もうすぐ、「Vincentian グラフィックスの新しい王様」である Stable Diffusion 3 の技術レポートがここに公開されます。
全文は計28ページに及び、誠意が詰まっています。

# 「古いルール」、プロモーション ポスター (⬇️) はモデルを使用して直接生成され、テキスト レンダリング機能を誇示します:
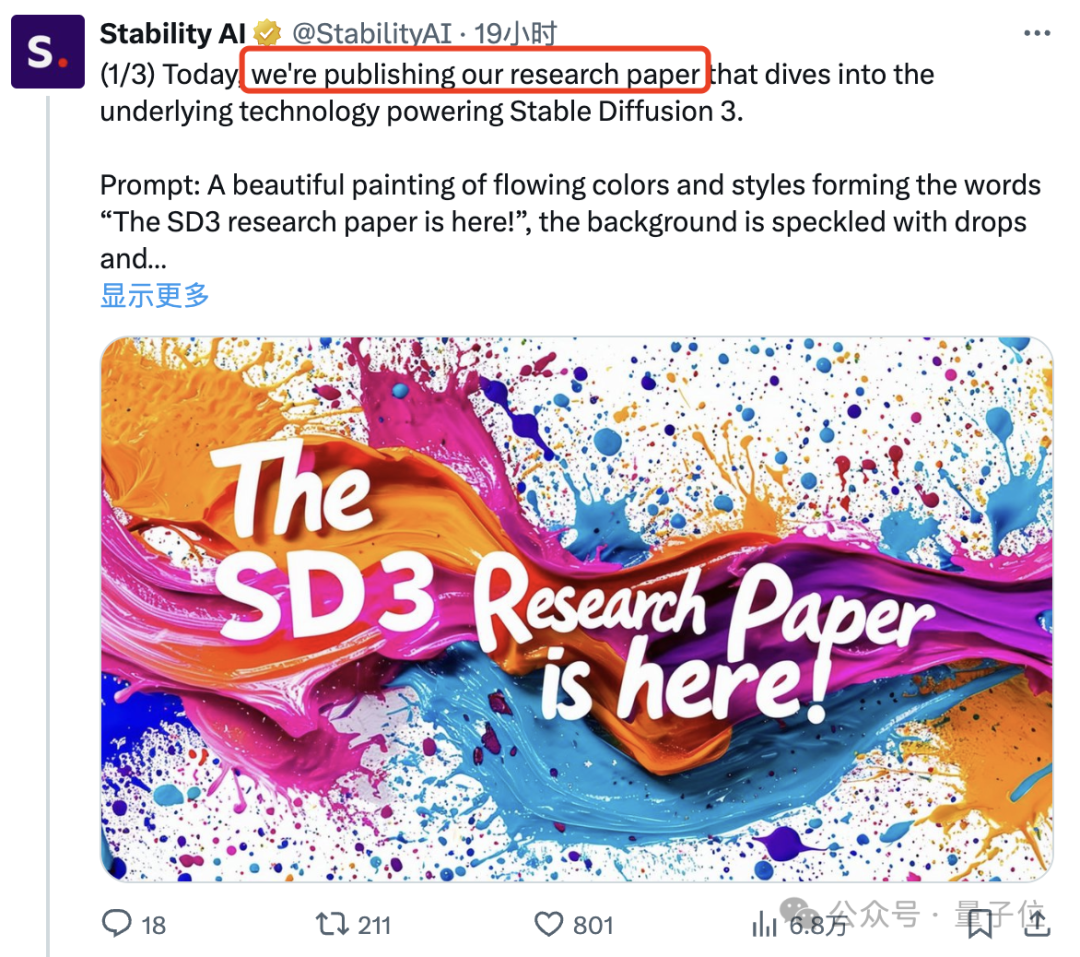
それでは、DALL・E 3 や Midjourney v6 よりも強力な SD3 は、どのようにしてテキストやコマンドに従うスキルを強化するのでしょうか?
技術レポートで明らかになった点:
これはすべて、マルチモーダル拡散 Transformer アーキテクチャ MMDiT に依存しています。
画像とテキストの表現に異なる重みのセットを適用することで、以前のバージョンよりも強力なパフォーマンスの向上が達成され、これが成功の鍵です。
レポートを開いて詳細を確認してみましょう。
テキスト レンダリング機能を向上させるための DiT の微調整
SD3 のリリースの開始時に、公式はそのアーキテクチャが Sora と同じ起源を持ち、拡散型 Transformer-DiT であることを明らかにしました。
これで答えが明らかになります:
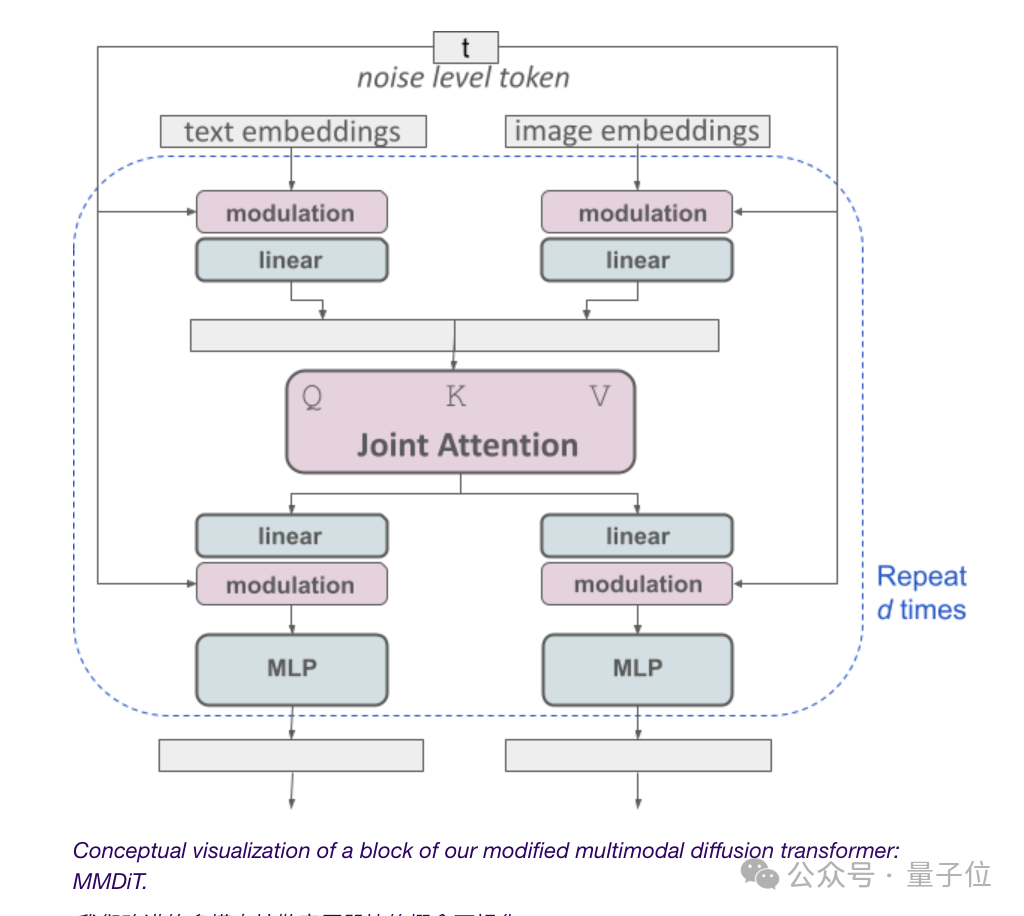
ヴィンセント グラフ モデルはテキスト モードと画像モードの両方を考慮する必要があるため、Stability AI は DiT よりも一歩進んで、新しいアーキテクチャ MMDiT を提案します。
