


Sora が登場するとすぐにトップトレンドとなり、話題の人気は高まるばかりでした。
リアルなビデオを生成する強力な機能により、多くの人々が「現実はもはや存在しない」と叫ばせています。
OpenAI 技術レポートでも、Sora は動いている物理世界を深く理解でき、真の「世界モデル」と呼ぶことができることが明らかになりました。

そして、研究の焦点として常に「世界モデル」に焦点を当ててきたチューリングの巨人ルカン氏も、この議論に参加しています。
その理由は、数日前の WGS サミットで LeCun 氏が表明した「AI ビデオに関しては、何をすべきかわからない」という意見をネチズンが掘り起こしたためです。
彼は、テキスト プロンプトのみに基づいてリアルなビデオを生成することは、物理世界を理解するモデルと同等ではないと考えています。ビデオを生成するアプローチは、因果関係の予測に基づいた世界のモデルとは大きく異なります。

次に、LeCun 氏はさらに詳しく説明しました。
ビデオの種類は想像できますが、多数ありますが、ビデオ生成システムが適切なサンプルを「1 つ」作成するだけで成功します。
実際のビデオの場合、適切なフォローアップ開発パスは比較的少なく、特に特定のアクション条件下では、これらの可能性の代表的な部分を生成することは困難です。
さらに、これらのビデオのフォローアップ コンテンツの生成はコストがかかるだけでなく、事実上無意味です。
より理想的なアプローチは、後続のコンテンツの「抽象表現」を生成し、実行するアクションに無関係なシーンの詳細を削除することです。
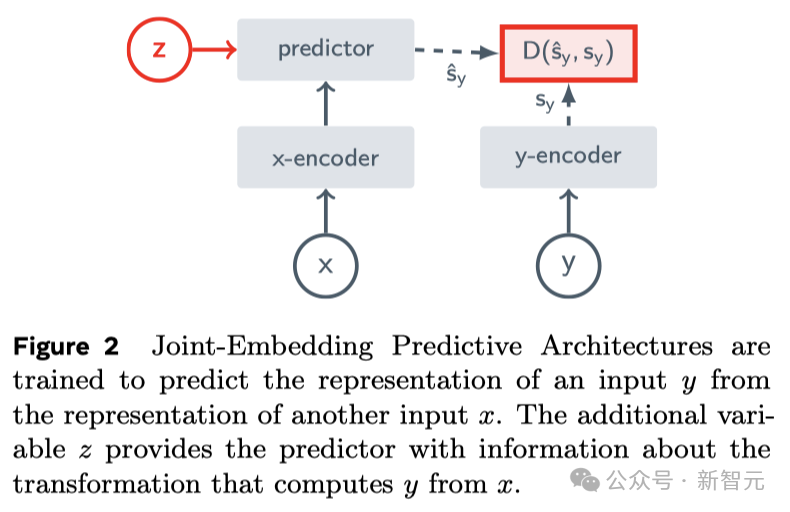
これは JEPA (Joint Embedding Prediction Architecture) の核となるアイデアであり、生成的ではなく、表現空間で予測します。
次に、彼は VICReg、I-JEPA、V-JEPA に関する自身の研究と他の研究者らの研究を使用して、次のことを証明しました。再構築されたピクセル 変分 AE、マスク AE、ノイズ除去 AE などの生成アーキテクチャと比較して、「ジョイント埋め込みアーキテクチャ」はより優れた視覚入力 Express を生成できます。
学習した表現を下流タスクの教師付きヘッドへの入力として使用する場合 (バックボーンを微調整せずに)、ジョイント埋め込みアーキテクチャは生成アーキテクチャよりも優れたパフォーマンスを発揮します。
