機械が人間の想像力を模倣できるようにするために、深い 生成モデル が大幅に進歩しました。これらのモデルは、現実的なサンプル、特に複数の領域で適切に機能する拡散モデルを作成できます。拡散モデルは、VAE の事後分布整列問題、GAN の不安定性、EBM の計算の複雑さ、NF のネットワーク制約問題など、他のモデルの制限を解決します。そのため、拡散モデルはコンピュータビジョンや自然言語処理などの面で大きな注目を集めています。 #拡散モデルは、順方向プロセスと逆方向プロセスの 2 つのプロセスで構成されます。順方向プロセスではデータが単純な事前分布に変換され、逆方向プロセスではこの変更が逆に行われ、訓練されたニューラル ネットワークを使用して微分方程式をシミュレートしてデータが生成されます。他のモデルと比較して、拡散モデルはより安定したトレーニング ターゲットとより良い生成結果を提供します。
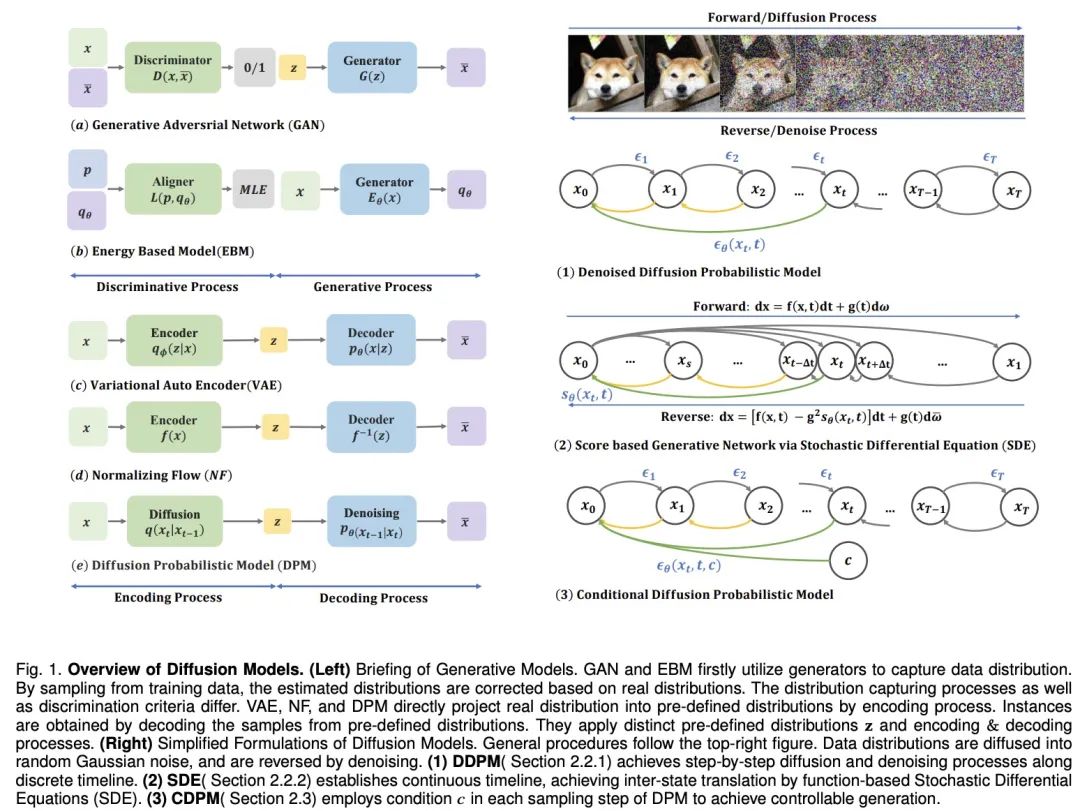
ただし、拡散モデルのサンプリングプロセスには推論と評価の繰り返しが伴います。このプロセスは、不安定性、高次元の計算要件、複雑な尤度の最適化などの課題に直面しています。研究者らは、この目的のために、ODE/SDE ソルバーの改善やサンプリングを高速化するためのモデル蒸留戦略の採用、安定性の向上と次元削減のための新しい前方プロセスなど、さまざまなソリューションを提案してきました。
最近、香港中国語文学、ウェストレイク大学、MIT、志江研究所は、IEEE TKDE に「生成拡散モデルに関する調査」というタイトルのレビュー論文を発表しました。拡散モデルの進歩については、サンプリングの高速化、プロセス設計、尤度の最適化、分布のブリッジングという 4 つの側面から説明します。このレビューでは、画像合成、ビデオ生成、3D モデリング、医療分析、テキスト生成などのさまざまなアプリケーション分野における拡散モデルの成功についても詳しく説明します。これらの応用事例を通じて、現実世界における普及モデルの実用性と可能性が実証されています。

- 論文アドレス: https://arxiv.org/pdf/2209.02646.pdf
- プロジェクト アドレス: https://github.com/chq1155/ A-Survey-on-Generative-Diffusion-Model?tab=readme-ov-file
拡散モデルの分野において、サンプリング速度を向上させるための重要なテクノロジーの 1 つは知識の蒸留です。このプロセスには、大規模で複雑なモデルから知識を抽出し、それをより小規模で効率的なモデルに転送することが含まれます。たとえば、知識の蒸留を使用すると、モデルのサンプリング軌跡を簡素化し、各ステップでより効率的にターゲット分布を近似することができます。 Salimans らはこれらの軌跡を最適化するために常微分方程式 (ODE) ベースのアプローチを採用し、他の研究者はノイズの多いサンプルからクリーンなデータを直接推定する技術を開発し、時点 T でのプロセスを高速化しました。
