


大型モデルを90%「スリム化」!清華大学とハルビン工業大学は、容量の 83% を維持しながら 1 ビット量子化という極端な圧縮ソリューションを提案しました。

大規模モデルに対する
定量化、プルーニング、その他の 圧縮操作は、展開の最も一般的な部分です。
しかし、この limit はどれくらいの大きさなのでしょうか?
清華大学とハルビン工業大学による共同研究では、
90% という答えが得られました。
彼らは、大規模モデルの 1 ビット極限圧縮フレームワーク OneBit を提案しました。これにより、大規模モデルの 90% を超える重み圧縮が初めて達成され、ほとんどの (83 %) 機能。
遊びとは「欲しくて欲しがる」ことだと言えます~

見てみましょう。
大規模モデルの 1 ビット量子化方法はこちらです
枝刈りや量子化から知識の蒸留や低ランクの重み分解に至るまで、大規模モデルはすでにほとんどコストを削減することなく重みの 4 分の 1 を圧縮できます。損失。
重み量子化は通常、大規模なモデルのパラメータを低ビット幅表現に変換します。これは、完全にトレーニングされたモデルを変換する (PTQ) か、トレーニング中に量子化ステップを導入する (QAT) ことによって実現できます。このアプローチは、モデルの計算要件とストレージ要件を軽減するのに役立ち、それによってモデルの効率とパフォーマンスが向上します。重みを量子化することで、モデルのサイズを大幅に削減でき、リソースに制約のある環境での展開により適したものになります。また、
ただし、既存の量子化方法は 3 ビット未満で重大なパフォーマンスの低下に直面します。これは主に次のような理由によるものです。 to:
- 既存のパラメータの低ビット幅表現方法では、1 ビットで重大な精度が低下します。 Round-To-Nearest 法に基づくパラメータを 1 ビットで表現すると、変換後のスケーリング係数 s とゼロ点 z は実質的な意味を失います。
- 既存の 1 ビット モデル構造では、浮動小数点精度の重要性が十分に考慮されていません。浮動小数点パラメータの欠如はモデル計算プロセスの安定性に影響を与え、モデル自身の学習能力を大幅に低下させる可能性があります。
