


Linux の使用は、ユーザー空間プログラムとファイル システムのプログラミングに密接に関連しています。ファイル システムの概念についてはすでにご存知かと思いますので、詳しい説明は省略します。結局のところ、これらの概念を理解できれば、さらに詳しく知りたい人はいつでも、Baidu などの検索エンジンを通じてより多くの情報を得ることができます。ここでは、Linux の仮想ファイル システムに焦点を当てます。
仮想ファイル システムは Linux の重要な機能の 1 つであり、さまざまなファイル システムをサポートします。ファイル システムの構造は次の図に示されています。 [画像の原文を参照]
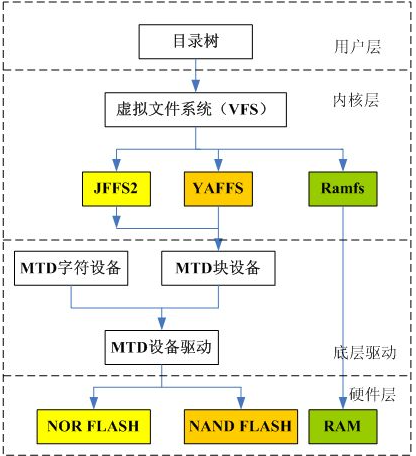
上の図の VFS (仮想ファイル システム) は、ファイル システムの一般的な表現を保存するためにデータ構造に依存しています。データ構造は次のとおりです:
スーパー ブロック構造: インストールされているファイル システムに関連する情報を保存します;
インデックス ノード構造: ファイルに関する情報を保存します;
ファイル構造: プロセスによって開かれたファイルに関連する情報を保存します;
ディレクトリ エントリ構造: パス名とそのパス名が指すファイルに関する情報を格納します。
Linux カーネルは、グローバル変数を使用して、前述の構造体へのポインタを保存します。すべての構造体は、二重リンク リストに保存されます。カーネルは、ポインタをリンク リストの先頭に保存し、リンクされたリストのアクセス ポイントとして使用します。これらの構造は list_head タイプのフィールドを使用し、リンク リストの前の要素を指すために使用します。次の表は、カーネルによって保存されるグローバル変数と、これらの変数が指すリンク リストのタイプです (グローバル変数関連) VFS へ)
| グローバル変数 | 構造タイプ |
|---|---|
| スーパーブロック | スーパーブロック |
| ファイルシステム | ファイルシステムの種類 |
| dentry_unused | デントリ |
| vfsmntlist | vfsマウント |
| inode_in_use | inode |
| inode_unused | inode |
Super_block、file_system_type、dentry、および vfsmoubt 構造はすべて、独自のリンク リストに保存されます。インデックス ノードは、グローバル inode_in_use または inode_unused、または対応する超高速ローカル リンク リスト上で見つけることができます。 。
メインの VFS 構造に加えて、VFS、fs_struct および files_struct、namespace、fd_set と対話する他の構造がいくつかあります。次の図は、プロセス記述子がファイル関連の構造にどのように関連付けられているかを示しています。
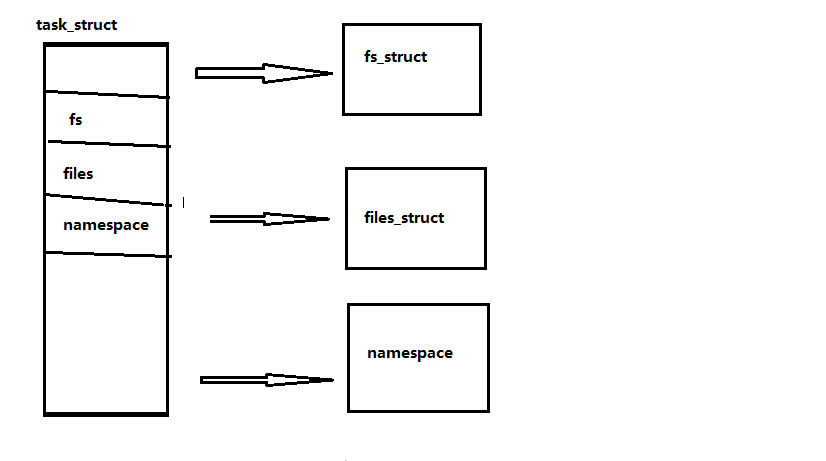
まず fs_struct 構造体を紹介します。fs_struct 構造体は複数のプロセス記述子から参照できます。次のコードは include/Linux/fs_struct.h にあります。コードがよくわからない場合は、次のコードを参照してください。アドバイスをください。
リーリーfiles_struct には、開いているファイルとその記述子に関する情報が含まれており、これらのコレクションを使用して記述子をグループ化します。次のコードは include/linux/file.h