ここでの「MM」は「マルチモーダル」を指します。
以前のバージョンの Stable Diffusion と同様に、公式は 2 つの事前トレーニングされたモデルを使用して、適切なテキストと画像表現を取得します。
テキスト表現のエンコードは、2 つの CLIP モデルと T5 モデルを含む 3 つの異なるテキスト エンベッダー (エンベッダー) を使用して行われます。
画像トークンのエンコードは、改良されたオートエンコーダー モデルを使用して完了します。
テキストと画像の埋め込みは概念的には同じものではないため、SD3 はこれら 2 つのモードに対して 2 セットの独立した重みを使用します。
(一部のネチズンは苦情を申し立てました: このアーキテクチャ図は「人類完成プロジェクト」を開始するようです、ええと、はい、一部の人々は「『新世紀エヴァンゲリオン』を見たばかりです。私は今クリックしました」このレポートに入力する情報については、")
本題に戻りますが、上の図に示すように、これはモダリティごとに 2 つの独立した変圧器があることに相当しますが、それらのシーケンスは、アテンション操作のために連結されます。
このようにして、両方の表現をそれぞれの空間で機能させながら、他方の表現を考慮することができます。
最終的に、この方法を通じて、画像とテキスト トークンの間で情報が「流れる」ことができ、出力時のモデルの全体的な理解とテキスト レンダリング機能が向上します。
そして、前に示したように、このアーキテクチャはビデオやその他のモードに簡単に拡張できます。