1 ビットの超低ビット幅量子化の障害を克服するために、著者は新しい 1 ビット モデル フレームワーク、つまり新しい 1 ビット線形層構造を含む OneBit を提案します。 SVID ベースのパラメータ初期化方法と量子化ベースの認識 知識蒸留のための深層転移学習。
この新しい 1 ビット モデルの量子化方法は、元のモデルの機能のほとんどを保持し、広大な圧縮範囲、超低スペース占有、限られたコンピューティング コストを実現します。これは、大型モデルを PC やスマートフォンに展開する場合に非常に重要です。
全体的なフレームワーク
OneBit フレームワークには通常、新しく設計された 1 ビット モデル構造、元のモデルに基づいて定量化されたモデル パラメーターを初期化する方法、知識の蒸留に基づいた詳細な機能の移行が含まれます。 。
この新しく設計された 1 ビット モデル構造は、以前の量子化作業における 1 ビット量子化における深刻な精度損失の問題を効果的に克服でき、トレーニングおよび移行中に優れた安定性を示します。
定量的モデルの初期化方法は、知識の抽出のためのより良い開始点を設定し、収束を加速し、より優れた能力移転効果を達成することができます。
1. 1 ビット モデルの構造
1 ビットでは、各重み値が 1 ビットでのみ表現できる必要があるため、可能な状態は最大 2 つだけです。
著者は、これら 2 つの状態として ±1 を選択しました。利点は、デジタル システム内の 2 つのシンボルを表し、より完全な機能を備えていることです。同時に、Sign(・) を通じて簡単に取得できることです。関数。
著者の 1 ビット モデル構造は、FP16 モデルのすべての線形層 (埋め込み層と lm_head を除く) を 1 ビット線形層に置き換えることによって実現されます。
Sign(・) 関数によって取得される 1 ビットの重みに加えて、ここの 1 ビット線形層には、他の 2 つの重要なコンポーネント (FP16 精度の値ベクトル) も含まれています。
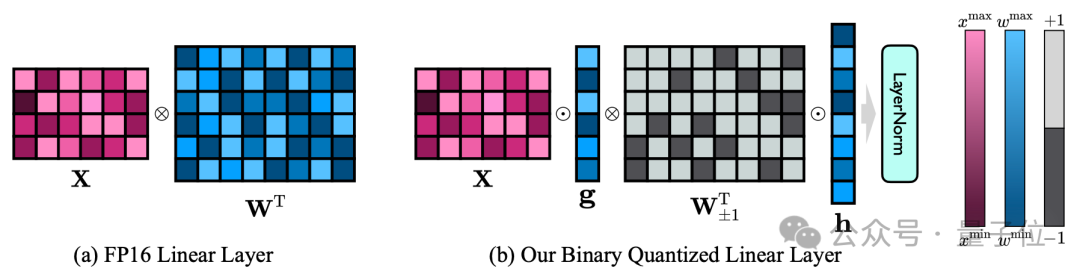
