


Sora の後に、実は新しい AI ビデオ モデルがあり、これはとても素晴らしいもので、誰もが気に入って賞賛しています。
 写真
写真
これで、「クロニクス」の悪役ガオ・チー強がルオ・シャンに変身し、みんなを教育できるようになります(犬頭)。

これは、Alibaba の最新のオーディオ主導のポートレート ビデオ生成フレームワーク、EMO (Emote Portrait Alive) です。
これを使えば、1枚の参考画像と音声(スピーチ、歌、ラップなども可)を入力するだけで、生き生きとした表情のAI動画を生成できます。ビデオの最終的な長さは、入力音声の長さによって異なります。
AI エフェクト体験のベテラン出場者であるモナ リザにモノローグを朗読してもらうことができます:

若くてハンサムな小さなプラムが登場します。このペースの速い RAP タレント ショーでは、口の形についていくのに問題はありませんでした。

広東語のリップシンクさえも続けることができ、弟のレスリー チャンはそれを可能にしました。イーソン・チャンの「無条件」を歌う:

#要するに、肖像画に歌わせるか(さまざまなスタイルの肖像画や歌)、肖像画にしゃべらせるか(さまざまな言語)、またはあらゆる種類の「大げさな」ものを作るためです。俳優を超えたパフォーマンスとEMO効果には、私たちはしばらく唖然としました。
ネチズンは嘆いた:「私たちは新たな現実に入りつつある!」
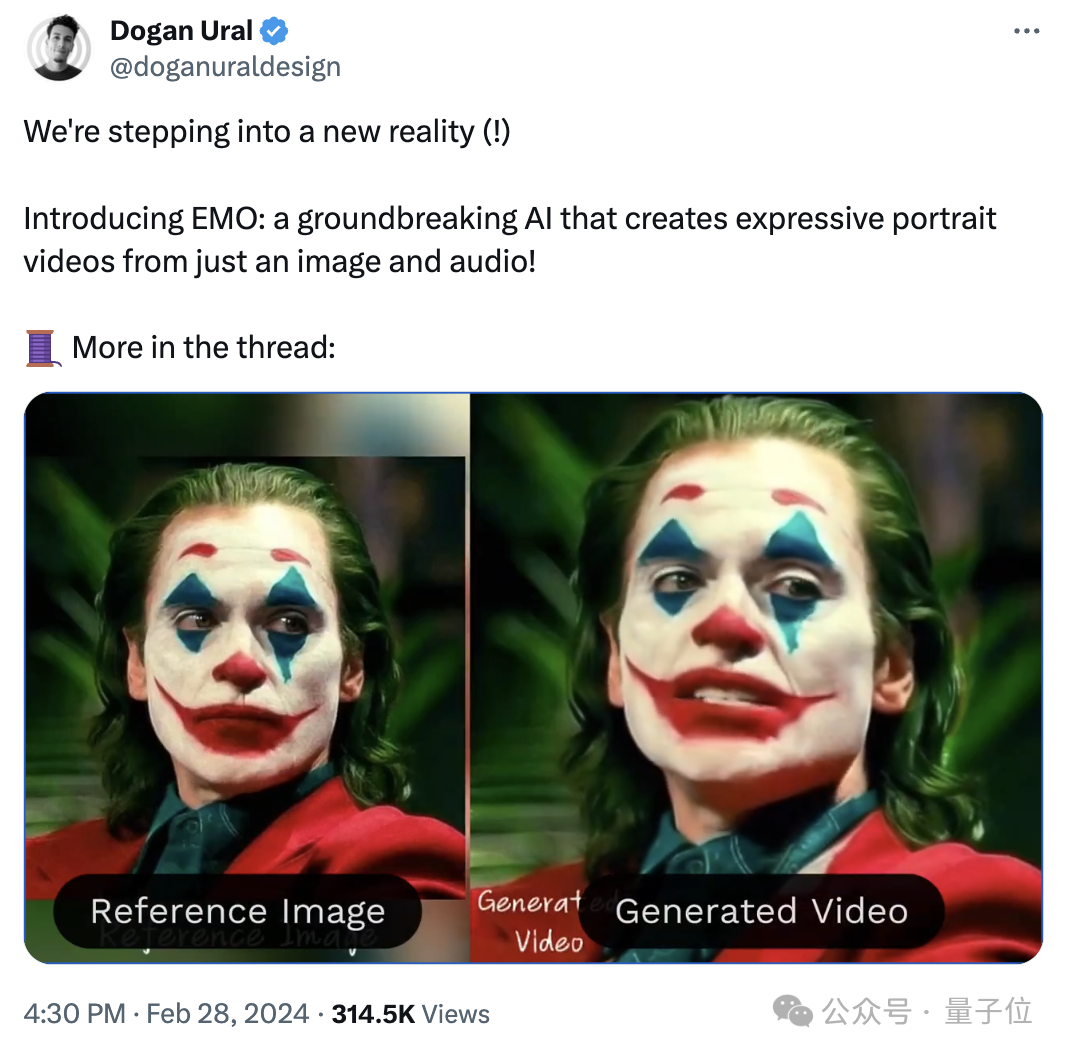 2019年版『ジョーカー』は2008年版『ダークナイト』のセリフを言った
2019年版『ジョーカー』は2008年版『ダークナイト』のセリフを言った
一部のネチズンは、EMO で生成されたビデオのビデオを取得し、その効果をフレームごとに分析し始めています。