で確認できます。 リーリーINIT_FILES マクロを使用して fs_struct 構造体を初期化します:
リーリーNR_OPEN_DEFAULT のグローバル定義は BITS_PER_LONG に設定されます。BITS_PER_LONG は、32 ビット システムでは 32、64 ビット システムでは 64 です。
ページ バッファリングを紹介し、それがどのように機能し、実装されるかを見てみましょう。 Linux では、メモリはパーティションに分割されています。それぞれのパーティションには、アクティブなページのリンク リストと非アクティブなリンク リストがあります。ページが非アクティブなときは、ディスクに書き戻されます。次の図は、上記の関係を示しています:
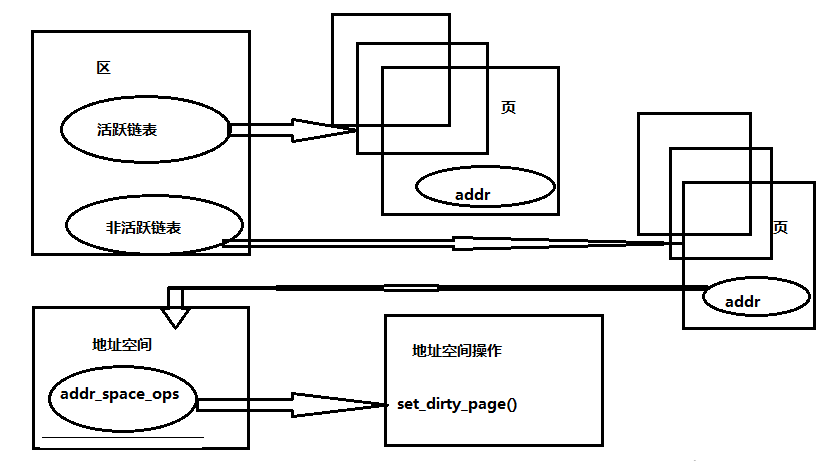
画像-20240202221039708
ページ バッファリングの中核は address_space オブジェクトであり、そのコードは include/linux/fs.h で確認できます (このコードはよく理解できません。アドバイスをお願いします):
リーリーLinux カーネルは、ブロック デバイス上の各セクタも、buffer_head 構造として表します。buffer_head 構造によって使用される物理領域は、デバイス b_dev の論理ブロック b_blocknr です。参照される物理メモリは、b_data から始まり、ブロック サイズは b_size ですバイト. メモリ データ ブロック. このメモリ ブロックは物理ページ b_page 内にあります。その構造は次のとおりです:
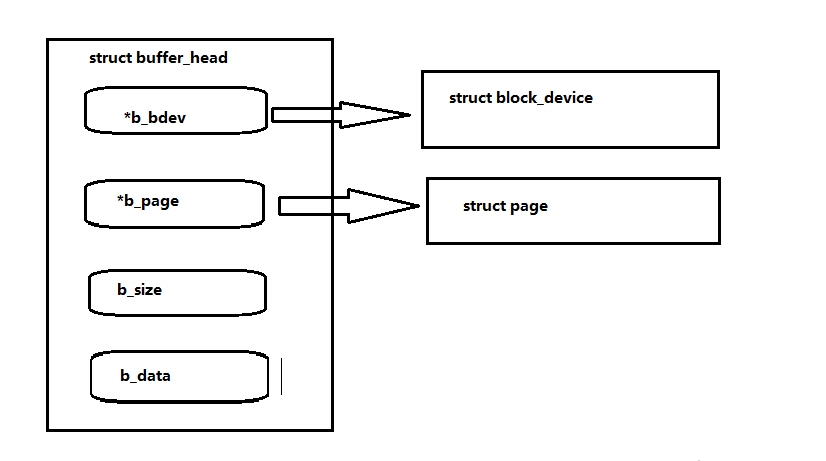
最後に、VFS システム コールとファイル システム レイヤーについて説明し、それらの実行をカーネル レベルまで追跡しましょう。まず、open()、close()、read()、write( の 4 つの関数を理解する必要があります。 )。
open() 関数:
open 関数は、ファイルを開いて作成するために使用されます。以下は、open 関数の簡単な説明です
リーリー戻り値: 成功した場合はファイル記述子を返し、それ以外の場合は -1
を返します。open 関数の場合、3 番目のパラメーター (...) は、新しいファイルを作成する場合にのみ使用され、ファイルのアクセス許可ビットを指定するために使用されます。 pathname は、開かれる/作成されるファイルのパス名です (C:/cpp/a.cpp など)。oflag は、ファイルの開く/作成モードを指定するために使用されます。このパラメータは、次の定数で構成できます (定義済みfcntl.h 内) 論理和を介して。
O_RDONLY 読み取り専用モード
O_WRONLY 書き込み専用モード
O_RDWR 読み取りおよび書き込みモード
ファイルを開く/作成するときは、上記の 3 つの定数のうち少なくとも 1 つを使用する必要があります。次の定数はオプションです:
O_APPEND 各書き込み操作はファイルの末尾に書き込まれます
O_CREAT 指定したファイルが存在しない場合は、このファイルを作成します
O_EXCL 作成するファイルが既に存在する場合は、-1を返し、errno
の値を変更します。O_TRUNC ファイルが存在し、書き込み専用/読み取り/書き込みモードで開かれている場合は、ファイルの内容全体をクリアします
O_NOCTTY パス名が端末デバイスを指している場合は、このデバイスを制御端末として使用しないでください。
