


Linux でデバイスのドライバーを作成する方法を考えたことはありますか? Linux でドライバーがメモリ リソースを効率的に使用する方法を考えたことはありますか? Linux システムで、メモリ マッピング、メモリ割り当て、メモリ保護などの高度な機能をドライバで実装できるようにする方法を考えたことはありますか?これらの問題に興味がある場合、この記事では、これらの目標を達成するための効果的な方法である Linux デバイス ドライバーのメモリ管理を紹介します。メモリ管理は、メモリ リソースの記述と制御に使用されるデータ構造とアルゴリズムであり、メモリ情報と属性をシンプルかつ統一された方法でカーネルに転送し、メモリの割り当てと解放を行うことができます。メモリ管理も有効活用のための仕組みであり、メモリのさまざまな操作やコマンドを標準的かつ汎用的に定義して利用することで、メモリのマッピング、コピー、保護などの機能を実現します。メモリ管理は高度な機能を実装するためのフレームワークでもあり、さまざまなメモリインターフェイスやプロトコルを柔軟かつ拡張的に定義して使用することで、メモリの共有、ロック、バッファリングなどの機能を実現します。この記事では、メモリ管理の基本概念、文法規則、記述方法、呼び出しプロセス、操作方法などから、Linux デバイス ドライバにおけるメモリ管理の用途と役割を詳しく紹介し、便利で使いやすいメモリ管理を習得するのに役立ちます。強力な方法です。
MMU を含むプロセッサの場合、Linux システムは複雑なストレージ管理システムを提供し、プロセスがアクセスできるメモリが 4GB に達することを可能にします。プロセスの 4GB メモリ空間は、ユーザー空間とカーネル空間の 2 つの部分に分割されます。ユーザー空間のアドレスは一般的に 0 ~ 3GB (つまり PAGE_OFFSET) に分散されており、残りの 3 ~ 4GB はカーネル空間になります。
カーネル空間のアプリケーション メモリに関連する関数には、主に kmalloc()、__get_free_pages()、vmalloc() などが含まれます。
メモリ マッピングを通じて、ユーザー プロセスはユーザー空間内のデバイスに直接アクセスできます。
各プロセスのユーザー空間は完全に独立しており、互いに無関係であり、各ユーザープロセスは異なるページテーブルを持ちます。カーネル空間はカーネルによってマッピングされ、プロセスによって変化することはなく、固定されています。カーネル空間アドレスには対応する独自のページ テーブルがあり、カーネルの仮想空間は他のプログラムから独立しています。ユーザー プロセスは、システム コール (ユーザー プロセスに代わってカーネル モードで実行) を通じてのみカーネル空間にアクセスできます。
Linux の 1GB カーネル アドレス空間は、図に示すように、物理メモリ マッピング領域、仮想メモリ割り当て領域、ハイエンド ページ マッピング領域、専用ページ マッピング領域、およびシステム予約マッピング領域に分割されます。 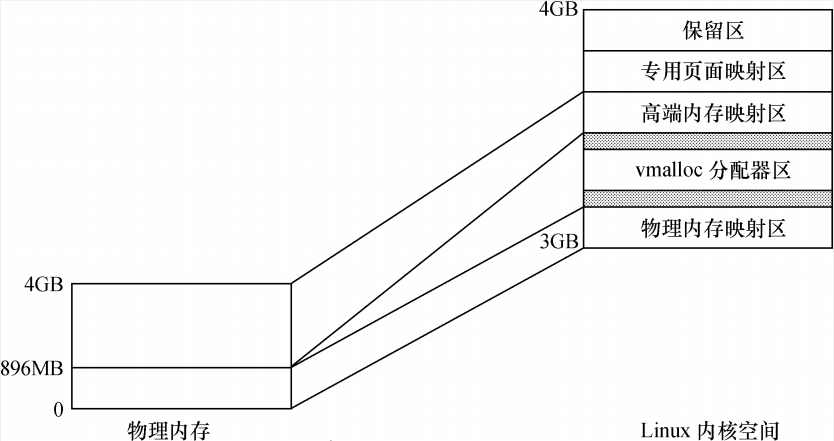
予約エリア
リーリー特別ページマッピング領域
リーリーハイエンド メモリ マッピング領域
リーリー仮想メモリ割り当て領域
リーリー物理メモリマッピング領域
リーリーカーネルの仮想メモリ物理メモリ マッピング領域の場合、virt_to_phys() を使用してカーネル仮想アドレスを物理アドレスに変換できます。virt_to_phys() の実装はアーキテクチャに関連しています。 ARM、virt_to_phys () の定義は次のとおりです。
static inline unsigned long virt_to_phys(void *x)
{
return __virt_to_phys((unsigned long)(x));
}
/* PAGE_OFFSET 通常为 3GB,而 PHYS_OFFSET 则定于为系统 DRAM 内存的基地址 */
#define __virt_to_phys(x) ((x) - PAGE_OFFSET + PHYS_OFFSET)
在 Linux 内核空间申请内存涉及的函数主要包括 kmalloc()、__get_free_pages()和 vmalloc()等。kmalloc()和__get_free_pages()( 及其类似函数) 申请的内存位于物理内存映射区域,而且在物理上也是连续的,它们与真实的物理地址只有一个固定的偏移,因此存在较简单的转换关系。而vmalloc()在虚拟内存空间给出一块连续的内存区,实质上,这片连续的虚拟内存在物理内存中并不一定连续,而 vmalloc()申请的虚拟内存和物理内存之间也没有简单的换算关系。
