


「これは決して単純な切り抜きではありません。」
ControlNet 著者最新の研究は高い注目を集めています---
プロンプトを表示します。安定拡散を使用して、単一または複数の透明レイヤー (PNG) を直接生成できます。
例:
髪がボサボサの女性が寝室にいます。

ご覧のとおり、AI はプロンプトに準拠した完全な画像を生成しただけでなく、 背景は文字 から分離することもできます。
そして、キャラクター PNG 画像を拡大してよく見てみると、髪束が明確に定義されていることがわかります。

別の例を見てみましょう:
田舎のテーブルの上で薪を燃やしています。
田舎のテーブルの上で薪を燃やしています。

同様に、「燃えているマッチ」の PNG (黒煙まで) を拡大してください。

これは、ControlNet の作者によって提案された新しい方法です - LayerDiffusion により、大規模な事前処理が可能になります。潜在拡散モデル (潜在拡散モデル) のトレーニングにより、透明な画像が生成されます。

LayerDiffusion は決してカットアウトほど単純ではなく、を生成することに焦点を当てていることを再度強調する価値があります。
ネチズンが言ったように:これは、現在のアニメーションとビデオ制作の中核プロセスの 1 つです。このステップを通過できれば、SD の整合性は問題ではなくなったと言えます。
結果が出るまでにとても時間がかかりました。
潜在透明度 (潜在透明度) と呼ばれるメソッドです。
簡単に言えば、事前トレーニングされた潜在拡散モデル(安定拡散など) の潜在分布を破壊することなく、モデルに透明性を追加することができます。
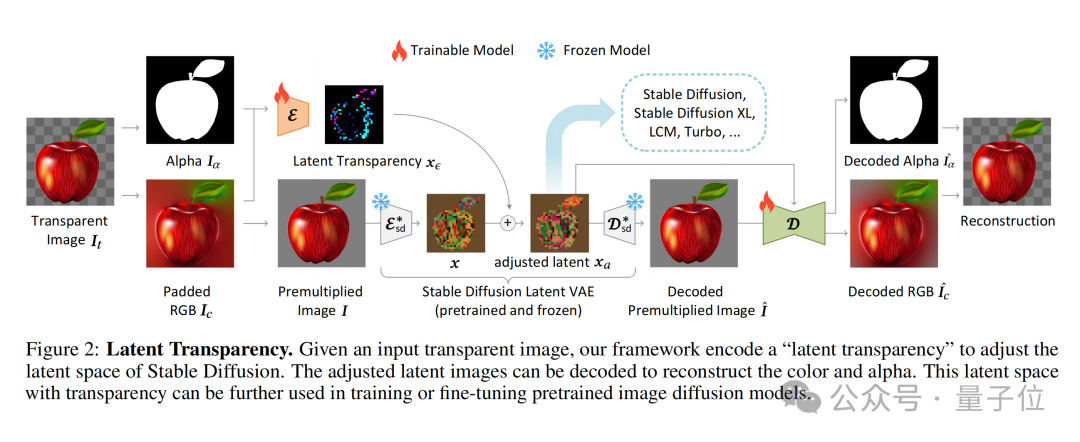
具体的な実装に関しては、慎重に設計された小さな摂動 (オフセット) を潜像に追加すると理解できます。この摂動は追加のチャネルとしてエンコードされ、RGB チャネルとともに構成されます。完全な潜在的なイメージ。
透明度のエンコードとデコードを実現するために、著者は 2 つの独立したニューラル ネットワーク モデルをトレーニングしました。1 つは 潜在透明度エンコーダー(潜在透明度エンコーダー)、もう 1 つは 潜在透明度エンコーダー (潜在透明度エンコーダー)もう 1 つは
潜在透明デコーダ (潜在透明デコーダ)です。
エンコーダは、元の画像の RGB チャネルとアルファ チャネルを入力として受け取り、透明度情報を潜在空間内のオフセットに変換します。 デコーダは、調整された潜像と再構築された RGB 画像を受け取り、潜像空間から透明度情報を抽出して元の透明度画像を再構築します。
追加された潜在的な透明性が事前トレーニングされたモデルの基礎となる分布を破壊しないことを保証するために、著者らは「無害性」の尺度
を提案しています。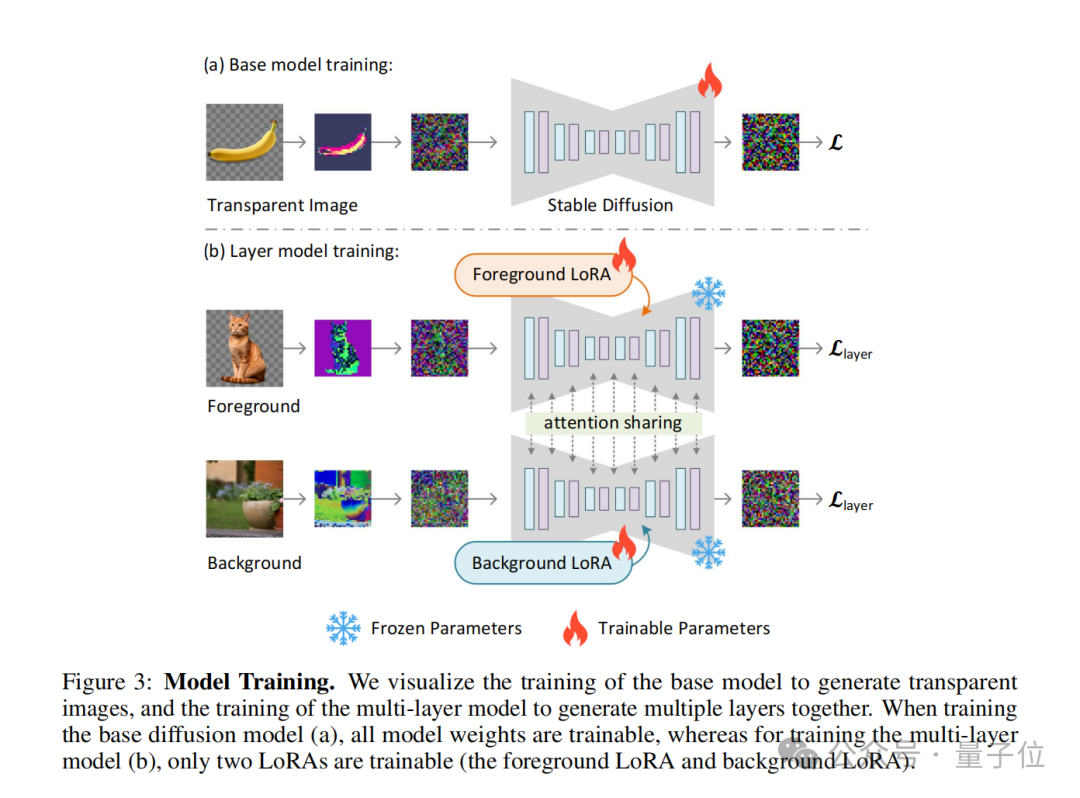 このメトリクスは、元の事前トレーニング済みモデルのデコーダーによる調整された潜在画像のデコード結果を元の画像と比較することにより、潜在透明度の影響を評価します。
このメトリクスは、元の事前トレーニング済みモデルのデコーダーによる調整された潜在画像のデコード結果を元の画像と比較することにより、潜在透明度の影響を評価します。
トレーニング プロセス中に、著者は結合損失関数 (結合損失関数) も使用します。これは、再構成損失 ( 再構築loss)
、アイデンティティ損失 (アイデンティティ損失)、および識別子損失。
このアプローチを使用すると、調整された潜在空間に合わせて微調整するだけで、あらゆる潜在拡散モデルを透明画像ジェネレーターに変換できます。 
潜在透明度の概念は、複数の透明レイヤーを生成するように拡張することもできます。また、他の条件付き制御システムと組み合わせて、前景/背景 条件付き生成、ジョイントレイヤー生成、レイヤー内容の構造制御など