△FP16 線形層と OneBit 線形層の比較
この設計は、元の重み行列の高いランクを維持するだけでなく、必要な浮動小数点の精度は、安定した高品質の学習プロセスを保証するために重要です。
上図からわかるように、値ベクトル g と h のみが FP16 形式を維持しており、重み行列は全体が ±1 で構成されています。
著者は、例を通じて OneBit の圧縮機能を確認できます。
40964096 FP16 線形層が圧縮されていると仮定すると、OneBit には 40964096 1 ビット行列と 2 つの 4096*1 FP16 値ベクトルが必要です。
ビットの総数は 16,908,288、パラメータの総数は 16,785,408 です。平均すると、各パラメータは約 1.0073 ビットしか占有しません。
この種の圧縮範囲は前例がなく、真の 1bit LLM と言えます。
2. パラメーターの初期化と転移学習
完全にトレーニングされた元のモデルを使用して量子化モデルをより適切に初期化するために、著者は新しいパラメーター行列の分解を提案します。この方法は「値符号独立行列因数分解 (SVID)」と呼ばれます。
この行列分解方法は、シンボルと絶対値を分離し、絶対値に対してランク 1 近似を実行します。元の行列パラメータを近似する方法は、次のように表すことができます。
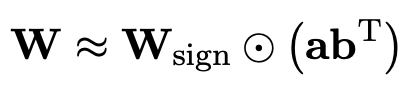
ランク 1 近似は、特異値分解 (SVD) や非負行列因数分解 (NMF) などの一般的な行列因数分解手法によって実現できます。
著者は、この SVID メソッドが演算の順序を交換することで 1 ビット モデルのフレームワークに適合し、それによってパラメーターの初期化が実現できることを数学的に示しています。
さらに、分解プロセス中に元の行列を近似するためのシンボリック行列の貢献も証明されています。詳細については、論文を参照してください。
著者は、大規模モデルの超低ビット幅量子化を解決する効果的な方法は、量子化を意識したトレーニング QAT である可能性があると考えています。