トレーニング方法を改善することも重要ですブースティングサンプリング 効率化の方法。一部の研究では、新しい拡散スキームの学習に焦点を当てています。このスキームでは、データに単純にガウス ノイズを加えるのではなく、より複雑な方法を通じて潜在空間にマッピングします。これらの方法の中には、エンコードの深さの調整など、逆デコード プロセスの最適化に焦点を当てているものもあれば、ノイズの追加が静的なものではなく、トレーニング プロセス中に変更できる変数になるように、新しいノイズ スケールの設計を検討しているものもあります。 .パラメータを学習しました。
#トレーニング不要のサンプリング
-
トレーニングに加えて新しいモデル 効率を向上させるために、事前にトレーニングされた拡散モデルのサンプリング プロセスを高速化するための専用のテクニックもいくつかあります。 ODE アクセラレーションは、ODE を使用して拡散プロセスを記述し、サンプリングをより速く進めることができる技術の 1 つです。たとえば、DDIM はサンプリングに ODE を利用する手法であり、その後の研究により、サンプリング速度をさらに向上させるために、PNDM や EDM などのより効率的な ODE ソルバーが導入されました。
他の生成モデルと組み合わせる
-
さらに、研究者らはサンプリングを高速化する分析手法を提案しており、これらの手法は、ノイズの多いデータから繰り返しを行わずにクリーンなデータを直接復元できる分析ソリューションを見つけようとしています。これらのメソッドには、Analytic-DPM とその改良版 Analytic-DPM が含まれており、高速で正確なサンプリング戦略を提供します。
ポテンシャルスペース
-
LSGM や INDM などの潜在空間拡散モデルは、VAE または正規化されたフロー モデルを組み合わせて、共有の重み付きノイズ除去フラクショナル マッチング損失および拡散モデルを通じてコーデックを最適化します。 ELBO または対数尤度の最適化は、学習とサンプル生成が容易な潜在空間を構築することを目的としています。たとえば、安定拡散では、まず VAE を使用して潜在空間を学習し、次にテキスト入力を受け入れるように拡散モデルをトレーニングします。 DVDP は、画像の摂動中にピクセル空間の直交成分を動的に調整します。
- 生成モデルの効率と強度を向上させるために、研究者は新しい前進プロセス設計を模索しています。ポアソン場生成モデルはデータを電荷として扱い、単純な分布を電力線に沿ったデータ分布に導き、従来の拡散モデルよりも強力なバックサンプリングを提供します。 PFGM は、この概念をさらに高次元の変数に取り入れます。 Dockhorn らの臨界減衰ランジュバン拡散モデルは、ハミルトン力学における速度変数を使用した条件付き速度分布の分数関数の学習を簡素化します。
