


春節前に、Tongyi Qianwen Model (Qwen) のバージョン 1.5 がオンラインになりました。今朝、新しいバージョンのニュースが AI コミュニティで懸念を引き起こしました。
大型モデルの新バージョンには、0.5B、1.8B、4B、7B、14B、72B の 6 つのモデル サイズが含まれています。その中でも最強バージョンの性能はGPT 3.5やMistral-Mediumを上回ります。このバージョンには Base モデルと Chat モデルが含まれており、多言語サポートを提供します。
アリババのTongyi Qianwenチームは、関連技術がTongyi Qianwen公式WebサイトとTongyi Qianwenアプリでもリリースされたと述べました。
さらに、Qwen 1.5 の本日のリリースには次のハイライトもあります:
より高度な大規模モデルを審査員として使用することで、Tongyi Qianwen チームは、広く使用されている 2 つのベンチマーク、MT-Bench と Alpaca-Eval で Qwen1.5 を実行しました。事前評価。評価結果は次のとおりです。
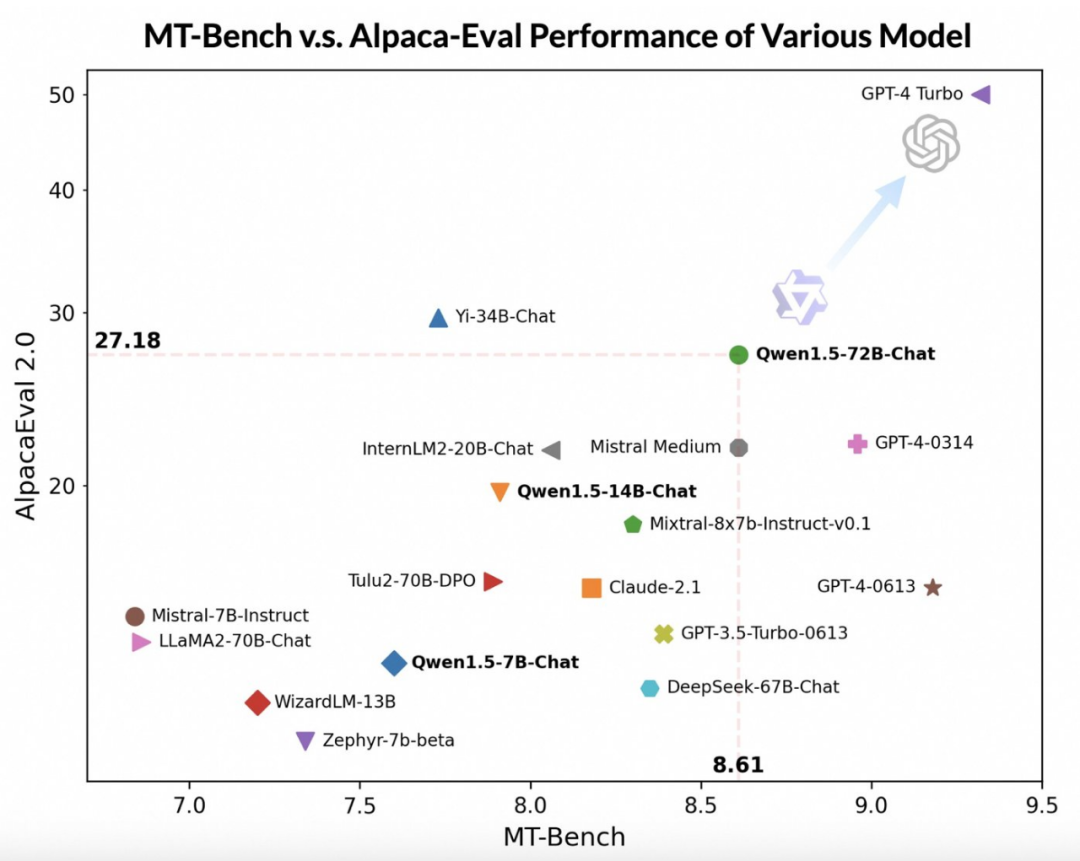
##Qwen1.5-72B-Chat モデルは GPT-4-Turbo に比べて遅れていますが、MT ではパフォーマンスが優れています。 -Alpaca-Eval v2 でのベンチテストとインテストでは、印象的なパフォーマンスを示しました。実際、Qwen1.5-72B-Chat は、Claude-2.1、GPT-3.5-Turbo-0613、Mixtral-8x7b-instruct、TULU 2 DPO 70B を上回り、最近注目を集めている Mistral Medium モデルにも匹敵する性能を持っています。 。 匹敵します。これは、Qwen1.5-72B-Chat モデルが自然言語処理においてかなりの強みを持っていることを示しています。
Tongyi Qianwen チームは、大規模モデルのスコアは回答の長さに関係している可能性があるが、人間の観察では Qwen1.5 は過度に長い回答の影響を受けないことが示されていると指摘しました。衝撃評価。 AlpacaEval 2.0 データによると、Qwen1.5-Chat の平均長は 1618 で、GPT-4 と同じ長さですが、GPT-4-Turbo よりも短いです。