したがって、SVID が定量モデルのパラメーター開始点を与えた後、著者は元のモデルを教師モデルとして使用し、知識の蒸留を通じてそこから学習します。
具体的には、学生モデルは主に教師モデルのロジットと隠れた状態から指導を受けます。
トレーニング中に、値ベクトルとパラメーター行列の値が更新され、デプロイメント中に、量子化された 1 ビットのパラメーター行列を計算に直接使用できます。
モデルが大きいほど効果は高くなります
著者が選択したベースラインは、FP16 Transformer、GPTQ、LLM-QAT、および OmniQuant です。
最後の 3 つはすべて、定量化の分野における古典的な強力なベースラインであり、特に OmniQuant は、著者以前の最強の 2 ビット量子化手法です。
現時点では 1 ビットの重み量子化に関する研究がないため、著者は OneBit フレームワークに対してのみ 1 ビットの重み量子化を使用し、他の方式には 2 ビットの量子化設定を採用します。
蒸留データの場合、著者は LLM-QAT に従い、教師モデルのセルフサンプリングを使用してデータを生成しました。
著者は、1.3B から 13B までのさまざまなサイズのモデル、OPT および LLaMA-1/2 をさまざまなシリーズで使用して、OneBit の有効性を証明しています。評価指標としては、検証セットの複雑さと常識推論のゼロショット精度が用いられます。詳細については論文を参照してください。
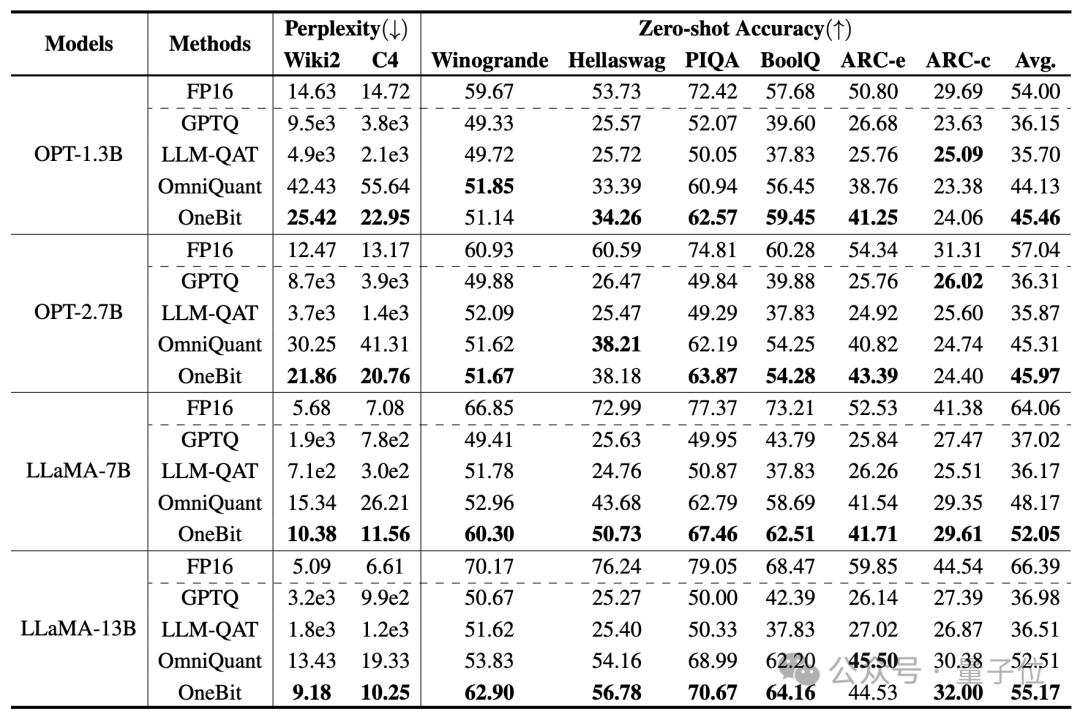
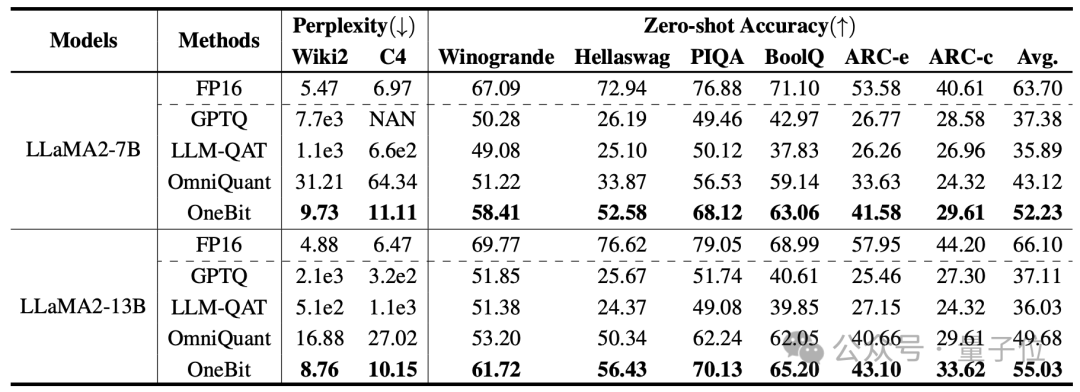
上の表は、1 ビット量子化における他の方法と比較した OneBit の利点を示しています。 モデルが大きいほど、OneBit の効果が高まることは注目に値します。
モデル サイズが大きくなるにつれて、OneBit 定量的モデルは FP16 モデルよりも混乱を軽減します。
以下は、いくつかの異なる小型モデルの常識的な推論、世界の知識、および空間占有です:
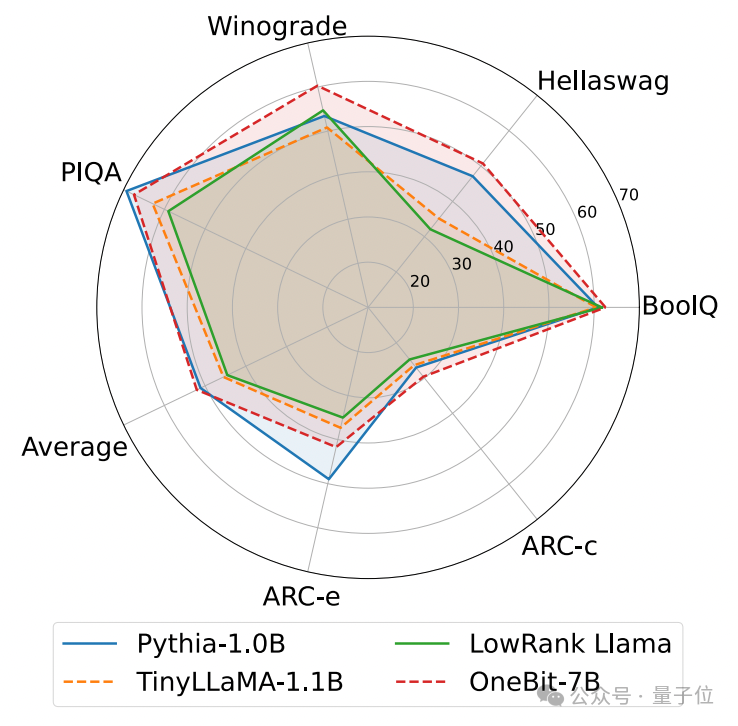