void *kmalloc(size_t size, int flags);
给 kmalloc()的第一个参数是要分配的块的大小,第二个参数为分配标志,用于控制 kmalloc()的行为。
flags
使用 kmalloc()申请的内存应使用 kfree()释放,这个函数的用法和用户空间的 free()类似。
__get_free_pages()系列函数/宏是 Linux 内核本质上最底层的用于获取空闲内存的方法,因为底层的伙伴算法以 page 的 2 的 n 次幂为单位管理空闲内存,所以最底层的内存申请总是以页为单位的。
__get_free_pages()系列函数/宏包括 get_zeroed_page()、 __get_free_page()和__get_free_pages()。
/* 该函数返回一个指向新页的指针并且将该页清零 */ get_zeroed_page(unsigned int flags); /* 该宏返回一个指向新页的指针但是该页不清零 */ __get_free_page(unsigned int flags); /* 该函数可分配多个页并返回分配内存的首地址,分配的页数为 2^order,分配的页也 不清零 */ __get_free_pages(unsigned int flags, unsigned int order); /* 释放 */ void free_page(unsigned long addr); void free_pages(unsigned long addr, unsigned long order);
__get_free_pages 等函数在使用时,其申请标志的值与 kmalloc()完全一样,各标志的含义也与kmalloc()完全一致,最常用的是 GFP_KERNEL 和 GFP_ATOMIC。
vmalloc()一般用在为只存在于软件中(没有对应的硬件意义)的较大的顺序缓冲区分配内存,vmalloc()远大于__get_free_pages()的开销,为了完成 vmalloc(),新的页表需要被建立。因此,只是调用 vmalloc()来分配少量的内存(如 1 页)是不妥的。
vmalloc()申请的内存应使用 vfree()释放, vmalloc()和 vfree()的函数原型如下:
void *vmalloc(unsigned long size); void vfree(void * addr);
vmalloc()不能用在原子上下文中,因为它的内部实现使用了标志为 GFP_KERNEL 的 kmalloc()。
一方面,完全使用页为单元申请和释放内存容易导致浪费(如果要申请少量字节也需要 1 页);另一方面,在操作系统的运作过程中,经常会涉及大量对象的重复生成、使用和释放内存问题。在Linux 系统中所用到的对象,比较典型的例子是 inode、 task_struct 等。如果我们能够用合适的方法使得在对象前后两次被使用时分配在同一块内存或同一类内存空间且保留了基本的数据结构,就可以大大提高效率。 内核的确实现了这种类型的内存池,通常称为后备高速缓存(lookaside cache)。内核对高速缓存的管理称为slab分配器。实际上 kmalloc()即是使用 slab 机制实现的。
注意, slab 不是要代替__get_free_pages(),其在最底层仍然依赖于__get_free_pages(), slab在底层每次申请 1 页或多页,之后再分隔这些页为更小的单元进行管理,从而节省了内存,也提高了 slab 缓冲对象的访问效率。
#include /* 创建一个新的高速缓存对象,其中可容纳任意数目大小相同的内存区域 */ struct kmem_cache *kmem_cache_create(const char *name, /* 一般为将要高速缓 存的结构类型的名字 */ size_t size, /* 每个内存区域的大小 */ size_t offset, /* 第一个对象的偏移量,一般为0 */ unsigned long flags, /* 一个位掩码: SLAB_NO_REAP 即使内存紧缩也不自动收缩这块缓 存,不建议使用 SLAB_HWCACHE_ALIGN 每个数据对象被对齐到一个 缓存行 SLAB_CACHE_DMA 要求数据对象在DMA内存区分配 */ /* 可选参数,用于初始化新分配的对象,多用于一组对象的内存分配时使 用 */ void (*constructor)(void*, struct kmem_cache *, unsigned