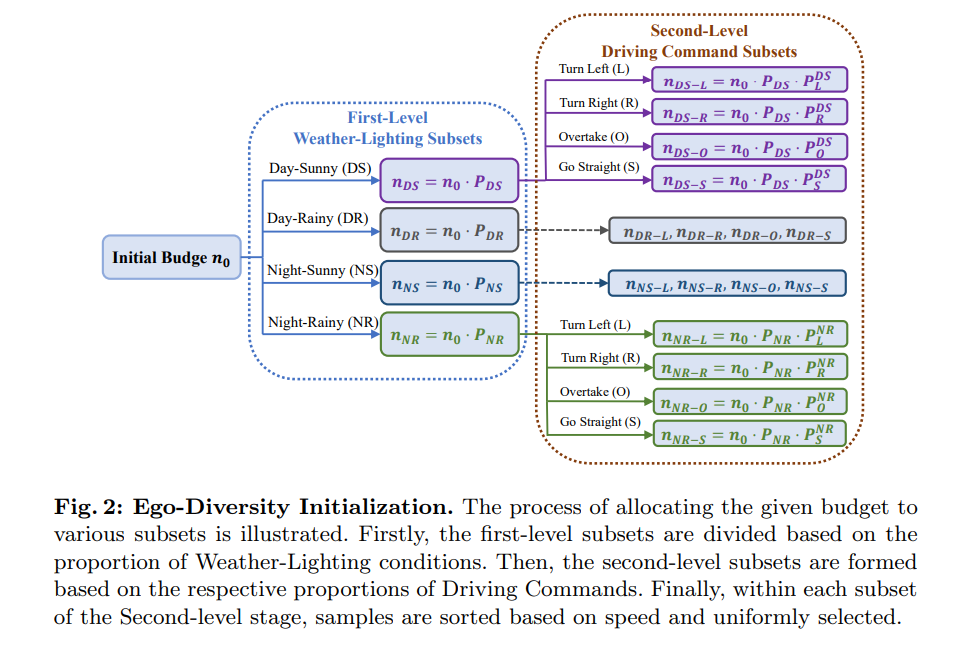
Ego Diversity: 1) 気象照明、2) 運転指示、3) 平均速度の 3 つの部分で構成されます。まず、nuScenes の記述を使用して、完全なデータ セットを 4 つの相互に排他的なサブセット、Day Sunny (DS)、Day Rainy (DR)、Night Sunny (NS)、NightRainy (NR) に分割します。次に、各サブセットは、完全なセグメント内の左、右、直進の運転コマンドの数に基づいて、左折 (L)、右折 (R)、追い越し (O)、および直進 (S) の 4 つのカテゴリに分類されます。この論文ではしきい値 τc を設計しており、クリップ内の左右のコマンドの数がしきい値 τc 以上の場合、それをクリップ内の超越的な動作と見なします。左コマンドの数のみが閾値 τc より大きい場合、左折を示します。右方向のコマンドの数だけが閾値τcより大きい場合、それは右折を示す。他のすべてのケースは直接とみなされます。 3 番目に、各シーンの平均速度を計算し、関連するサブセット内で昇順に並べ替えます。
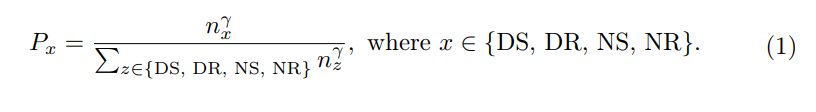
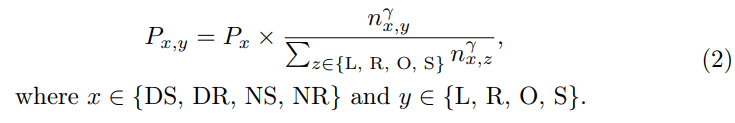
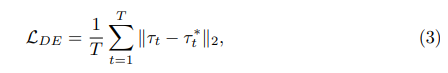
ここで、T はシーン内のフレームを表します。変位誤差自体がパフォーマンス メトリックであるため (注釈は必要ありません)、アクティブな選択では当然、最初で最も重要な基準になります。
標準 2: ソフトコリジョン (SC)。 LSC は、予測される自車両の軌道と予測されるエージェントの軌道の間の距離として定義されます。信頼性の低いエージェントの予測は、しきい値 ε によって除外されます。各シナリオでは、ハザード係数の尺度として最短距離が選択されます。同時に、項と最近接距離との間の正の相関関係を維持します。
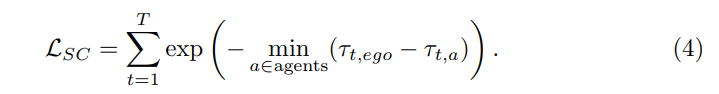
「ソフト衝突」を基準として使用する理由は次のとおりです。 一方で、「変位誤差」とは異なります。 , " 「衝突率」の計算は、ラベルのないデータでは利用できない、ターゲットの 3D ボックスの注釈に依存します。したがって、モデルの推論結果のみに基づいて基準を計算できるはずです。一方、ハード衝突基準を考慮します。予測された自車の軌道が他の予測されたエージェントの軌道と衝突する場合は 1 を割り当て、そうでない場合は 0 を割り当てます。