- 離散内空間データ (テキスト、カテゴリデータなど) の拡散モデル、D3PM は離散空間の前方プロセスを定義します。この方法に基づいて、研究は言語テキストの生成、グラフのセグメント化、可逆圧縮にまで拡張されました。マルチモーダルな課題では、ベクトル量子化データがコードに変換され、優れた結果が得られます。ロボット工学やタンパク質モデリングなどのリーマン多様体の多様体データでは、拡散サンプリングをリーマン多様体に組み込む必要があります。 EDP-GNN や GraphGDP などのグラフ ニューラル ネットワークと拡散理論の組み合わせは、グラフ データを処理して順列不変性を捕捉します。
尤度の最適化
拡散モデルは ELBO を最適化しますが、尤度の最適化は依然として重要です。特に連続時間拡散モデルでは、この課題が顕著です。 ScoreFlow や変分拡散モデル (VDM) などのメソッドは、MLE トレーニングと DSM 目標の間の関係を確立し、そこではギルサノフの定理が重要な役割を果たします。改良されたノイズ除去拡散確率モデル (DDPM) は、変分下限と DSM を組み合わせたハイブリッド学習目標と、単純な再パラメータ化手法を提案します。ガウス分布を複素分布に変換する際の拡散モデルのパフォーマンス 優れた、ただし、任意のディストリビューションを接続する場合には課題があります。アルファハイブリッド手法は、混合と混合を繰り返して決定的なブリッジを作成します。修正フローでは、ブリッジ パスを修正するための追加の手順が追加されます。また、2つの分布間の接続をODEにより実現する方法もあり、中間接続点としてシュレディンガーブリッジやガウス分布を利用する方法も検討されている。 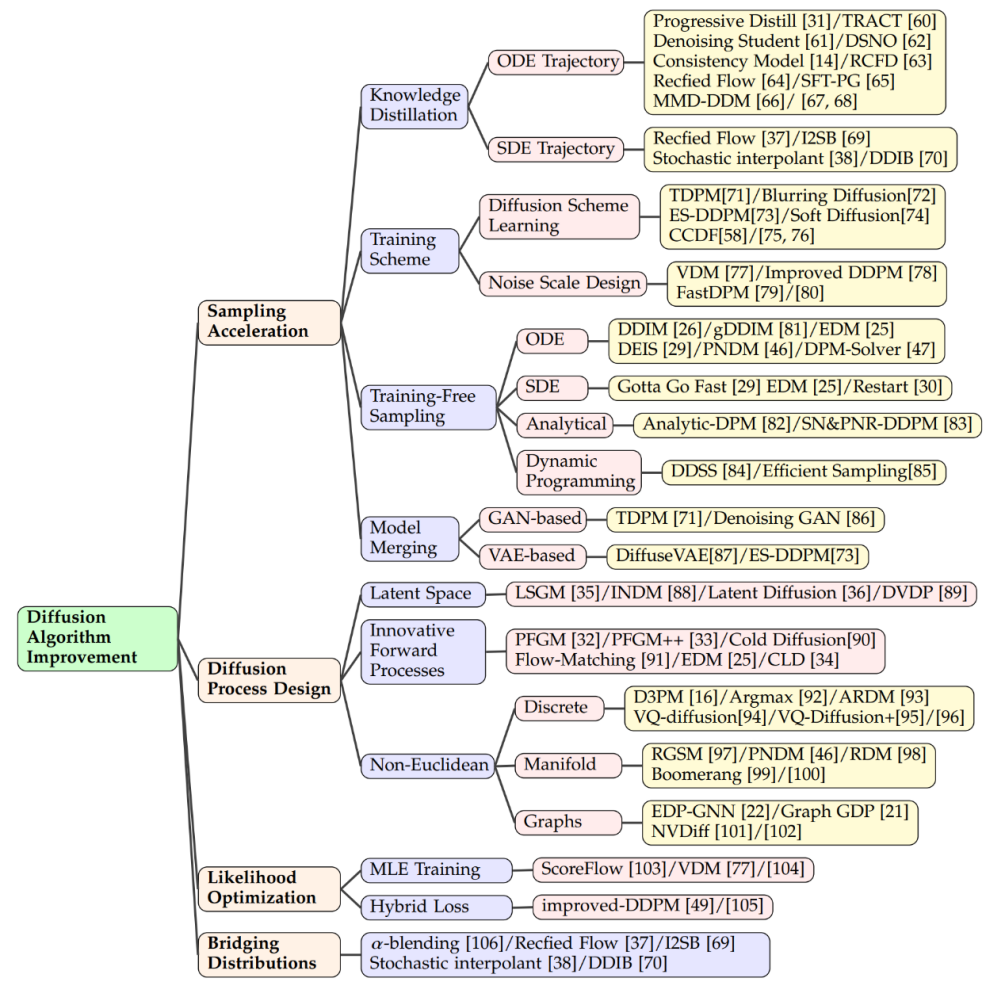
拡散このモデルは画像生成に非常に成功しており、通常の画像を生成するだけでなく、テキストを画像に変換するなどの複雑なタスクも実行できます。 Imagen、Stable Diffusion、DALL-E 2 などのモデルは、この点で優れたスキルを発揮します。彼らは拡散モデル構造をクロスアテンションレイヤー技術と組み合わせて使用し、テキスト情報を生成された画像に統合します。これらのモデルは、新しい画像を生成するだけでなく、再トレーニングを必要とせずに画像を編集できます。編集は、アテンション レイヤー (キー、値、アテンション マトリックス) 全体で調整することによって実現されます。たとえば、機能マップを調整して画像要素を変更したり、新しいテキスト埋め込みを導入したりして、新しい概念を追加します。画像が説明を正確に反映していることを確認するために、モデルがテキストを生成するときにテキストのすべてのキーワードに注意を払うようにするための研究が行われています。