long), void (*destructor)(void*, struct kmem_cache *, unsigned long) ); /* 在 kmem_cache_create()创建的 slab 后备缓冲中分配一块并返回首地址指针 */ void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags); /* 释放 slab 缓存 */ void kmem_cache_free(struct kmem_cache *cachep, void *objp); /* 收回 slab 缓存,如果失败则说明内存泄漏 */ int kmem_cache_destroy(struct kmem_cache *cachep);
Tip: 高速缓存的使用统计情况可以从/proc/slabinfo获得。
内核中有些地方的内存分配是不允许失败的,内核开发者建立了一种称为内存池的抽象。内存池其实就是某种形式的高速后备缓存,它试图始终保持空闲的内存以便在紧急状态下使用。mempool很容易浪费大量内存,应尽量避免使用。
#include /* 创建 */ mempool_t *mempool_create(int min_nr, /* 需要预分配对象的数目 */ mempool_alloc_t *alloc_fn, /* 分配函数,一般直接使用内核提供的 mempool_alloc_slab */ mempool_free_t *free_fn, /* 释放函数,一般直接使用内核提供的 mempool_free_slab */ void *pool_data); /* 传给alloc_fn/free_fn的参数,一般为 kmem_cache_create创建的cache */ /* 分配释放 */ void *mempool_alloc(mempool_t *pool, int gfp_mask); void mempool_free(void *element, mempool_t *pool); /* 回收 */ void mempool_destroy(mempool_t *pool);
一般情况下,用户空间是不可能也不应该直接访问设备的,但是,设备驱动程序中可实现mmap()函数,这个函数可使得用户空间直能接访问设备的物理地址。
这种能力对于显示适配器一类的设备非常有意义,如果用户空间可直接通过内存映射访问显存的话,屏幕帧的各点的像素将不再需要一个从用户空间到内核空间的复制的过程。
从 file_operations 文件操作结构体可以看出,驱动中 mmap()函数的原型如下:
int(*mmap)(struct file *, struct vm_area_struct*);
驱动程序中 mmap()的实现机制是建立页表,并填充 VMA 结构体中 vm_operations_struct 指针。VMA 即 vm_area_struct,用于描述一个虚拟内存区域:
struct vm_area_struct {
unsigned long vm_start; /* 开始虚拟地址 */
unsigned long vm_end; /* 结束虚拟地址 */
unsigned long vm_flags; /* VM_IO 设置一个内存映射I/O区域;
VM_RESERVED 告诉内存管理系统不要将VMA交换出去
*/
struct vm_operations_struct *vm_ops; /* 操作 VMA 的函数集指针 */
unsigned long vm_pgoff; /* 偏移(页帧号) */
void *vm_private_data;
...
}
struct vm_operations_struct {
void(*open)(struct vm_area_struct *area); /*打开 VMA 的函数*/
void(*close)(struct vm_area_struct *area); /*关闭 VMA 的函数*/
struct page *(*nopage)(struct vm_area_struct *area, unsigned
long address, int *type); /*访问的页不在内存时调用*/
/* 当用户访问页前,该函数允许内核将这些页预先装入内存。
驱动程序一般不必实现 */
int(*populate)(struct vm_area_struct *area, unsigned long address, unsigned
long len, pgprot_t prot, unsigned long pgoff, int nonblock);
...