Sora モデルがリリースされた日に、Meta は新しい教師なしの「ビデオ予測モデル」である V-JEPA を立ち上げました。
LeCun が 2022 年に初めて JEPA について言及して以来、I-JEPA と V-JEPA はそれぞれ画像とビデオに基づいた強力な予測機能を備えています。
「人間の理解方法」で世界を観察し、抽象的かつ効率的な予測を通じてオクルージョンされた部分を生成できると主張しています。
論文アドレス: https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual- presentations-from-video/
V-JEPA は、以下のビデオのアクションを見ると「紙を半分に引き裂いてください」と言います。
#別の例として、ノートブックで視聴されているビデオの一部がブロックされている場合、V-JEPA はそのコンテンツについてさまざまな予測を行うことができます。ノート。 
これは、V-JEPA が 200 万本の動画を視聴した後に獲得したスーパーパワーであることは言及する価値があります。 
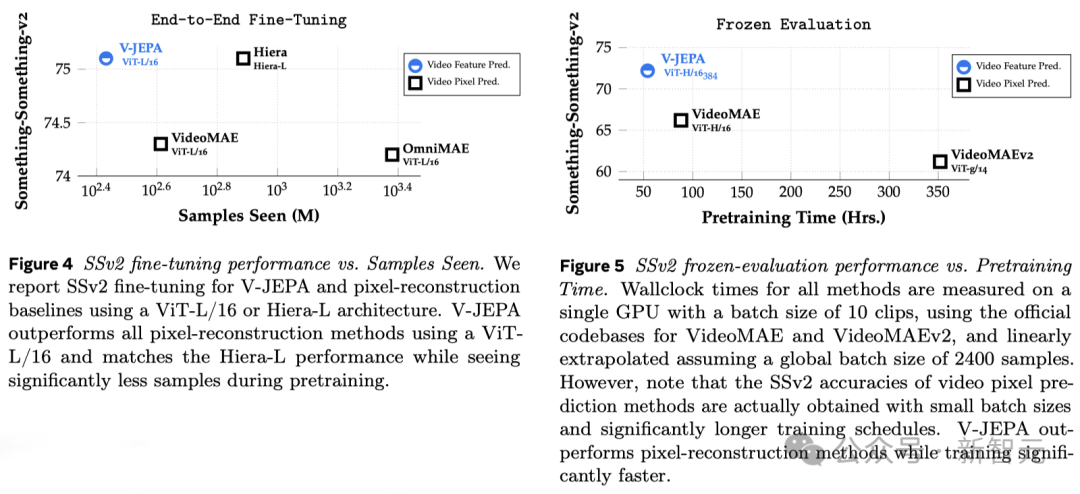
実験結果は、ビデオ特徴予測学習を通じてのみ、動作と見た目の判断に基づいてさまざまなタスクに広く適用できる「効率的な視覚表現」を取得できることを示しています。モデルを変更するには パラメータを調整します。
V-JEPA トレーニングに基づく ViT-H/16 は、Kinetics-400、SSv2、および ImageNet1K ベンチマークでそれぞれ 81.9%、72.2%、77.9% という高いスコアを達成しました。
人類が懸念しているのは周囲の世界 世界の理解は、特に人生の初期においては主に「観察」によって得られます。
ニュートンの「運動の第 3 法則」を例に挙げると、赤ちゃんや猫でも、何度もテーブルから物を押してその結果を観察すると、自然に物を動かすことができます。高いところはいつか落ちる。
この種の理解には、長期にわたる指導や大量の本を読む必要はありません。
ご覧のとおり、内なる世界モデル (心の世界理解に基づく状況理解) は、これらの結果を予測することができ、非常に効果的です。
Yann LeCun 氏は、V-JEPA は世界をより深く理解するための重要なステップであり、機械がより広範に推論して計画できるようにすることを目指していると述べました。