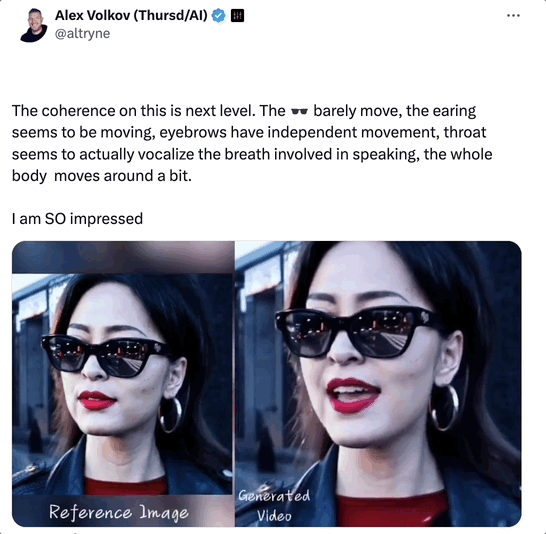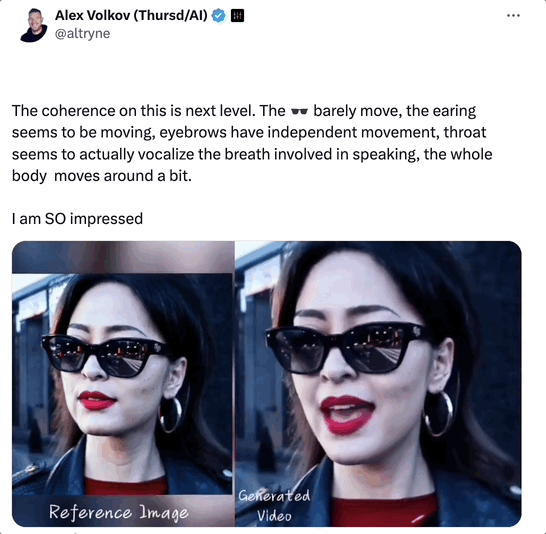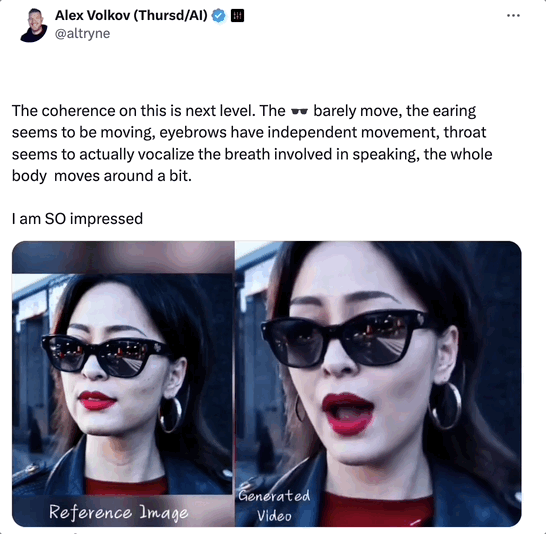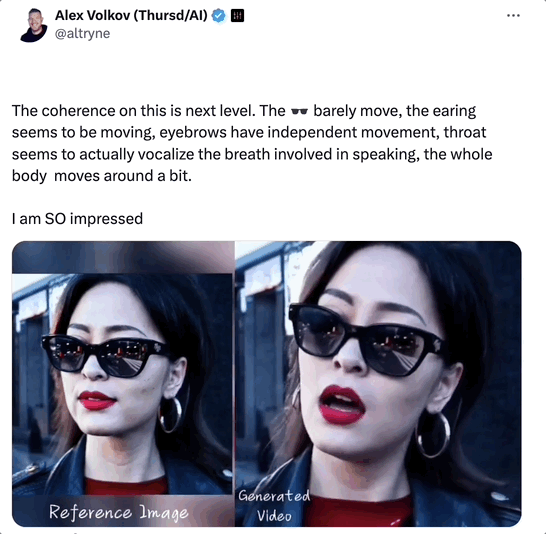
下の動画にあるように、主人公はソラが生成したAIレディで、今回彼女が歌ってくれたのは「Don’t Start Now」です。
コメント投稿者が分析:
このビデオの一貫性は以前よりもさらに優れています。
1分以上の動画では、ソラさんの顔のサングラスはほとんど動かず、耳と眉毛が独立して動きました。
一番興奮したのは、そらさんの喉が本当に息をしているように見えることです!歌いながら体が震えたり、微妙に動いたりして、衝撃を受けました!
 写真
写真
昨日、AI動画生成会社ピカも動画キャラクターの吹き替えと「口パク」を同時に行う口パク機能をリリースし、大ヒットしました。 具体的な効果は何ですか? 直接ここに載せます

 写真
写真
 これは、ジジ王と同じくらいネットユーザーを本当に不安にさせました。
これは、ジジ王と同じくらいネットユーザーを本当に不安にさせました。
Sora とは異なるアーキテクチャ
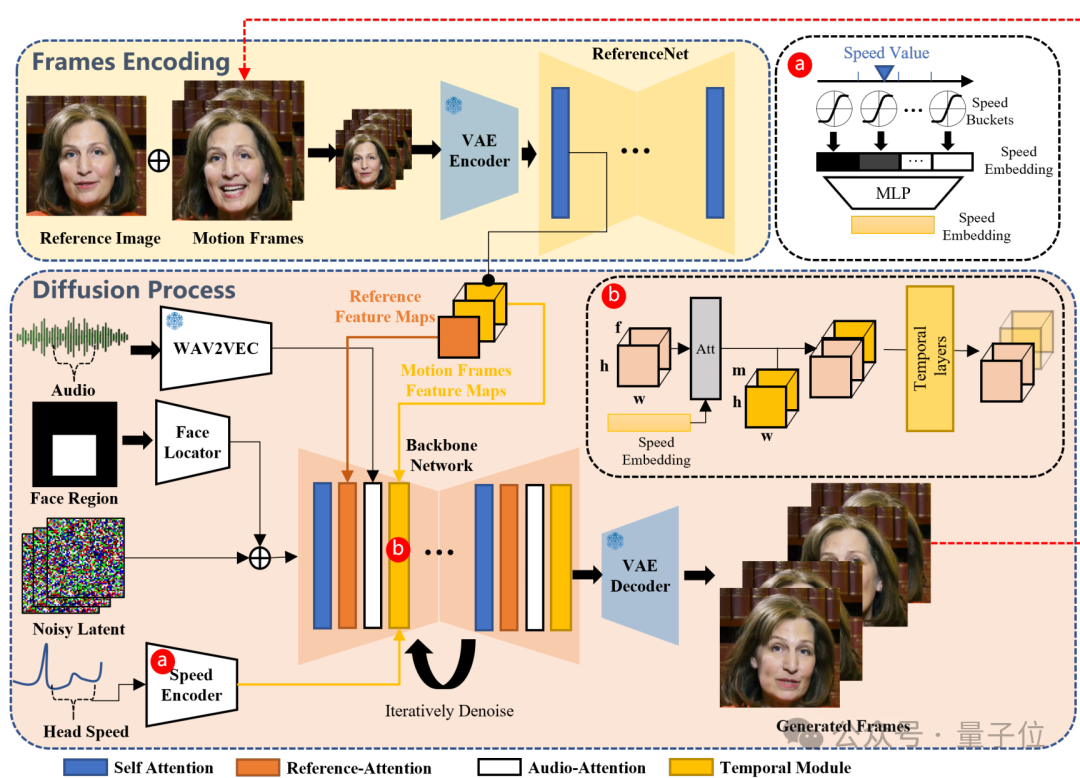
EMO は DiT のようなアーキテクチャに基づいていません。つまり、Transformer は従来の UNet を置き換えるために使用されていません。そのバックボーン ネットワークは Stable Diffusion 1.5 から変更されています。
具体的には、EMO は、入力ビデオの長さに基づいて任意の長さのビデオを生成できる、表現力豊かなオーディオ主導のポートレート ビデオ生成フレームワークです。