拡散モデルは、ソース画像、深度マップ、人間の骨格などの画像ベースの条件付き入力も、これらの機能をエンコードして統合して画像生成をガイドすることで処理できます。一部の研究では、ソース画像エンコード機能をモデルの開始層に追加して、画像間の編集を実現しています。これは、深度マップ、エッジ検出、またはスケルトンが条件として使用されるシーンにも適用できます。 3D 生成に関しては、拡散モデルによる主な方法が挙げられます。の2種類です。 1 つ目は、NeRF、点群、ボクセルなどのさまざまな 3D 表現に効果的に適用されている 3D データ上でモデルを直接トレーニングすることです。たとえば、研究者は 3D オブジェクトの点群を直接生成する方法を示しました。サンプリングの効率を向上させるために、いくつかの研究では、点群生成の追加条件としてハイブリッド点ボクセル表現、または画像合成を導入しています。一方で、拡散モデルを使用して 3D オブジェクトの NeRF 表現を処理し、遠近条件付き拡散モデルをトレーニングすることで新しいビューを合成し、NeRF 表現を最適化する研究もあります。 2 番目のアプローチは、2D 拡散モデルの事前知識を使用して 3D コンテンツを生成することに重点を置いています。たとえば、Dreamfusion プロジェクトでは、スコア蒸留サンプリング目標を使用して、事前トレーニングされたテキストから画像へのモデルから NeRF を抽出し、勾配降下最適化プロセスを通じて低損失のレンダリング画像を実現します。このプロセスは、生成を高速化するためにさらに拡張されました。 ビデオ拡散モデルは 2D 画像拡散の拡張です。時間的次元を追加することでビデオ シーケンスを生成します。このアプローチの基本的な考え方は、ビデオ フレーム間の連続性と依存関係をモデル化する方法として、既存の 2D 構造に時間レイヤーを追加することです。関連作品では、ビデオ拡散モデルを使用して、Make-A-Video、AnimatedDiff、その他のモデルなどの動的コンテンツを生成する方法を示しています。より具体的には、RaMViD モデルは 3D 畳み込みニューラル ネットワークを使用して画像拡散モデルをビデオに拡張し、一連のビデオ固有の条件付きテクニックを開発します。
##拡散モデルは、高品質のデータを取得するという問題の解決に役立ちます。医療分析、特に医療画像処理における一連の課題。これらのモデルは、強力な画像キャプチャ機能により、画像解像度、分類、ノイズ処理の向上に成功しています。たとえば、Score-MRI と Diff-MIC は高度な技術を使用して、MRI 画像の再構成を高速化し、より正確な分類を可能にします。 MCG は CT 画像の超解像度に多様体補正を採用し、再構成の速度と精度を向上させます。