ただし、AD の最先端モデルの衝突率は通常小さい (1% 未満) ため、ラベル 1 のサンプルが少なすぎる可能性があります。したがって、「衝突率」指標の代わりに、他のターゲットのペアまでの最も近い距離を使用することが選択されました。他の車両や歩行者との距離が近すぎる場合、リスクは非常に高くなると考えられます。つまり、「ソフト衝突」は衝突の可能性を測る効果的な尺度であり、集中的な監視を提供できます。
標準 III: エージェントの不確実性 (AU)。周囲のエージェントの将来の軌道の予測は当然ながら不確実であるため、動作予測モジュールは通常、複数のモダリティと対応する信頼スコアを生成します。私たちの目標は、近くのエージェントの不確実性が高いデータを選択することです。具体的には、遠くにある被写体が距離閾値 δ によって除外され、残りの被写体に対する複数のモードの予測確率の重み付きエントロピーが計算されます。モダリティの数が であり、さまざまなモダリティにおけるエージェントの信頼スコアが Pi(a) であると仮定します (i∈{1,…,Nm})。次に、エージェントの不確実性は次のように定義できます。
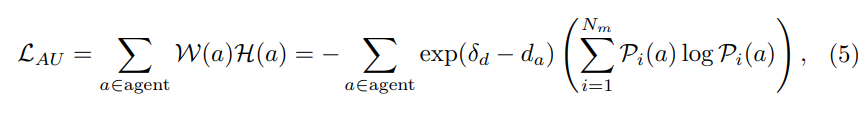

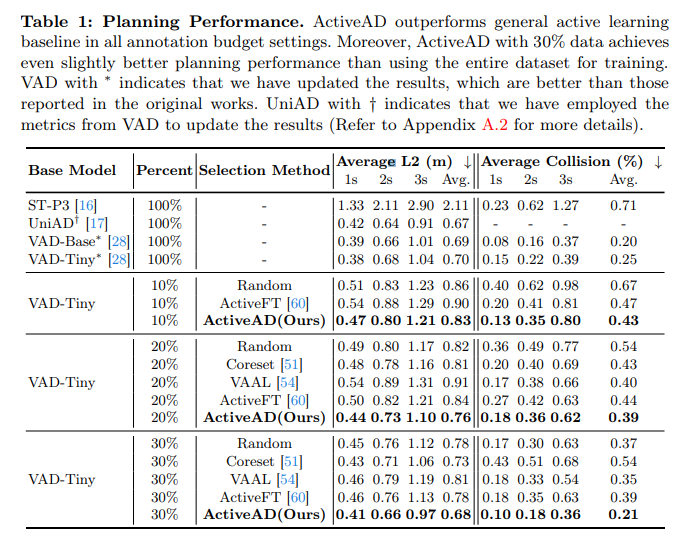 #表 1: 計画のパフォーマンス。 ActiveAD は、すべてのアノテーション予算設定において、一般的なアクティブ ラーニング ベースラインを上回ります。さらに、30% のデータを含む ActiveAD は、データセット全体を使用したトレーニングと比較して、わずかに優れた計画パフォーマンスを達成しました。 * の付いた VAD は、元の研究で報告された結果よりも優れた更新された結果を示します。 UniAD に † が付いている場合は、結果の更新に VAD のインジケーターが使用されていることを示します。
#表 1: 計画のパフォーマンス。 ActiveAD は、すべてのアノテーション予算設定において、一般的なアクティブ ラーニング ベースラインを上回ります。さらに、30% のデータを含む ActiveAD は、データセット全体を使用したトレーニングと比較して、わずかに優れた計画パフォーマンスを達成しました。 * の付いた VAD は、元の研究で報告された結果よりも優れた更新された結果を示します。 UniAD に † が付いている場合は、結果の更新に VAD のインジケーターが使用されていることを示します。