Tongyi Qianwen の開発者は、ここ数カ月間、優れたモデルを構築し、開発者のエクスペリエンスを継続的に向上させることに取り組んできたと述べました。

以前のバージョンと比較して、このアップデートはチャット モデルを人間の好みに合わせて改善することに重点を置き、モデルの多言語処理を大幅に強化しています。力。シーケンスの長さに関しては、すべてのスケール モデルで 32768 トークンのコンテキスト長範囲のサポートが実装されています。同時に、事前トレーニングされた基本モデルの品質も大幅に最適化されており、微調整プロセス中により良いエクスペリエンスを人々に提供することが期待されています。
モデルの基本機能の評価に関して、Tongyi Qianwen チームは MMLU (5 ショット)、C を実施しました。 -Eval、Qwen1.5 は、Humaneval、GS8K、BBH などのベンチマーク データセットで評価されました。
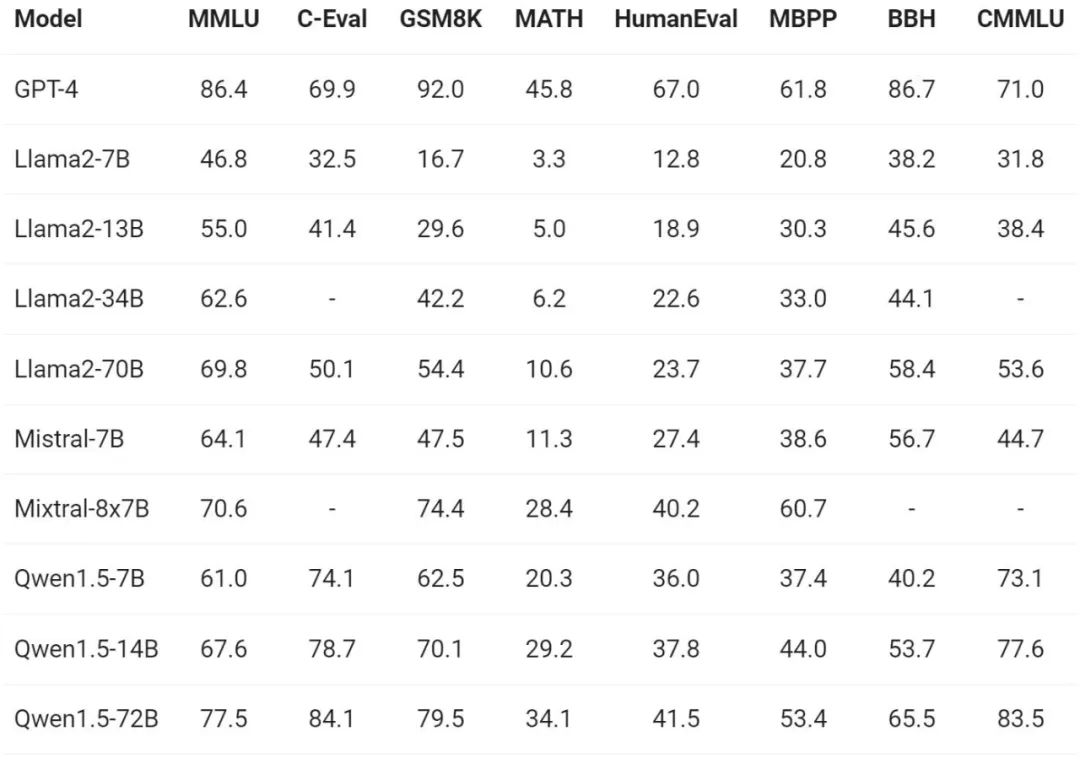