レア画像の生成に関しては、モデルは特定の技術を通じて異なるタイプの画像間で変換できます。たとえば、FNDM と DiffuseMorph は、それぞれ脳の異常検出と MR 画像の登録に使用されます。一部の新しい手法では、少数の高品質サンプルからトレーニング データセットを合成します。たとえば、31,740 個のサンプルを使用して 100,000 インスタンスのデータセットを合成し、非常に低い FID スコアを達成したモデルがあります。 テキスト生成テクノロジーは、人間と AI の間の重要な架け橋です。流暢で自然な言語を生成できる。自己回帰言語モデルは、強い一貫性を持つテキストを生成しますが、速度が遅くなります。一方、拡散モデルは、テキストを迅速に生成できますが、一貫性は比較的弱いです。主流となる 2 つの方法は、離散生成と潜在生成です。離散生成は高度な技術と事前トレーニングされたモデルに依存しています。たとえば、D3PM と Argmax は単語をカテゴリー ベクトルとして扱いますが、DifffusionBERT は拡散モデルと言語モデルを組み合わせてテキスト生成を改善します。潜在生成では、トークンの潜在空間にテキストが生成されます。たとえば、LM-Diffusion や GENIE などのモデルはさまざまなタスクで優れたパフォーマンスを発揮し、テキスト生成における拡散モデルの可能性を示しています。拡散モデルは、自然言語処理のパフォーマンスを向上させ、大規模な言語モデルと統合し、クロスモーダル生成を可能にすることが期待されています。
時系列データ モデリングは金融、気候変動で使用されます。科学、医療などの分野における予測・解析技術。拡散モデルは高品質のデータ サンプルを生成できるため、時系列データの生成に使用されてきました。この分野では、時系列データの時間依存性と周期性を考慮して拡散モデルが設計されることがよくあります。たとえば、CSDI (Conditional Sequence Diffusion Interpolation) は、双方向畳み込みニューラル ネットワーク構造を利用して時系列データ ポイントを生成または補間するモデルです。医療データ生成や環境データ生成に優れています。 DiffSTG や TimeGrad などの他のモデルは、時空間畳み込みネットワークを組み合わせることで、時系列の動的特性をより適切に捕捉し、より現実的な時系列サンプルを生成できます。これらのモデルは、自己調整ガイダンスを通じてガウス ノイズから意味のある時系列データを徐々に回復します。