2022 年に、彼は初めて Joint Embedding Prediction Architecture (JEPA) を提案しました。
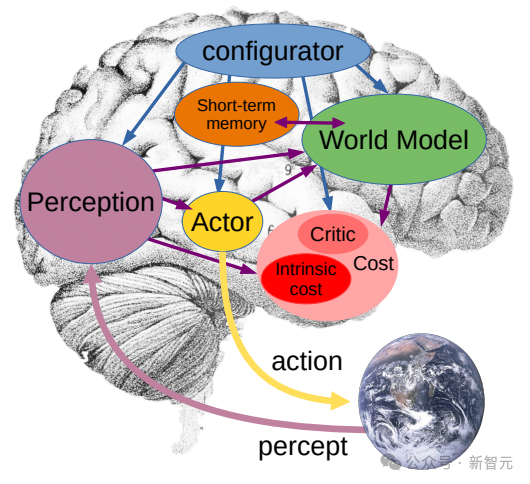
私たちの目標は、人間と同じように学習できる高度なマシン インテリジェンス (AMI) を構築し、周囲の世界の固有モデルを構築することで効率的に学習、適応、計画を立てることです。複雑なタスクを解決するために。

と生成 AI モデル Sora Completely異なりますが、V-JEPA は「非生成モデル」です。
抽象的な空間表現でビデオの隠れた部分や欠落している部分を予測することで学習します。
これは、「ピクセル」を直接比較するのではなく、画像の抽象表現を比較することによって学習する画像結合埋め込み予測アーキテクチャ (I-JEPA) に似ています。
欠落しているすべてのピクセルを再構築しようとする生成手法とは異なり、V-JEPA は予測が難しい情報を破棄することができます。このアプローチにより、トレーニング効率とサンプル効率が 1.5 倍に達します。-6x改善。
V-JEPA は自己教師あり学習手法を採用し、事前トレーニングではラベルのないデータに完全に依存します。
事前トレーニングだけを行った後は、データにラベルを付けることで、特定のタスクに合わせてモデルを微調整できます。
結果として、このアーキテクチャは、必要なラベル付きサンプルの数とラベルなしデータからの学習への投資の両方の点で、以前のモデルよりも効率的です。
V-JEPA を使用する場合、研究者はビデオの大部分をブロックし、「コンテキスト」のごく一部のみを表示しました。
次に、予測子は、欠落しているコンテンツを、特定のピクセルではなく、表現空間を埋めるより抽象的な説明で埋めるように求められます。
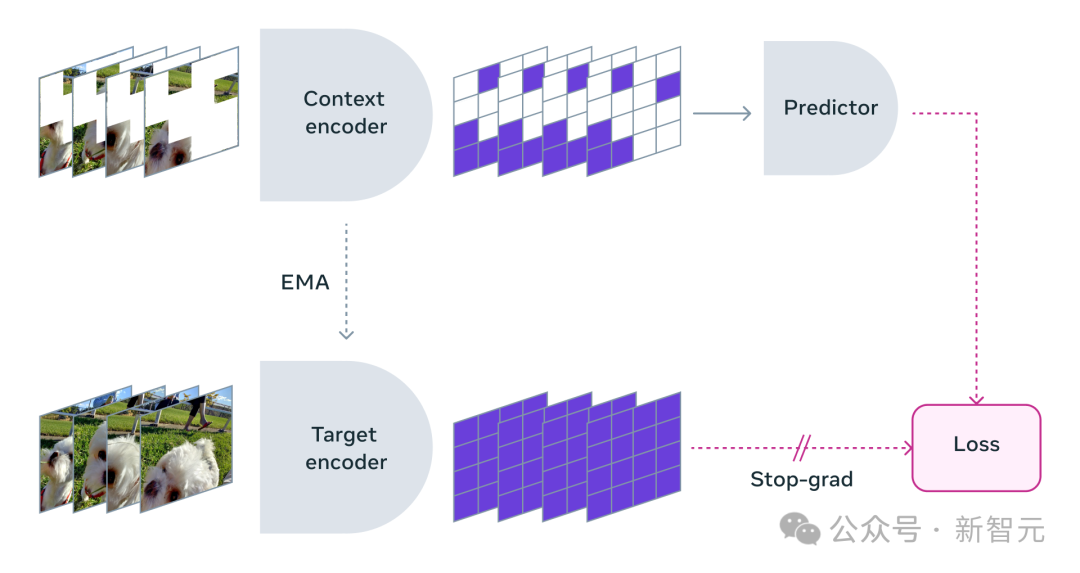
マスクメソッド
代わりに、さまざまなビデオで自己教師あり学習を適用することで、世界がどのように機能するかについて多くのことを学びました。
メタ研究者はマスキング戦略も慎重に設計しました:
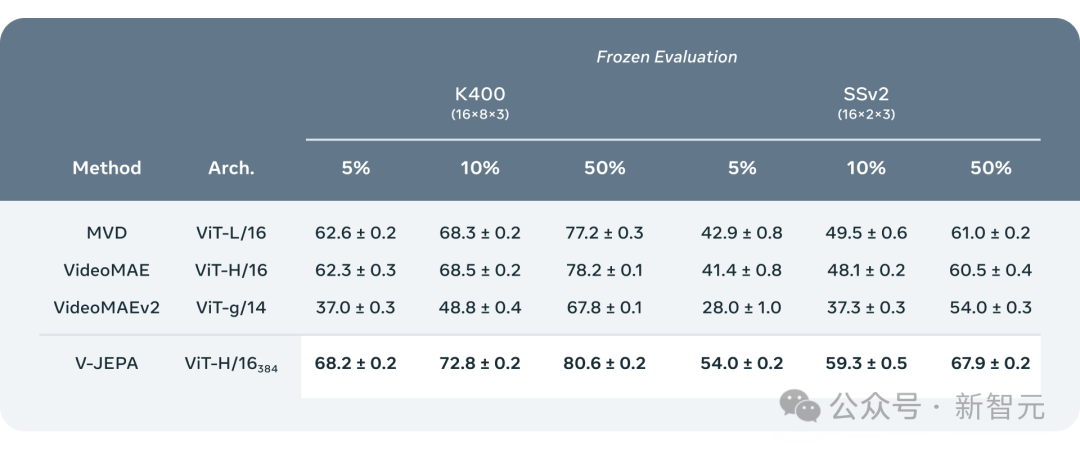
如果不遮蔽影片的大部分區域,而只是隨機選取一些小片段,這會讓學習任務變得過於簡單,導致模型無法學習到關於世界的複雜資訊。 同樣,需要注意的是,大多數影片中,事物隨著時間的推移而逐漸演變。 如果只在短時間內遮罩影片的一小部分,讓模型能看到前後發生的事,同樣會降低學習難度,讓模型難以學到有趣的內容。 因此,研究人員採取了同時在空間和時間上遮罩視訊部分區域的方法,迫使模型學習並理解場景。 在抽象的表示空間中進行預測非常關鍵,因為它讓模型專注於視訊內容的高層概念,而不必擔心通常對完成任務無關緊要的細節。 畢竟,如果一段影片展示了一棵樹,你可能不會關心每一片樹葉的微小運動。 而真正讓Meta研究人員興奮的是,V-JEPA是第一個在「凍結評估」上表現出色的影片模型。 凍結,是指在編碼器和預測器上完成所有自監督預訓練後,就不再對其進行修改。 當我們需要模型學習新技能時,只需在其上添加一個小型的、專門的層或網絡,這種方式既高效又快速。 過去的研究還需要進行全面的微調,即在預訓練模型後,為了讓模型在細粒度動作辨識等任務上表現出色,需要微調模型的所有參數或權重。 直白講,微調後的模型只能專注於某個任務,而無法適應其他任務。 如果想讓模型學習不同的任務,就必須更換數據,並對整個模型進行專門化調整。 