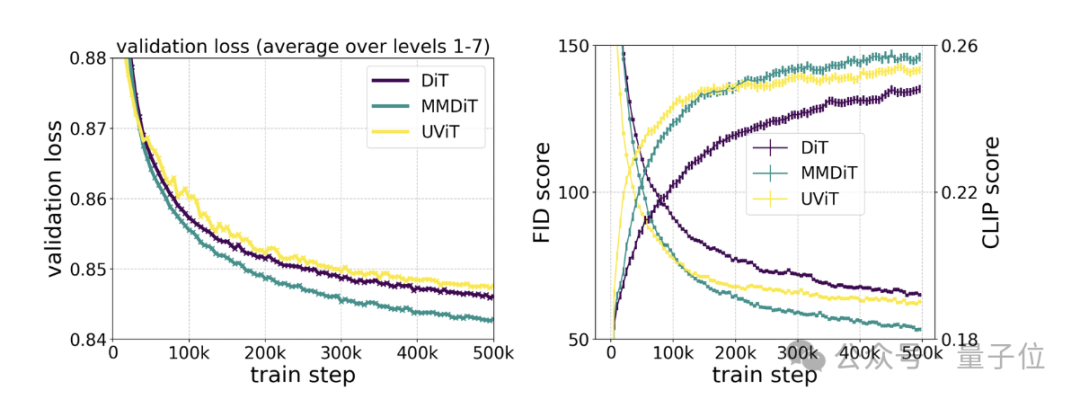
具体的なテストでは、MMDiT が DiT の中で DiT よりも優れていることが示されています:
トレーニング プロセス中の視覚的な忠実性とテキストの配置の両方が備わっています。 UViT や DiT などのテキストから画像へのバックボーン。
パフォーマンスを継続的に向上させるためのフロー テクノロジーの重み付けを見直しました
リリースの初めに、拡散トランスフォーマー アーキテクチャに加えて、公式は SD3 に次の機能が組み込まれていることも明らかにしました。フローマッチング。
「流れ」とは何でしょうか?
本日公開された論文のタイトルで明らかになったように、SD3 は「Rectified Flow」(RF) を使用します。