さまざまなモデル サイズの下で、Qwen1.5 は評価ベンチマークで優れたパフォーマンスを示し、72B バージョンはすべてのベンチマークで良好なパフォーマンスを示しました。 70B では、言語理解、推論、数学における能力を実証しました。
最近、小規模モデルの構築が業界で注目を集めています。Tongyi Qianwen チームは、モデル パラメーターが 70 億未満の Qwen1.5 モデルを比較しました。比較:
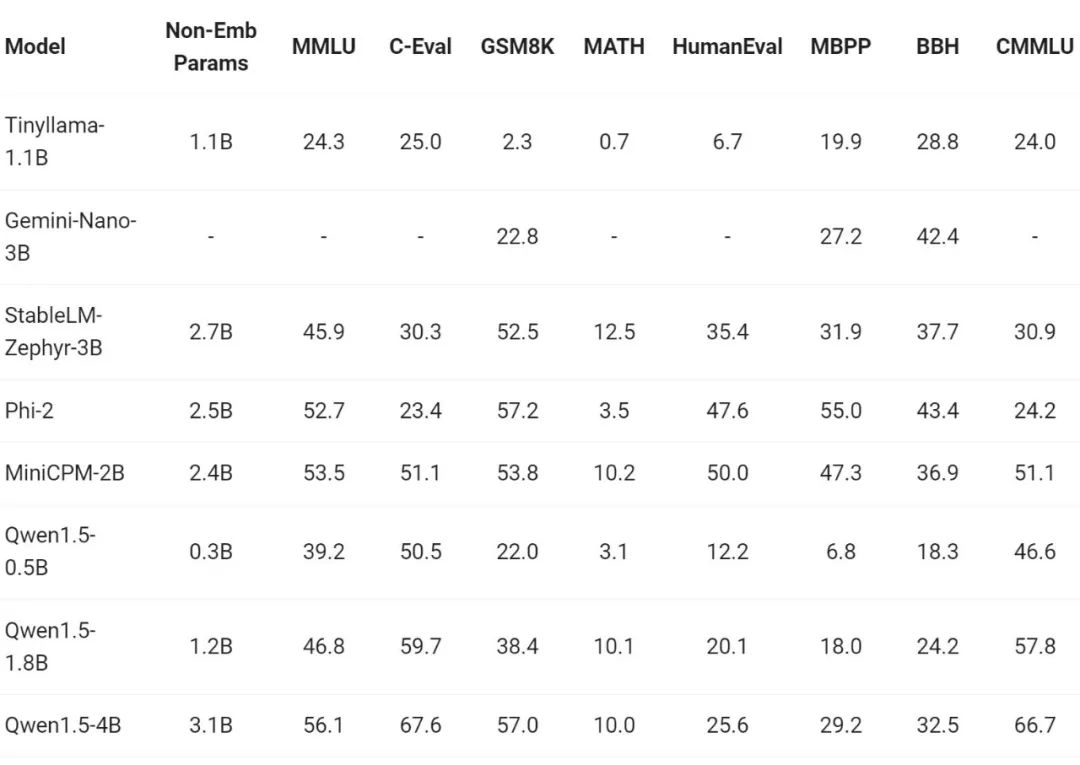
Qwen1.5 は、パラメーター サイズ範囲が 7 未満の業界をリードする小型モデルと非常に競争力があります。億の力。
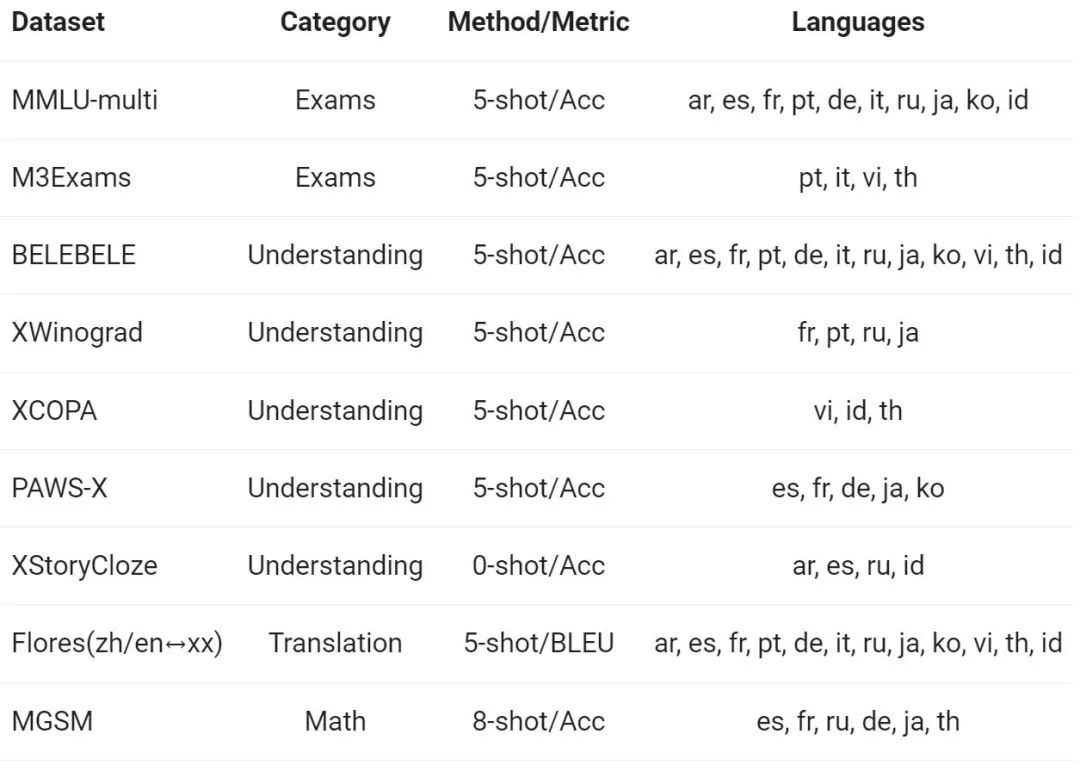
Tongyi Qianwen チームは、ヨーロッパ、東アジア、東南アジアの 12 の異なる言語で基本モデルを評価しました。アジアの多言語対応。アリババの研究者は、オープンソース コミュニティの公開データ セットから、試験、理解、翻訳、数学の 4 つの異なる側面をカバーする、次の表に示す評価セットを構築しました。以下の表は、評価構成、評価指標、関連する特定の言語など、各テスト セットの詳細を示しています。
詳細な結果は次のとおりです:
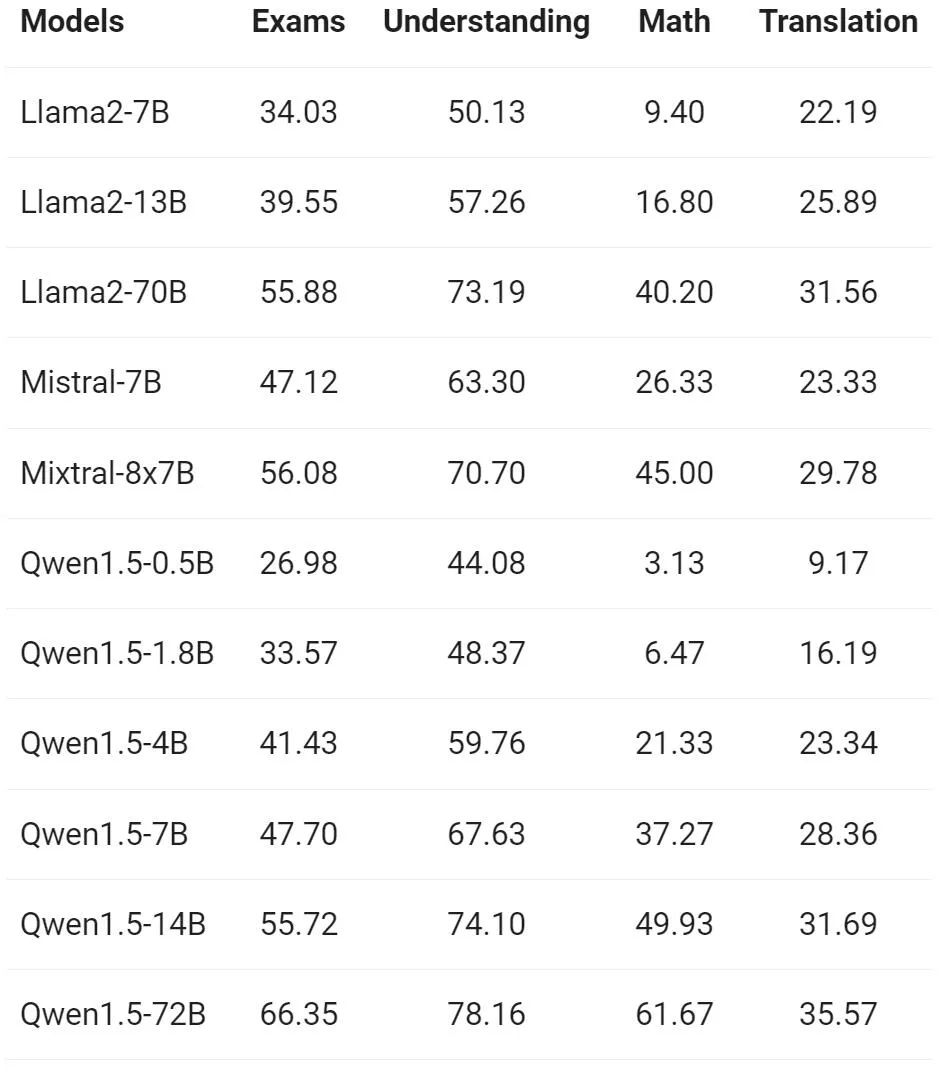
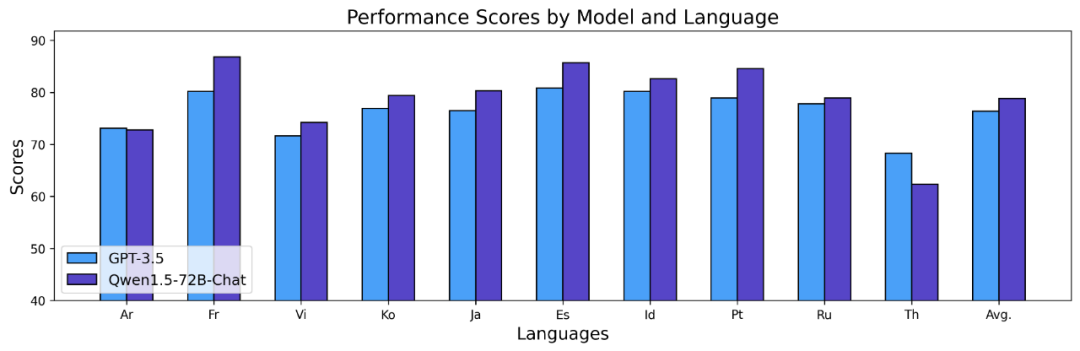
上記の結果は、Qwen1.5 基本モデルが 12 の異なる言語の多言語機能で良好なパフォーマンスを示し、主題の知識、言語理解、翻訳、数学などのさまざまな側面の評価でも優れたパフォーマンスを示していることを示しています。結果。さらに、チャット モデルの多言語機能に関しては、次の結果が観察されます。
長いシーケンスの理解に対する需要が高まり続ける中、アリババは新しいバージョンで Qianwen モデルの対応する機能を改善しました Qwen1.5 モデルの全シリーズは 32,000 トークンのコンテキストをサポートしています。 Tongyi Qianwen チームは、長いコンテキストに基づいて応答を生成するモデルの能力を測定する L-Eval ベンチマークで Qwen1.5 モデルのパフォーマンスを評価しました。結果は以下の通りです。
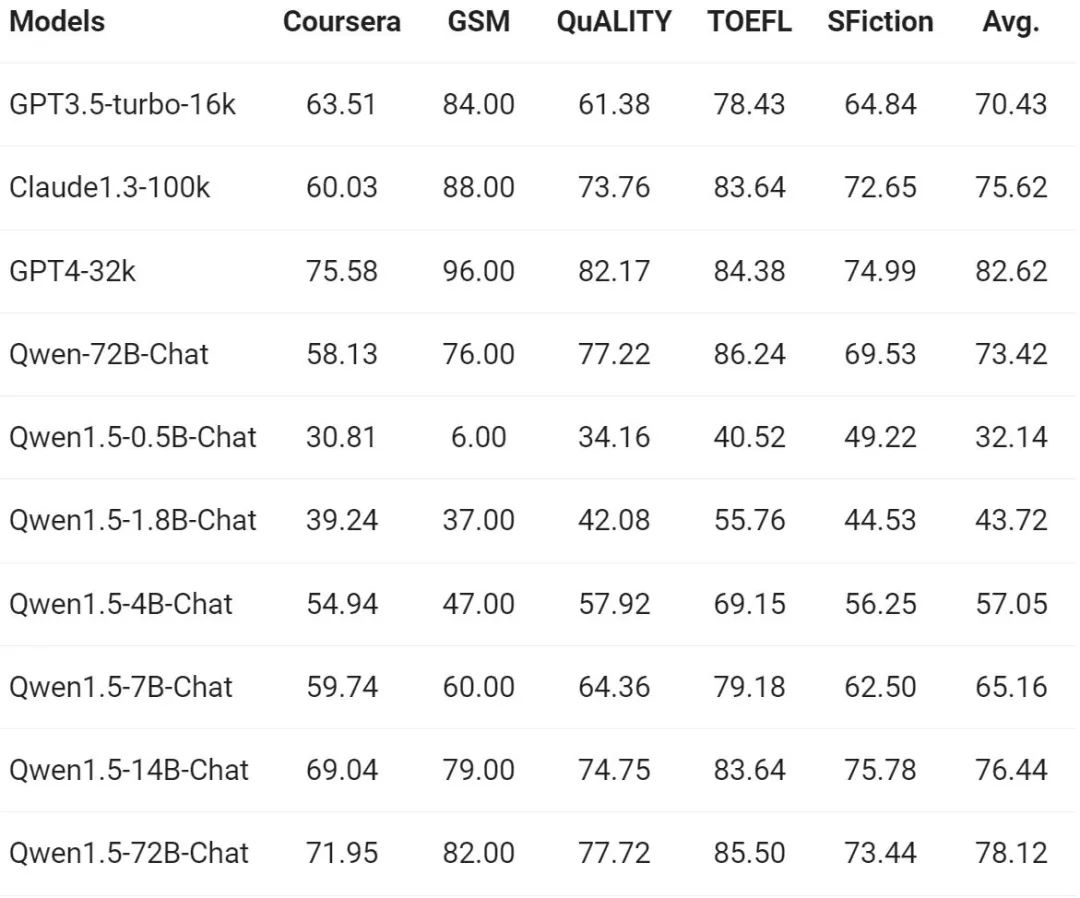