V-JEPA的研究表明,就可以一次預訓練模型,不依賴任何標記數據,然後將模型用於多個不同的任務,如動作分類、細粒度物體互動辨識和活動定位,開啟了全新的可能。 - 少樣本凍結評估 ##研究人員將V-JEPA與其他視訊處理模型進行了對比,特別關注在資料標註較少的情況下的表現。 它們選取了Kinetics-400和Something-Something-v2兩個資料集,透過調整用於訓練的標註樣本比例(分別為5%,10%和50%) ,觀察模型在處理影片時的效能。 為了確保結果的可靠性,在每種比例下進行了3次獨立的測試,併計算出了平均值和標準差。 結果顯示,V-JEPA在標註使用效率上優於其他模型,尤其是當每個類別可用的標註樣本減少時,V-JEPA與其他模型之間的效能差距更加明顯。 雖然V-JEPA的「V」代表視頻,但迄今為止,它主要集中於分析視頻的“視覺元素”。 顯然,Meta下一步是研究方向是,推出能同時處理影片中的「視覺和音訊訊息」的多模態方法。 作為驗證概念的模型,V-JEPA在識別影片中細微的物件互動方面表現出色。 例如,能夠區分某人是在放下筆、拿起筆,還是假裝放下筆但實際上沒有放下。 不過,這種高水準的動作辨識對於短影片片段(幾秒到10秒鐘)效果很好。 因此,下一步研究另一個重點是,如何讓模型在更長的時間跨度上進行規劃和預測。 到目前為止,Meta研究人員使用V-JEPA主要關注的是「感知」— —透過分析視訊串流來理解周圍世界的即時情況。 在這個聯合嵌入預測架構中,預測器充當了一個初步的「物理世界模型」,能夠概括性地告訴我們影片中正在發生的事情。 Meta的下一步目標是展示,如何利用這種預測器或世界模型來進行規劃和連續決策。 我們已經知道,JEPA模型可以透過觀察影片來進行訓練,就像嬰兒觀察世界一樣,無需強有力的監督就能學習很多。 透過這種方式,僅用少量標註數據,模型就能快速學習新任務和辨識不同的動作。 從長遠來看,在未來應用中,V-JEPA強大情境理解力,對開發具身AI技術以及未來擴增實境(AR)眼鏡有著重大意義。 現在想想,如果蘋果Vision Pro能夠得到「世界模型」的加持,更加無敵了。 顯然,LeCun對生成式AI並不看好。 「聽聽一個一直在試圖訓練用於演示和規劃的「世界模型」過來人的建議」。 Perplexity AI的執行長表示: Sora雖然令人驚嘆,但還沒有準備好對物理學進行準確的建模。而Sora的作者非常機智,在部落格的技術報告部分提到了這一點,例如打碎的玻璃無法很好地建模。 很明顯短期內,基於這樣複雜的世界模擬的推理,是無法在家用機器人上立即運行的。 事實上,許多人未能理解的一個非常重要的細微差別是: 在文字或影片中產生看似有趣的內容並不意味著(也不需要)它「理解」自己產生的內容。一個能夠基於理解進行推理的智能體模型必須,絕對是在大模型或擴散模型之外。 但也有網友表示,「這不是人類學習的方式」。 「我們對以往經歷的只記得一些獨特的,丟掉了所有的細節。我們還可以隨時隨地為環境建模(創建表示法),因為我們感知到了它。智能最重要的部分是泛化」。 還有人稱,它仍然是插值潛在空間的嵌入,到目前為止你還不能以這種方式建構「世界模型」。 Sora,以及V-JEPA真的能夠理解世界嗎?你怎麼看? 高效預測,無需微調


未來研究新方向:視覺音訊同預測
「世界模型」又進一步
網友討論




以上がルカンはソラが物理世界を理解できないと怒って非難した!メタ初のAI動画「ワールドモデル」 V-JEPAの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