O_NONBLOCK パス名が FIFO/ブロック ファイル/キャラクター ファイルを指している場合、ファイルのオープンと後続の I/O をノンブロッキング モード (ノンブロッキング モード) に設定します。
open によって返されるファイル記述子は、未使用の最小の記述子である必要があります。
NAME_MAX ('\0' を除くファイル名の最大長) が 14 で、現在のディレクトリに 14 バイトを超えるファイル名を持つファイルを作成する場合、初期の System V システム (SVR2 など)それを超えると、最初の 14 バイトのみが保持され、BSD 派生システムはエラー メッセージを返し、errno を ENAMETOOLONG に設定します。
POSIX.1 引入常量 _POSIX_NO_TRUNC 用于决定是否截断长文件名/长路径名。如果_POSIX_NO_TRUNC 设定为禁止截断,并且路径名长度超过 PATH_MAX(包括 ‘\0’),或者组成路径名的任意文件名长度超过 NAME_MAX,则返回错误信息,并且把 errno 置为 ENAMETOOLONG。
close()函数
进程使用完文件后,发出close()系统调用:
sysopsis
#include int close(int fd);
参数:fd文件描述符
函数返回值:0成功,-1出错
参数fd是要关闭的文件描述符。需要说明的是:当一个进程终止时,内核对该进程所有尚未关闭的文件描述符调用close关闭,所以即使用户程序不调用close,在终止时内核也会自动关闭它打开的所有文件。但是对于一个长年累月运行的程序(比如网络服务器),打开的文件描述符一定要记得关闭,否则随着打开的文件越来越多,会占用大量文件描述符和系统资源。
read()函数
当用户级别程序调用read()函数时,Linux把它转换成系统调sys_read():
功能描述:从文件读取数据。
所需头文件: #include
函数原型:ssize_t read(int fd, void *buf, size_t count);
参数:
fd: 将要读取数据的文件描述词。
buf:指缓冲区,即读取的数据会被放到这个缓冲区中去。
count:表示调用一次read操作,应该读多少数量的字符。
返回值:返回所读取的字节数;0(读到EOF);-1(出错)。
以下几种情况会导致读取到的字节数小于 count :
读取普通文件时,读到文件末尾还不够 count 字节。例:如果文件只有 30 字节,而我们想读取 100,字节,那么实际读到的只有 30 字节, 函数返回 30 。此时再使用 read 函数作用于这个文件会导致 read 返回 0
从终端设备(terminal device)读取时,一般情况下每次只能读取一行。
从网络读取时,网络缓存可能导致读取的字节数小于 count字节。
读取 pipe 或者 FIFO 时,pipe 或 FIFO 里的字节数可能小于 count 。
从面向记录(record-oriented)的设备读取时,某些面向记录的设备(如磁带)每次最多只能返回一个记录。
在读取了部分数据时被信号中断,读操作始于 cfo 。在成功返回之前,cfo 增加,增量为实际读取到的字节数。
例程如下(程序是网上找的例子,贴下来以以供大家理解一下)::
#include
#include
#include
#include
#include
#include
int main(void)
{
void* buf ;
int handle;
int bytes ;
buf=malloc(10);
/*
LooksforafileinthecurrentdirectorynamedTEST.$$$andattempts
toread10bytesfromit.Tousethisexampleyoushouldcreatethe