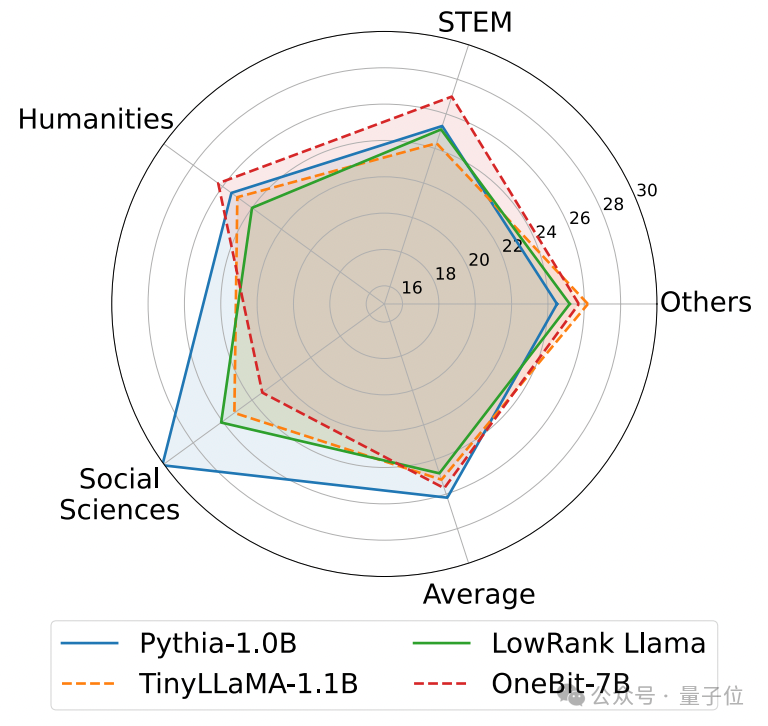
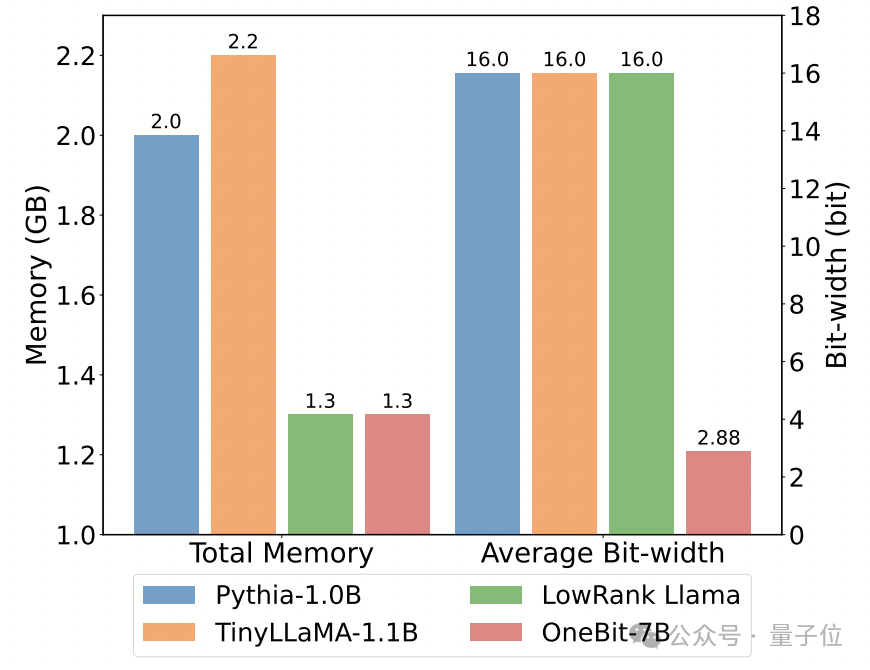
著者は、いくつかの異なるタイプの小型モデルのサイズと実際の機能も比較しました。
著者は、OneBit-7B が平均ビット幅が最も小さく、占有スペースが最も小さく、必要なトレーニング ステップが比較的少ないにもかかわらず、常識的推論能力の点で他のモデルに劣らないことを発見しました。
同時に、著者は、OneBit-7B モデルには社会科学の分野で深刻な知識の忘却があることも発見しました。

△FP16 リニア レイヤーと OneBit リニア レイヤーの比較 OneBit-7B 命令の微調整後のテキスト生成の例
上の図にも示されていますOneBit- 7B 命令を微調整した後の Text 生成例。 OneBit-7B は SFT ステージの能力を効果的に獲得しており、パラメータの合計がわずか 1.3GB (FP16 の 0.6B モデルに相当) であるにもかかわらず、比較的スムーズにテキストを生成できることがわかります。全体として、OneBit-7B は実用的な応用価値を示しています。
分析と考察
著者は、さまざまなサイズの LLaMA モデルに対する OneBit の圧縮率を示しており、モデルに対する OneBit の圧縮率が驚くべき 90% を超えていることがわかります。
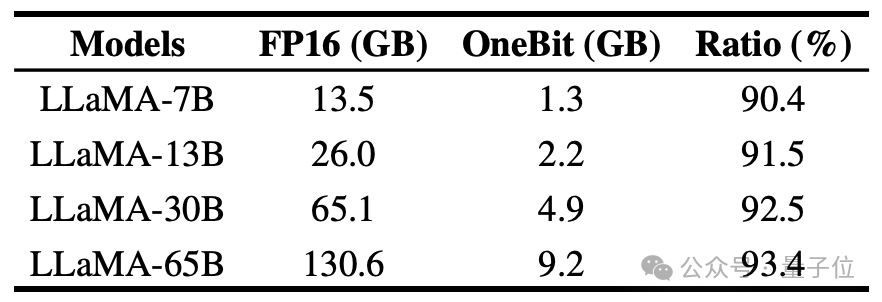
#特に、OneBit はモデルが増えるにつれて圧縮率が高くなります。
これは、より大きなモデルにおける著者の方法の利点を示しています。つまり、より高い圧縮率でより大きな限界ゲイン (複雑さ) が得られます。さらに、著者のアプローチは、サイズとパフォーマンスの間で適切なトレードオフを実現します。 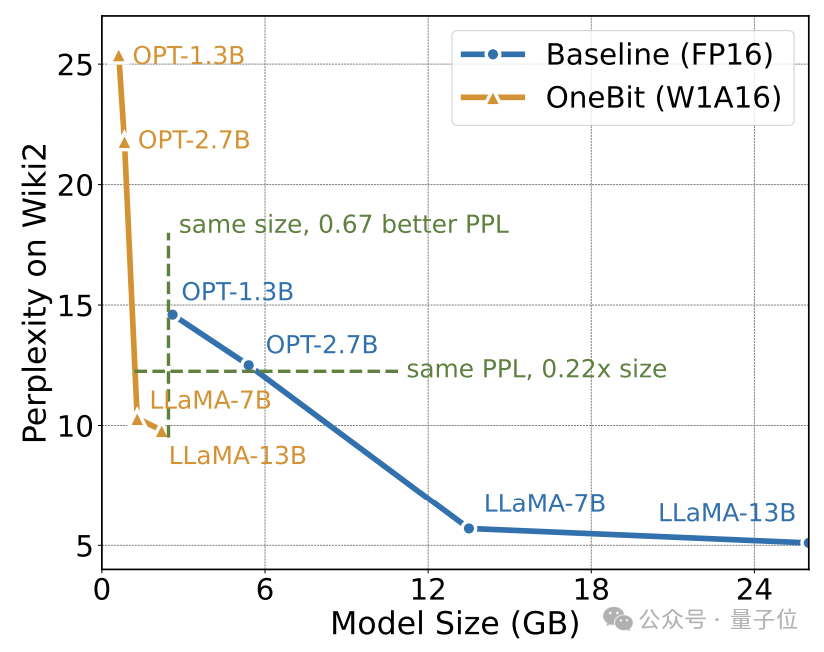
1 ビット定量モデルには計算上の利点があり、非常に重要です。パラメーターの純粋なバイナリ表現は、スペースを大幅に節約できるだけでなく、行列乗算のハードウェア要件も軽減します。