ICLR2023に採択された「極めて簡素化されたワンステップ生成」の新しい拡散モデル生成手法です。
これにより、トレーニング中にモデルのデータとノイズを線形軌道で接続できるようになり、サンプリングに使用するステップが少なくなる、より「直線的な」推論パスが得られます。
RF に基づいて、SD3 はトレーニング プロセス中に新しい軌道サンプリングを導入します。
著者は、これらの部分がより困難な予測タスクを完了すると想定しているため、軌道の中央部分により多くの重みを与えることに重点を置いています。
この生成メソッドを、複数のデータセット、メトリクス、サンプラー構成にわたる 60 の他の拡散軌跡メソッド (LDM、EDM、ADM など) に対してテストしたところ、次のことが判明しました。
一方、以前の RF メソッドは、数ステップのサンプリング スキームですが、ステップ数が増えると相対的なパフォーマンスが低下します。
対照的に、SD3 の再重み付けされた RF バリアントでは、一貫してパフォーマンスが向上しています。
モデルの機能はさらに改善可能です
当局は、再重み付けされた RF 手法と MMDiT アーキテクチャを使用したテキストから画像への生成に関するスケーリング研究を実施しました。
トレーニングされたモデルの範囲は、4 億 5,000 万のパラメーターを含む 15 モジュールから、80 億のパラメーターを含む 38 モジュールまで多岐にわたります。
彼らは、モデルのサイズとトレーニング ステップが増加するにつれて、検証損失が滑らかな下降傾向を示すこと、つまり、モデルが継続的な学習を通じてより複雑なデータに適応することを観察しました。
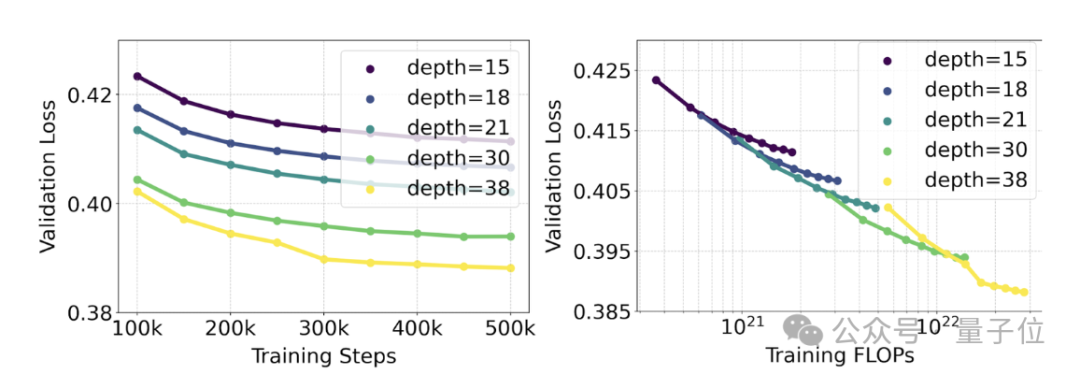
#これがモデル出力のより有意義な改善につながったかどうかをテストするために、自動画像位置合わせメトリクス (GenEval) と人間の評価も行いました。好みの評価 (ELO) 。
結果は次のとおりです:
この 2 つの間には強い相関関係があります。つまり、検証損失は、モデル全体のパフォーマンスを予測するための非常に強力な指標として使用できます。
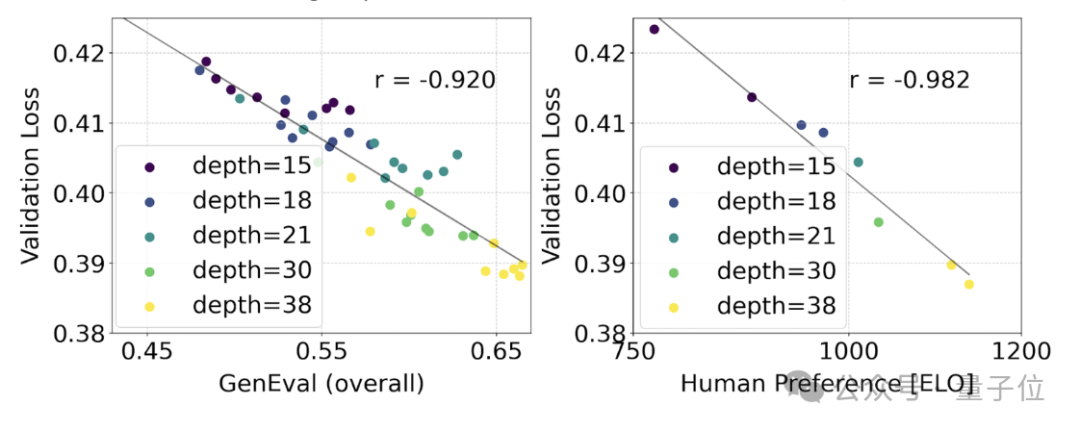
さらに、ここでの拡張傾向は飽和の兆候を示していないため (つまり、モデル サイズが増加してもパフォーマンスは依然として向上しており、限界に達していません) 、関係者は楽観的です:
SD3 のパフォーマンスは将来的に向上し続ける可能性があります。
最後に、技術レポートではテキスト エンコーダの問題についても言及しています。
推論に使用されるメモリ集約型の T5 テキスト エンコーダである 47 億パラメータを削除することにより、SD3 のメモリ要件が大幅に削減される可能性があります。削減されましたが、同時にパフォーマンスの損失は非常にわずかです (勝率は 50% から 46% に低下しました)。
ただし、テキスト レンダリング機能の観点から、当局は依然として T5 を削除しないことを推奨しています。これは、T5 がないとテキスト表現の勝率が 38% に低下するためです。

要約すると、SD3 の 3 つのテキスト エンコーダーのうち、テキスト (および非常に詳細なシーン説明画像) を含む画像を生成する場合、T5 が最も大きく貢献します。
ネチズン: オープンソースへの取り組みは予定通り完了しました、ありがとう
SD3レポートが発表されるとすぐに、多くのネチズンはこう言いました:
安定性AIオープンソースへの取り組みが予定通り果たせたことは大変喜ばしいことであり、今後も末永く運営していただきたいと願っています。

OpenAI の名前を発表したばかりの人がまだいます:

さらに嬉しいことです。コメント エリアで言及されている:
SD3 モデルのすべての重みをダウンロードできます。現在の計画では、パラメータは 8 億個、パラメータは 20 億個、パラメータは 80 億個です。


速度はどうですか?
ああ、技術レポートには次のように記載されています:
80 億 SD3 で 24GB RTX 4090 で 1024*1024 画像を生成するには 34 秒かかります (50 サンプリング ステップ)——しかしこれは、最適化を行わない初期の予備的な推論テストの結果にすぎません。
レポートの全文: https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable Diffusion 3 Paper.pdf。
参考リンク:
[1]https://stability.ai/news/stable-diffusion- 3-研究論文。
[2]https://news.ycombinator.com/item?id=39599958。
以上がStable Diffusion 3 技術レポートがリリース: Sora と同じアーキテクチャの詳細が明らかにの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