 #画像
#画像
バックボーン ネットワークがノイズ除去操作を主導します。バックボーン ネットワークでは、リファレンス アテンションとオーディオ アテンションという 2 種類のアテンションが適用され、それぞれキャラクターのアイデンティティの一貫性を維持し、キャラクターの動きを制御します。
さらに、時間モジュールは時間次元を操作し、動きの速度を調整するために使用されます。
トレーニング データに関しては、チームは 250 時間以上のビデオと 1,500 万以上の画像を含む、大規模で多様な音声およびビデオ データ セットを構築しました。
最終実装の具体的な機能は次のとおりです。
キャラクターのアイデンティティの一貫性を確保しながら、入力音声に基づいて任意の長さのビデオを生成できます (指定された最長の単一ビデオ)デモは 1 分 49 秒です)。写真  # 口の形状を測定するだけで SOTA を取得する以前の方法と比較して、定量的な比較も大幅に改善されました。 SyncNet の同期品質の指標は若干劣ります。
# 口の形状を測定するだけで SOTA を取得する以前の方法と比較して、定量的な比較も大幅に改善されました。 SyncNet の同期品質の指標は若干劣ります。
写真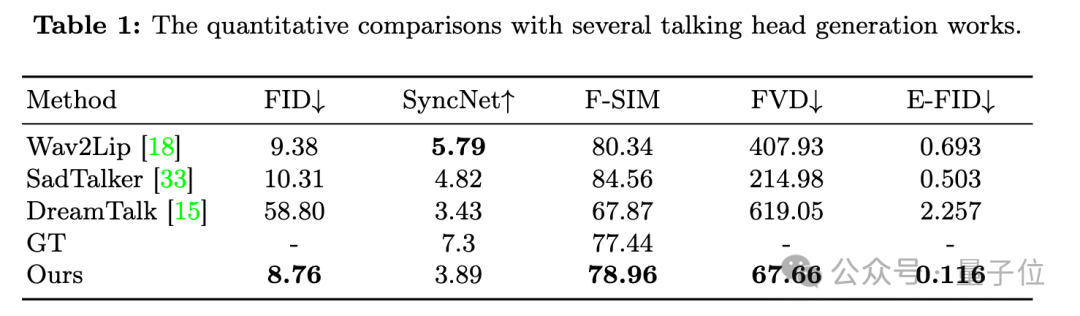 拡散モデルに依存しない他の方法と比較して、EMO は時間がかかります。
拡散モデルに依存しない他の方法と比較して、EMO は時間がかかります。
そして、明示的な制御信号が使用されていないため、手などの他の身体部分が不用意に生成される可能性があるため、潜在的な解決策は、特に身体部分に制御信号を使用することです。
EMO のチーム
この論文は、EMO チームがアリババ インテリジェント コンピューティング研究所から来ていることを示しています。