高精度モデルにおける行列乗算の要素乗算を効率的なビット演算に変えることができ、ビットの割り当てと加算のみで行列積が完成するため、応用の可能性が非常に高いです。
さらに、著者の方法は、トレーニング プロセス中に優れた安定した学習能力を維持します。
実際、バイナリ ネットワーク トレーニングの不安定性の問題、ハイパーパラメータに対する感度、および収束の難しさは、研究者によって常に懸念されてきました。
著者は、モデルの安定した収束を促進する上での高精度の値ベクトルの重要性を分析しています。
これまでの研究では 1 ビット モデル アーキテクチャが提案され、それを使用してモデルを最初からトレーニングしていました (BitNet [1] など)。しかし、ハイパーパラメータの影響を受けやすく、完全にトレーニングされた高レベルのモデルから学習を転送するのは困難でした。精密モデル。著者はまた、知識蒸留における BitNet のパフォーマンスを試しましたが、そのトレーニングが十分に安定していないことがわかりました。
要約
著者は、1ビット重み量子化のためのモデル構造とそれに対応するパラメータ初期化方法を提案しました。
さまざまなサイズとシリーズのモデルでの広範な実験により、OneBit には代表的な強力なベースラインで明らかな利点があり、モデルのサイズとパフォーマンスの間で適切なトレードオフが達成されることが示されています。
さらに、著者はこの極低ビット量子化モデルの機能と展望をさらに分析し、将来の研究への指針を提供します。
論文アドレス: https://arxiv.org/pdf/2402.11295.pdf
以上が大型モデルを90%「スリム化」!清華大学とハルビン工業大学は、容量の 83% を維持しながら 1 ビット量子化という極端な圧縮ソリューションを提案しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7343
7343
 9
1627
14
1352
46
1265
25
1214
29
9
1627
14
1352
46
1265
25
1214
29

 GoおよびViperライブラリを使用するときにポインターを渡す必要があるのはなぜですか?