#結果から、Qwen1.5-7B-Chat のような小規模なモデルでも同等のパフォーマンスを示すことができます。 GPT -3.5 と同等のパフォーマンスですが、最大のモデルである Qwen1.5-72B-Chat は GPT4-32k にわずかに劣ります。
上記の結果は、トークンの長さが 32K の場合の Qwen 1.5 の効果のみを示しており、モデルが最大長の 32K しかサポートできないという意味ではないことに注意してください。 。開発者は、config.json の max_position_embedding をより大きな値に変更して、より長いコンテキスト理解シナリオでモデルが満足のいく結果を達成できるかどうかを観察できます。
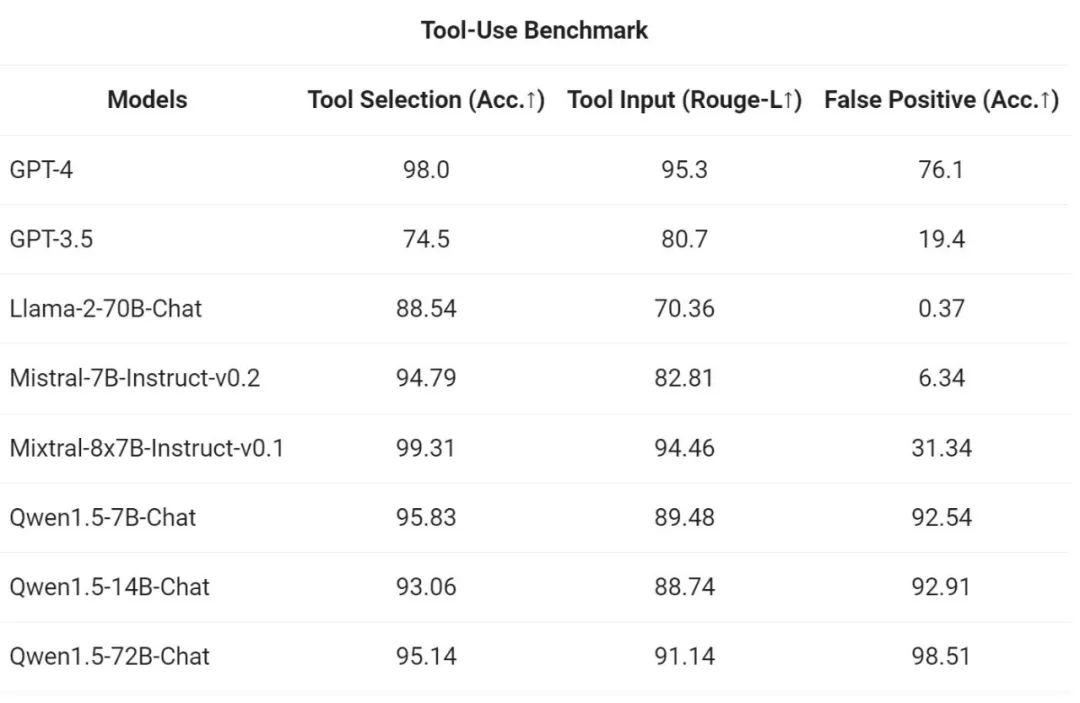
現在、一般言語モデルの魅力の 1 つは、外部システムとインターフェイスできる潜在的な機能にあります。コミュニティで急速に浮上しているタスクとして、RAG は、幻覚やリアルタイムの更新情報やプライベート データの取得不能など、大規模な言語モデルが直面する典型的な課題のいくつかに効果的に対処します。さらに、言語モデルは、API を使用し、指示と例に基づいてコードを作成する際の強力な機能を示します。大規模なモデルは、コード インタープリターを使用したり、AI エージェントとして機能したりして、より広範な価値を実現できます。