オーディオ生成には、音声合成から音楽生成までのすべてが含まれます。シナリオ。通常、オーディオ データには複雑な時間構造と豊富なスペクトル情報が含まれているため、拡散モデルもこの分野での可能性を示しています。たとえば、WaveGrad と DiffSinger は、条件付き生成プロセスを利用して高品質のオーディオ波形を生成する 2 つの拡散モデルです。 WaveGrad は条件付き入力としてメル スペクトルを使用しますが、DiffSinger はこれにピッチやテンポなどの追加の音楽情報を追加して、より詳細なスタイルの制御を提供します。テキスト読み上げ (TTS) アプリケーションでは、Guided-TTS と Diff-TTS がテキスト エンコーダーと音響分類子の概念を組み合わせて、テキスト コンテンツに準拠し、特定のサウンド スタイルに従う音声を生成します。 Guide-TTS2 はさらに、明示的な分類子を使用せずに音声を生成する方法を示し、モデル自体によって学習された特徴を通じて音声生成をガイドします。
創薬、材料科学、ケミカルバイオロジーの分野、分子設計は、新しい化合物の発見と合成における重要なステップです。ここで拡散モデルは、化学空間を効率的に探索し、特定の特性を持つ分子を生成するための強力なツールとして機能します。無条件分子生成では、拡散モデルは事前の知識に依存せずに自発的に分子構造を生成します。クロスモーダル生成では、モデルに薬効や標的タンパク質の結合傾向などの特定の機能条件を組み込んで、目的の特性を持つ分子を生成できます。配列ベースの方法では、分子の生成をガイドするためにタンパク質の配列を考慮する場合がありますが、構造ベースの方法ではタンパク質の三次元構造情報を使用する場合があります。このような構造情報は、分子ドッキングや抗体設計における事前知識として使用できるため、生成される分子の品質が向上します。
#グラフ生成
理解とシミュレーションの向上を目的とした拡散モデルを使用してグラフを生成します。現実世界のネットワーク構造と伝播プロセス。このアプローチは、研究者が複雑なシステムのパターンと相互作用を掘り起こし、起こり得る結果を予測するのに役立ちます。アプリケーションには、ソーシャル ネットワーク、生物学的ネットワーク分析、グラフ データセットの作成などが含まれます。従来の方法は隣接行列またはノード特徴の生成に依存していますが、これらの方法はスケーラビリティが低く、実用性が限られています。したがって、最新のグラフ生成技術では、特定の条件に基づいてグラフを生成することが好まれています。たとえば、PCFI モデルはグラフの機能の一部と最短経路予測を使用して生成プロセスをガイドし、EDGE と DiffFormer はノード次数とエネルギー制約を使用してそれぞれ生成を最適化し、D4Explainer は分布と反事実損失を組み合わせることによってグラフのさまざまな可能性を探ります。これらの方法により、グラフ生成の精度と実用性が向上します。 推論速度が遅いことに加えて、拡散モデルは低品質のデータからパターンや規則性を特定する際に困難に直面することが多く、その結果、新しいシナリオやデータセットに一般化できなくなります。