建立页表的方法有两种:使用remap_pfn_range函数一次全部建立或者通过nopage VMA方法每次建立一个页表。
remap_pfn_range
remap_pfn_range负责为一段物理地址建立新的页表,原型如下:
int remap_pfn_range(struct vm_area_struct *vma, /* 虚拟内存区域,一定范围的页 将被映射到该区域 */ unsigned long addr, /* 重新映射时的起始用户虚拟地址。该函数为处于addr 和addr+size之间的虚拟地址建立页表 */ unsigned long pfn, /* 与物理内存对应的页帧号,实际上就是物理地址右 移 PAGE_SHIFT 位 */ unsigned long size, /* 被重新映射的区域大小,以字节为单位 */ pgprot_t prot); /* 新页所要求的保护属性 */
demo:
static int xxx_mmap(struct file *filp, struct vm_area_struct *vma)
{
if (remap_pfn_range(vma, vma->vm_start, vm->vm_pgoff, vma->vm_end - vma-
>vm_start, vma->vm_page_prot)) /* 建立页表 */
return - EAGAIN;
vma->vm_ops = &xxx_remap_vm_ops;
xxx_vma_open(vma);
return 0;
}
/* VMA 打开函数 */
void xxx_vma_open(struct vm_area_struct *vma)
{
...
printk(KERN_NOTICE "xxx VMA open, virt %lx, phys %lx\n", vma-
>vm_start, vma->vm_pgoff "xxx VMA close.\n");
}
static struct vm_operations_struct xxx_remap_vm_ops = { /* VMA 操作结构体 */
.open = xxx_vma_open,
.close = xxx_vma_close,
...
};
nopage
除了 remap_pfn_range()以外,在驱动程序中实现 VMA 的 nopage()函数通常可以为设备提供更加灵活的内存映射途径。当访问的页不在内存,即发生缺页异常时, nopage()会被内核自动调用。
static int xxx_mmap(struct file *filp, struct vm_area_struct *vma)
{
unsigned long offset = vma->vm_pgoff if (offset >= _ _pa(high_memory) || (filp->f_flags &O_SYNC))
vma->vm_flags |= VM_IO;
vma->vm_flags |= VM_RESERVED; /* 预留 */
vma->vm_ops = &xxx_nopage_vm_ops;
xxx_vma_open(vma);
return 0;
}
struct page *xxx_vma_nopage(struct vm_area_struct *vma, unsigned long
address, int *type)
{
struct page *pageptr;
unsigned long offset = vma->vm_pgoff vm_start + offset; /* 物理地
址 */
unsigned long pageframe = physaddr >> PAGE_SHIFT; /* 页帧号 */
if (!pfn_valid(pageframe)) /* 页帧号有效? */
return NOPAGE_SIGBUS;
pageptr = pfn_to_page(pageframe); /* 页帧号->页描述符 */
get_page(pageptr); /* 获得页,增加页的使用计数 */
if (type)
*type = VM_FAULT_MINOR;
return pageptr; /*返回页描述符 */
}
上述函数对常规内存进行映射, 返回一个页描述符,可用于扩大或缩小映射的内存区域。
由此可见, nopage()与 remap_pfn_range()的一个较大区别在于 remap_pfn_range()一般用于设备内存映射,而 nopage()还可用于 RAM 映射,其调用发生在缺页异常时。
この記事を通じて、Linux デバイス ドライバーにおけるメモリ管理のアプリケーションと役割を理解し、メモリ管理の作成、呼び出し、操作、変更、デバッグの方法を学びます。メモリ管理は、メモリリソースを簡単に記述・制御し、有効利用と高度な機能を実現できる、組み込みシステム開発に非常に適した手法であることが分かりました。もちろん、メモリ管理には、構文仕様に従う必要がある、権限の問題に注意を払う必要がある、パフォーマンスへの影響に注意を払う必要があるなど、いくつかの注意事項と制限もあります。したがって、メモリ管理を使用する場合は、一定のハードウェアの知識と経験、および優れたプログラミングの習慣とデバッグ スキルが必要です。この記事が入門レベルのガイドとして提供され、メモリ管理について予備的な理解が得られることを願っています。メモリ管理についてさらに詳しく知りたい場合は、より多くの資料や例を参照するだけでなく、自分で練習して探索することをお勧めします。
以上がLinuxデバイスドライバーのメモリ管理について詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