著者は Linrui Tian、Qi Wang、Bang Zhang、Liefeng Bo の 4 人です。
写真 このうち、リーフェン・ボー氏はアリババ同義研究所のXR研究室の現所長です。
このうち、リーフェン・ボー氏はアリババ同義研究所のXR研究室の現所長です。
Bo Liefeng 博士は、西安電子科学技術大学を卒業し、シカゴ大学トヨタ研究所およびワシントン大学で博士研究員研究に従事し、主に ML、 CVとロボット工学。 Google Scholar での引用数は 13,000 を超えています。
アリババに入社する前は、まずアマゾンのシアトル本社でチーフサイエンティストを務め、その後、JD Digital Technology Group の AI 研究所にチーフサイエンティストとして加わりました。
2022 年 9 月、薄烈峰氏はアリババに入社しました。
写真 アリババが AIGC 分野で成功を収めたのは、EMO が初めてではありません。
アリババが AIGC 分野で成功を収めたのは、EMO が初めてではありません。
写真 OutfitAI を使えば誰でもワンクリックでドレスアップできます。
OutfitAI を使えば誰でもワンクリックでドレスアップできます。
写真 世界中の犬や猫にお風呂ダンスを踊らせる AnimateAnyone もあります。
世界中の犬や猫にお風呂ダンスを踊らせる AnimateAnyone もあります。
これは以下のものです:
写真 EMOが開始された今、多くのネチズンはアリババが何らかのテクノロジーを蓄積していることを嘆いていますその上で。
EMOが開始された今、多くのネチズンはアリババが何らかのテクノロジーを蓄積していることを嘆いていますその上で。
 写真
写真
これらのテクノロジーをすべて組み合わせると、その効果は次のようになります...