fileTEST.$$$
*/
handle=open("TEST.$$$",O_RDONLY|O_BINARY,S_IWRITE|S_IREAD);
if(handle==-1)
{
printf("ErrorOpeningFile\n");
exit(1);
}
bytes=read(handle,buf,10);
if(bytes==-1)
{
printf("ReadFailed.\n");
exit(1);
}
else
{
printf("Read:%dbytesread.\n",bytes);
}
return0 ;
}
write()函数
功能描述:向文件写入数据。
所需头文件: #include
函数原型:ssize_t write(int fd, void *buf, size_t count);
返回值:写入文件的字节数(成功);-1(出错)
功能:write 函数向 filedes 中写入 count 字节数据,数据来源为 buf 。返回值一般总是等于 count,否则就是出错了。常见的出错原因是磁盘空间满了或者超过了文件大小限制。对于普通文件,写操作始于 cfo 。如果打开文件时使用了 O_APPEND,则每次写操作都将数据写入文件末尾。成功写入后,cfo 增加,增量为实际写入的字节数。
例程如下(程序是网上找的例子,贴下来以以供大家理解一下):
#include
#include
#include
#include
#include
#include
int main(void)
{
int *handle; char string[40];
int length, res;/* Create a file named "TEST.$$$" in the current directory and write a string to it. If "TEST.$$$" already exists, it will be overwritten. */
if ((handle = open("TEST.$$$", O_WRONLY | O_CREAT | O_TRUNC, S_IREAD | S_IWRITE)) == -1)
{
printf("Error opening file.\n");
exit(1);
}
strcpy(string, "Hello, world!\n");
length = strlen(string);
if ((res = write(handle, string, length)) != length)
{
printf("Error writing to the file.\n");
exit(1);
}
printf("Wrote %d bytes to the file.\n", res);
close(handle); return 0; }
小结
今天看的代码不多,差不多都是网上找的代码,有些解释也是查阅资料写上去的,有些还是不懂,希望各路大神指教,这里我总结了有关Linux文件系统实现的问题,但是具体的细节方面并没有提及到,大家看了之后应该只能有一个大致的最Linux文件系统的了解,有读者问我看的是哪些书,这里我说明一下,看了Linux内核编程,还有深入理解Linux内核以及网上各种资料或者其他大牛写的好的博客。这里我是总结了一下,并且把自己不懂的还有觉得重要的说了一下,希望各位大神给些建议,thanks~
以上がLinux カーネルと Linux ファイル システムの実装に関連する問題について学ぶ 24 時間の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