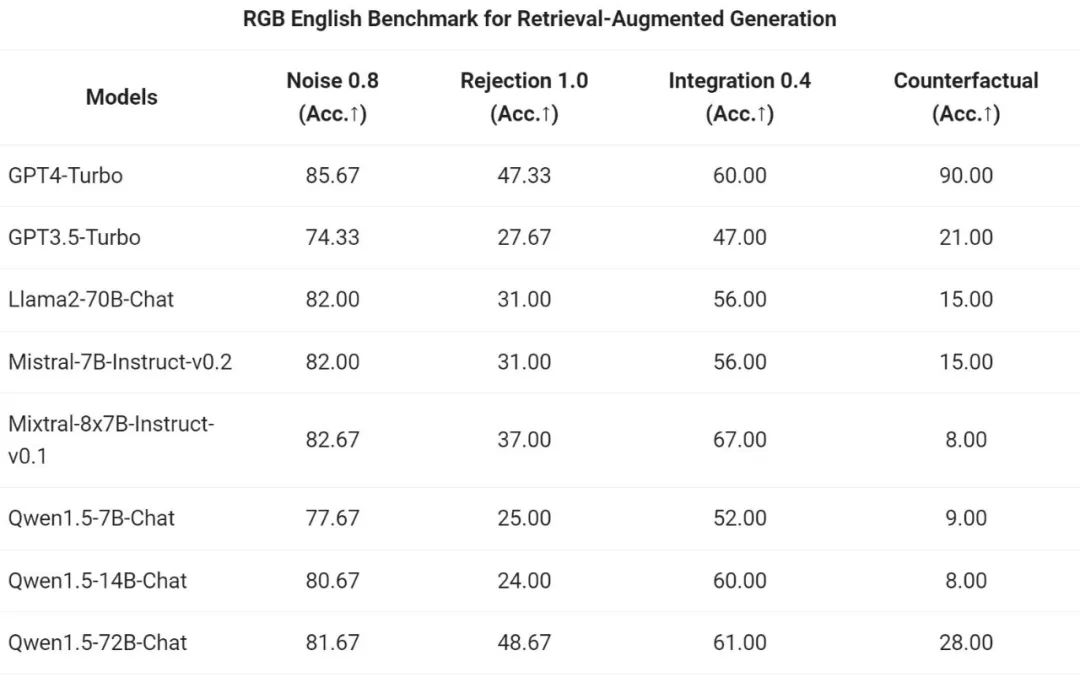
Tongyi Qianwen チームは、RAG タスクに対する Qwen1.5 シリーズ チャット モデルのエンドツーエンドの効果を評価しました。評価は、中国語と英語の RAG 評価に使用されるセットである RGB テスト セットに基づいています。
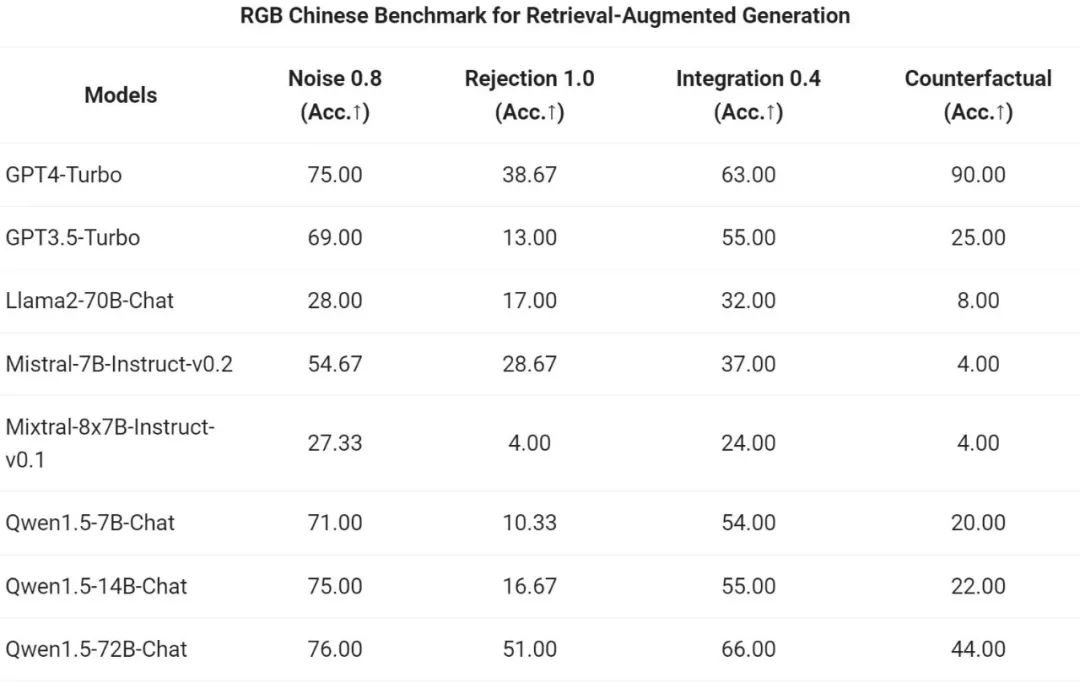
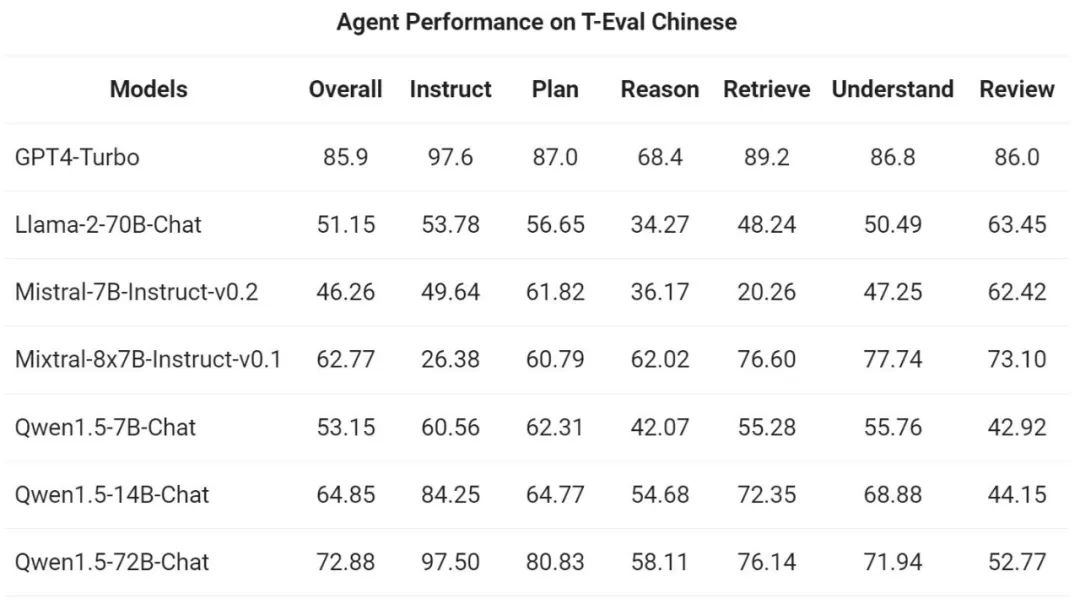
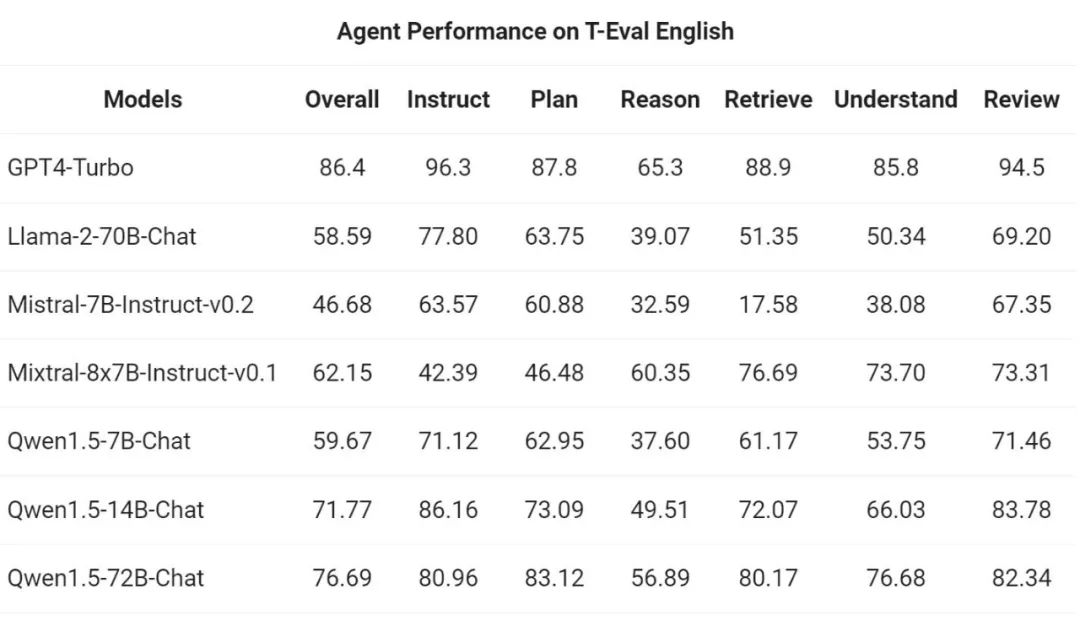
次に、パスします。 Yiqianwen チームは、T-Eval ベンチマークで汎用エージェントとして実行する Qwen1.5 の能力を評価しました。すべての Qwen1.5 モデルは、ベンチマーク専用に最適化されていません:
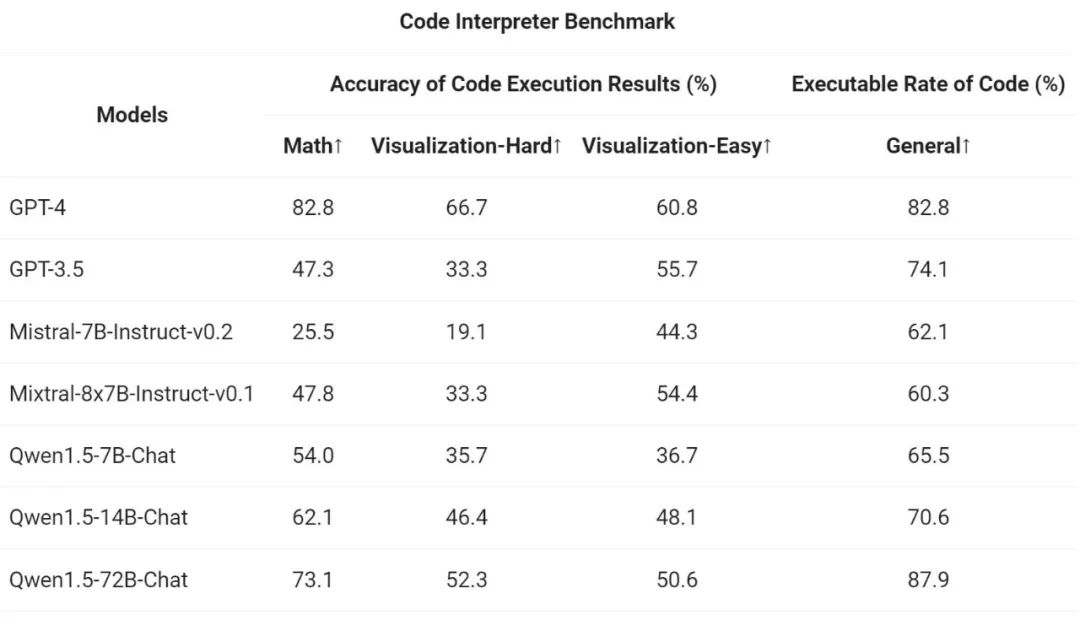
Qwen1.5 は、HuggingFace トランスフォーマー コード ベースと統合されています。バージョン 4.37.0 以降、開発者は Qwen1.5 を使用するためにカスタム コードをロードせずに (trust_remote_code オプションを指定して) トランスフォーマー ライブラリのネイティブ コードを直接使用できるようになりました。
オープンソース エコシステムにおいて、Alibaba は vLLM、SGLang (展開用)、AutoAWQ、AutoGPTQ (定量化用)、Axolotl、LLaMA-Factory (微調整用)、および llama.cpp (ローカル用) と協力してきました。 LLM 推論) などのフレームワークが含まれており、そのすべてが Qwen1.5 をサポートするようになりました。 Qwen1.5 シリーズは現在、Ollama や LMStudio などのプラットフォームでも利用できます。
以上がTongyi Qianwen が再びオープンソースになり、Qwen1.5 では 6 つのボリューム モデルが提供され、そのパフォーマンスは GPT3.5 を超えますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