##LayerDiffusion と従来のカットアウトの違いを簡単にまとめると以下の点になります。
ネイティブ生成と後処理
LayerDiffusion は、生成プロセス中に透明度情報を直接考慮してエンコードする、ネイティブの透明イメージ生成方法です。これは、モデルが画像生成時にアルファ チャネルを作成し、透明度のある画像を生成することを意味します。 従来のマット方法では通常、最初に画像を生成または取得し、次に画像編集技術
(クロマ キー、エッジ検出、ユーザー指定のマスクなど)を使用して画像を分離します。前景と背景。このアプローチでは、透明度を処理するために追加の手順が必要になることが多く、複雑な背景やエッジに不自然な遷移が生じる可能性があります。
潜在空間操作とピクセル空間操作LayerDiffusion は、潜在空間 (潜在空間) で動作します。これは、モデルがより複雑な画像特徴を学習して生成できるようにする中間表現です。潜在空間で透明度をエンコードすることにより、モデルはピクセル レベルでの複雑な計算を必要とせずに、生成中に透明度を自然に処理できます。 従来のカットアウト技術は通常、ピクセル空間で実行され、色の置換やエッジのスムージングなど、元の画像の直接編集が含まれる場合があります。これらの方法では、半透明のエフェクト (火、煙など) や複雑なエッジの処理が難しい場合があります。 データセットとトレーニング LayerDiffusion はトレーニングに大規模なデータセットを使用します。このデータセットには透明な画像のペアが含まれており、モデルが高精細度の生成を学習できるようになります。高品質の透明画像には複雑な分散が必要です。 従来のマッティング手法は、より小規模なデータ セットや特定のトレーニング セットに依存する可能性があり、多様なシナリオを処理する能力が制限される可能性があります。 柔軟性と制御 LayerDiffusion では、ユーザーがテキスト (テキスト プロンプト) を介してプロンプトを表示できるため、柔軟性と制御が向上します。画像を生成し、ブレンドして組み合わせて複雑なシーンを作成できる複数のレイヤーを生成できます。 従来のカットアウト方法は、特に複雑な画像コンテンツや透明度を扱う場合、制御がより制限される可能性があります。 品質比較 ユーザー調査によると、LayerDiffusion によって生成された透明な画像は、ほとんどの場合、ユーザーに好まれることがわかっています (97%) 。これは、透明度が高いことを示しています。生成されるコンテンツは、商用の透明な資産と視覚的に同等か、場合によってはそれよりも優れています。 Zhang Lumin の発明者です。 
以上がControlNet 作者の新作: AI ペイントはレイヤーに分割可能!このプロジェクトはオープンソースではないにもかかわらず 660 個の星を獲得しましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