さらに、大規模なデータセットを扱う場合には、トレーニング時間の延長、過剰なメモリ使用、または望ましい状態への収束不能などの計算上の課題が生じ、それによってモデルのサイズと複雑さが制限されます。さらに、データのサンプリングに偏りや不均一があると、さまざまなドメインや母集団に適応できる出力を生成するモデルの能力が制限される可能性があります。 モデルの理解を向上させ、特定の分布を生成する機能限られたデータでより適切な一般化を達成するには、サンプル内に含めることが重要です。データ内のパターンと相関関係の特定に重点を置くことで、モデルはトレーニング データに厳密に一致し、特定の要件を満たすサンプルを生成できます。これには、効率的なデータのサンプリング、利用技術、モデルのパラメーターと構造の最適化が必要です。最終的に、この強化された理解により、より制御された正確な生成が可能になり、それによって汎化パフォーマンスが向上します。 大規模言語モデルを使用した高度なマルチモーダル生成拡散モデルの将来 開発の方向性これには、大規模言語モデル (LLM) を統合することによるマルチモーダル生成の進歩が含まれます。この統合により、モデルはテキスト、画像、その他のモダリティの組み合わせを含む出力を生成できるようになります。 LLM を組み込むことにより、さまざまなモダリティ間の相互作用に対するモデルの理解が強化され、生成される出力はより多様で現実的になります。さらに、LLM は、テキストと他のモダリティ間の接続を効果的に活用することで、プロンプトベースの生成効率を大幅に向上させます。さらに、LLM は触媒として拡散モデルの生成能力を向上させ、モードを生成できる分野の範囲を拡大します。 #機械学習分野との統合
拡散モデルと従来のマシンの統合理論を組み合わせることで、さまざまなタスクのパフォーマンスを向上させる新たな機会が得られます。半教師あり学習は、一般化問題などの拡散モデルに固有の課題に対処し、データが限られている場合に効率的な条件付き生成を可能にする場合に特に価値があります。ラベルのないデータを活用することで、拡散モデルの汎化機能が強化され、特定の条件下でサンプルを生成する際に理想的なパフォーマンスが実現されます。
さらに、強化学習は、微調整アルゴリズムを使用してモデルのサンプリング プロセス中に的を絞ったガイダンスを提供することにより、重要な役割を果たします。このガイダンスにより、集中的な探査が保証され、制御された生成が促進されます。さらに、追加のフィードバックを統合することで強化学習が強化され、制御可能な状態を生成するモデルの能力が向上します。 アルゴリズム改善手法(付録)
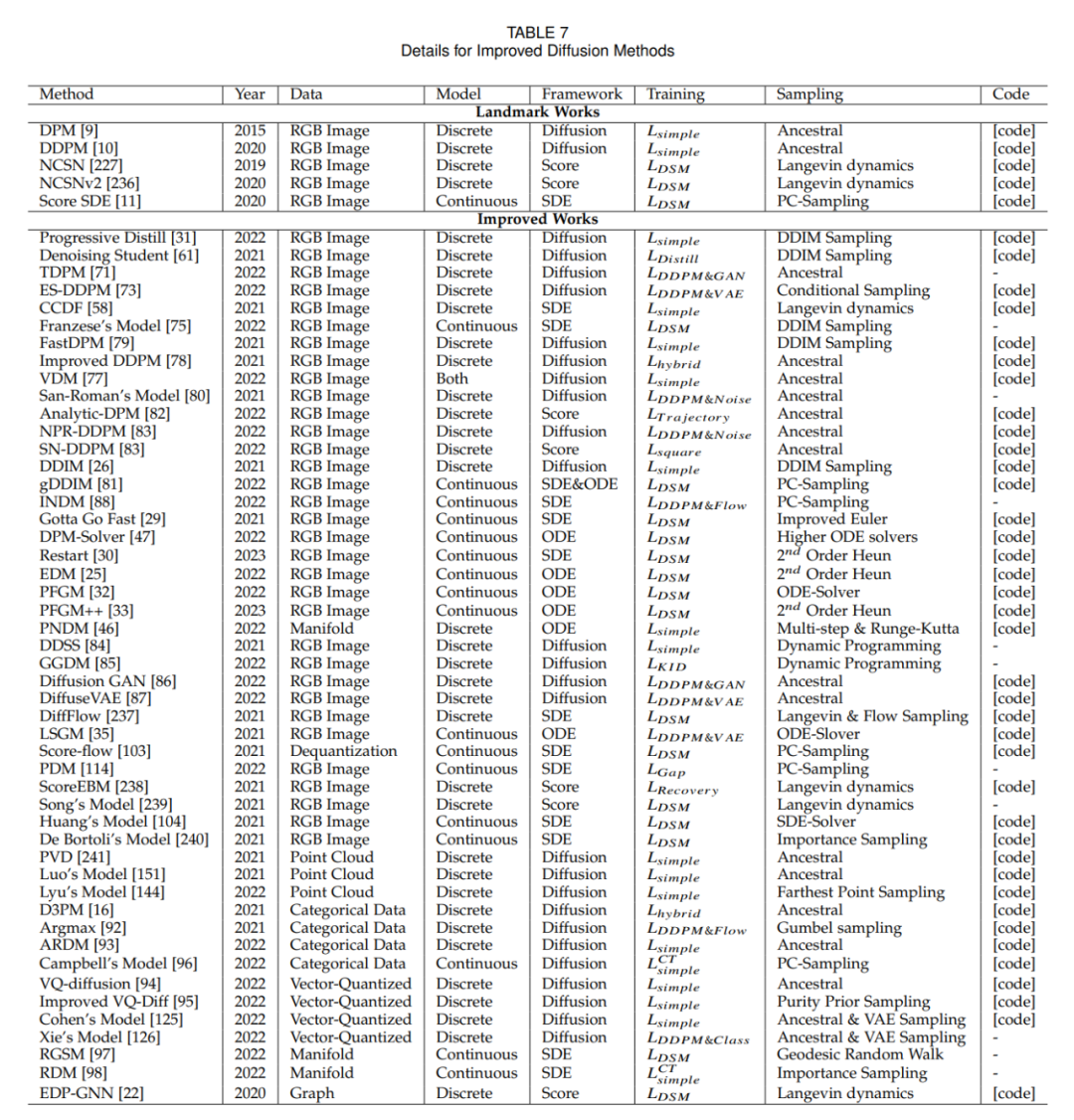
フィールド適用手法(付録) )
以上がSora 爆発のテクノロジー、普及モデルの最新開発方向をまとめた記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