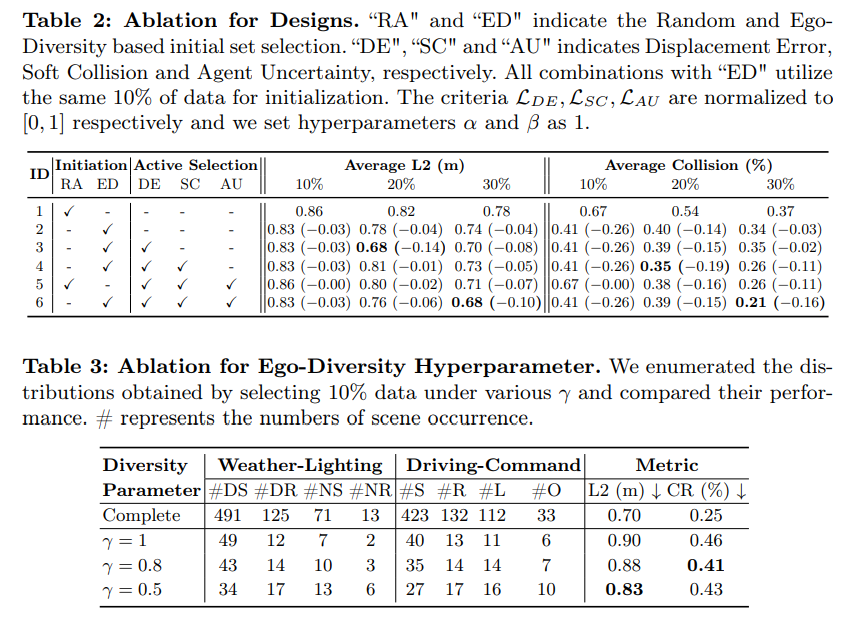 表 2: 計画されたアブレーション実験。 「RA」と「ED」は、ランダム性と自己多様性に基づく初期セットの選択を表します。 「DE」、「SC」、「AU」は変位誤差を表し、それぞれソフト衝突とエージェントの不確実性を表します。 「ED」との組み合わせはすべて同じ 10% データで初期化されます。 LDE、LSC、LAU はそれぞれ [0, 1] に正規化され、ハイパーパラメータ α と β は 1 に設定されます。
表 2: 計画されたアブレーション実験。 「RA」と「ED」は、ランダム性と自己多様性に基づく初期セットの選択を表します。 「DE」、「SC」、「AU」は変位誤差を表し、それぞれソフト衝突とエージェントの不確実性を表します。 「ED」との組み合わせはすべて同じ 10% データで初期化されます。 LDE、LSC、LAU はそれぞれ [0, 1] に正規化され、ハイパーパラメータ α と β は 1 に設定されます。
図 3: 選択したシーンの視覚化。データの 10% でトレーニングされたモデルに基づく、選択されたフロント カメラ画像に基づく、変位誤差 (列 1)、ソフト衝突 (列 2)、エージェントの不確実性 (列 3)、およびハイブリッド (列 4) 基準。混合は、最終的な選択戦略である ActiveAD を表し、最初の 3 つのシナリオが考慮されます。

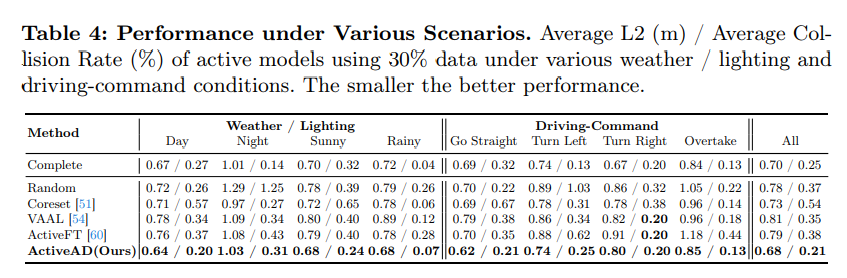
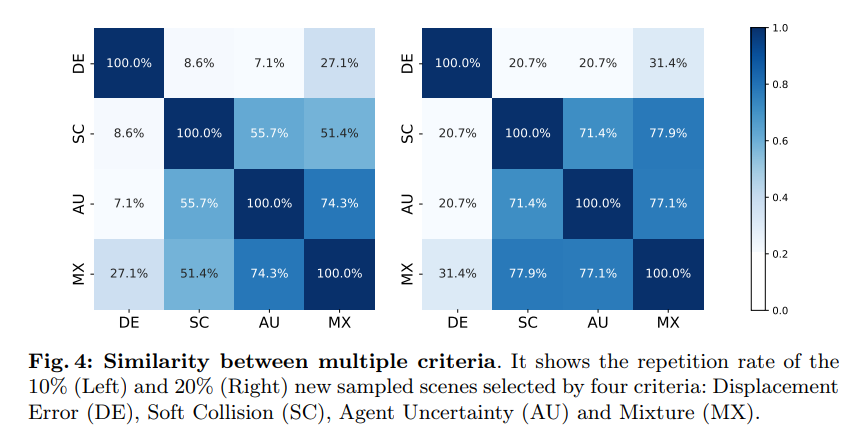 # 図 4: 複数の基準間の類似性。これは、変位誤差 (DE)、ソフト衝突 (SC)、エージェントの不確実性 (AU)、混合 (MX) の 4 つの基準によって選択された 10% (左) と 20% (右) の新しいサンプリング シナリオを示しています
# 図 4: 複数の基準間の類似性。これは、変位誤差 (DE)、ソフト衝突 (SC)、エージェントの不確実性 (AU)、混合 (MX) の 4 つの基準によって選択された 10% (左) と 20% (右) の新しいサンプリング シナリオを示しています
以上がエンドツーエンドでデータがない場合はどうすればよいでしょうか? ActiveAD: 計画のための自動運転のためのエンドツーエンドのアクティブ ラーニング!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