Apr 02, 2025 pm 04:00 PM
GoおよびViperライブラリを使用するときにポインターを渡す必要があるのはなぜですか?
Apr 02, 2025 pm 04:00 PM
ポインター構文とviperライブラリの使用における問題への取り組みGO言語でプログラミングするとき、特にポインターの構文と使用を理解することが重要です...
 携帯電話用の無料のXMLからPDFツールはありますか?
Apr 02, 2025 pm 09:12 PM
携帯電話用の無料のXMLからPDFツールはありますか?
Apr 02, 2025 pm 09:12 PM
モバイルには、単純で直接無料のXMLからPDFツールはありません。必要なデータ視覚化プロセスには、複雑なデータの理解とレンダリングが含まれ、市場のいわゆる「無料」ツールのほとんどは経験がありません。コンピューター側のツールを使用したり、クラウドサービスを使用したり、アプリを開発してより信頼性の高い変換効果を取得することをお勧めします。
 GO言語の範囲を使用してマップを通過してマップを保存するのに、なぜすべての値が最後の要素になるのですか?
Apr 02, 2025 pm 04:09 PM
GO言語の範囲を使用してマップを通過してマップを保存するのに、なぜすべての値が最後の要素になるのですか?
Apr 02, 2025 pm 04:09 PM
GOのマップイテレーションにより、すべての値が最後の要素になるのはなぜですか? Go言語では、いくつかのインタビューの質問に直面したとき、あなたはしばしば地図に遭遇します...
 GOモジュールの下でカスタムパッケージを正しくインポートする方法は?
Apr 02, 2025 pm 03:42 PM
GOモジュールの下でカスタムパッケージを正しくインポートする方法は?
Apr 02, 2025 pm 03:42 PM
GO言語開発では、カスタムパッケージを適切に導入することが重要なステップです。この記事では、「ゴラン...
 XML形式を美化する方法
Apr 02, 2025 pm 09:57 PM
XML形式を美化する方法
Apr 02, 2025 pm 09:57 PM
XMLの美化は、合理的なインデンテーション、ラインブレーク、タグ組織など、本質的に読みやすさを向上させています。原則は、XMLツリーを通過し、レベルに応じてインデントを追加し、テキストを含む空のタグとタグを処理することです。 PythonのXML.ETREE.ELEMENTTREEライブラリは、上記の美化プロセスを実装できる便利なchile_xml()関数を提供します。
 XML形式を確認する方法
Apr 02, 2025 pm 10:00 PM
XML形式を確認する方法
Apr 02, 2025 pm 10:00 PM
XML形式の検証には、その構造とDTDまたはスキーマへのコンプライアンスを確認することが含まれます。 ElementTree(基本的な構文チェック)やLXML(より強力な検証、XSDサポート)など、XMLパーサーが必要です。検証プロセスでは、XMLファイルを解析し、XSDスキーマをロードし、AssertValidメソッドを実行してエラーが検出されたときに例外をスローすることが含まれます。 XML形式の確認には、さまざまな例外を処理し、XSDスキーマ言語に関する洞察を得る必要があります。
 GOでロックを使用するコードが時々パニックにつながるのはなぜですか?
Apr 02, 2025 pm 04:36 PM
GOでロックを使用するコードが時々パニックにつながるのはなぜですか?
Apr 02, 2025 pm 04:36 PM
ロックを使用すると、なぜパニックを引き起こすのですか?興味深い質問を見てみましょう。コードにロックが追加されたとしても、時々...
 GO言語では、工場モードを介して異なるインターフェイスの異なるパブリックメソッドパラメータータイプの問題を解決する方法は?
Apr 02, 2025 pm 04:39 PM
GO言語では、工場モードを介して異なるインターフェイスの異なるパブリックメソッドパラメータータイプの問題を解決する方法は?
Apr 02, 2025 pm 04:39 PM
GO言語では、共通のインターフェイスを定義し、インターフェイスによって実装されたメソッドを制約し、同時に異なるインターフェイスの同じ方法と異なるパラメータータイプを処理する方法...