あえて考えませんが、でも本当に楽しみです。
 写真
写真
つまり、「AIにスクリプトを送って動画全体を出力する」という状況にどんどん近づいています。
 写真
写真
Sora は、テキスト駆動のビデオ合成における崖っぷちの画期的な進歩を表します。
EMO は、新しいレベルのオーディオ駆動型ビデオ合成も表します。
2 つのタスクは異なり、具体的なアーキテクチャも異なりますが、重要な共通点が 1 つあります:
中間に明示的な物理モデルはありませんが、両方とも物理法則をシミュレートします。ある程度まで。 。
したがって、一部の人々は、これは「ピクセルを生成してアクションの世界をモデル化することは無駄であり、失敗する運命にある」という Lecun の主張に反しており、Jim Fan の「データ駆動型世界モデル」のアイデアを支持していると信じています。
 写真
写真
過去にはさまざまな手法が失敗してきましたが、現在の成功は強化学習の父であるサットンの「苦い教訓」から来ているのかもしれません. 勢いよく奇跡を。
#人間が発見したものを封じ込めるのではなく、AI が同様の人間を発見できるようにする画期的な進歩は、最終的にはコンピューティングをスケールアップすることで達成されます #論文://m.sbmmt.com/link/a717f41c203cb970f96f706e4b12617b
GitHub://m.sbmmt.com/link/e43a09ffc30b44cb1f0db46f87836f40参考リンク:
[1]以上がAIビデオが再び爆発!写真+音声がビデオになり、アリババはヒロインのソラにLi Ziと一緒に歌ってラップするように頼みました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



