8 バイナリ ビットは 1 バイトと呼ばれます|
#########キャラクター###
###言葉###
| コンピュータがトランザクションを一度に処理するために使用する固定長
|
|
単語の長さ
ワード内のビット数、つまり現代のコンピューターのワード長は、通常 16、32、または 64 ビットです。 (一般に、N ビット システムの語長は N/8 バイトです。)
異なる CPU は、一度に異なる数のデータ ビットを処理できます。32 ビット CPU は一度に 32 ビット データを処理でき、64 ビット CPU は一度に 64 ビット データを処理できます。ここでのビット語長を参照してください。
いわゆる語長のことをワードと呼ぶこともあります。 16 ビット CPU では、1 ワードはちょうど 2 バイトですが、32 ビット CPU では、1 ワードは 4 バイトです。キャラクターを単位とすると、その上にダブルキャラクター(2キャラクター)とクアッドキャラクター(4キャラクター)があります。
2. 配置ルール
標準データ型の場合、そのアドレスはその長さの整数倍である必要があるだけです。非標準データ型は次の原則に従って整列されます: 配列: 基本データ型に従って整列されます。最初のデータ型は、以下の通りです。 Union: 含まれるデータ型の最大長によって整列されます。構造: 構造内の各データ型は整列している必要があります。
3. バイト アライメントの数を制限するにはどうすればよいですか?
1.デフォルト
デフォルトでは、C コンパイラは、自然な境界条件に従って各変数またはデータ単位にスペースを割り当てます。一般に、デフォルトの境界条件は次の方法で変更できます。
2.#pragma Pack(n)
· #pragma Pack (n) ディレクティブを使用すると、C コンパイラは n バイトずつ整列します。 · カスタム バイト アライメントをキャンセルするには、ディレクティブ #pragma Pack () を使用します。
#pragma Pack(n) は、変数を n バイトのアライメントに設定するために使用されます。 n バイトのアライメントは、変数が格納される開始アドレスのオフセットには 2 つの状況があることを意味します。
n が変数によって占有されるバイト数以上の場合、オフセットはデフォルトのアライメントを満たしている必要があります-
n が変数の型が占めるバイト数より小さい場合、オフセットは n の倍数となり、デフォルトのアライメントを満たす必要はありません。 -
構造体の合計サイズにも制約があります。n がすべてのメンバー変数の型が占めるバイト数以上の場合、構造体の合計サイズは次の数値でなければなりません。最大のスペースを占める変数が占めるスペースの倍数、それ以外の場合は n の倍数でなければなりません。
3.__属性
さらに、次のメソッドがあります: · __attribute((aligned (n)))。これは、作用される構造体のメンバーを n バイトの自然な境界に位置合わせします。構造内のいずれかのメンバーの長さが n より大きい場合、最大のメンバーの長さに応じて位置合わせされます。 · attribute ((packed)) は、コンパイル中に構造体の最適化された配置をキャンセルし、実際に占有されているバイト数に従って構造を配置します。
3.Assembly.align
アセンブリ コードは通常、.align を使用してバイト アラインメント ビット数を指定します。
.align: データの配置を指定するために使用されます。形式は次のとおりです:
リーリー
未使用のストレージ領域を特定の配置の値で埋めます。最初の値は配置 (4、8、16、または 32) を表します。2 番目の式の値は、埋められた値を表します。
四、为什么要对齐?
操作系统并非一个字节一个字节访问内存,而是按2,4,8这样的字长来访问。因此,当CPU从存储器读数据到寄存器,IO的数据长度通常是字长。如32位系统访问粒度是4字节(bytes), 64位系统的是8字节。当被访问的数据长度为n字节且该数据地址为n字节对齐时,那么操作系统就可以高效地一次定位到数据, 无需多次读取,处理对齐运算等额外操作。数据结构应该尽可能地在自然边界上对齐。如果访问未对齐的内存,CPU需要做两次内存访问。
字节对齐可能带来的隐患:
代码中关于对齐的隐患,很多是隐式的。比如在强制类型转换的时候。例如:
unsigned int i = 0x12345678;
unsigned char *p=NULL;
unsigned short *p1=NULL;
p=&i;
*p=0x00;
p1=(unsigned short *)(p+1);
*p1=0x0000;
ログイン後にコピー
最后两句代码,从奇数边界去访问unsignedshort型变量,显然不符合对齐的规定。在x86上,类似的操作只会影响效率,但是在MIPS或者sparc上,可能就是一个error,因为它们要求必须字节对齐.
五、举例
例1:os基本数据类型占用的字节数
首先查看操作系统的位数
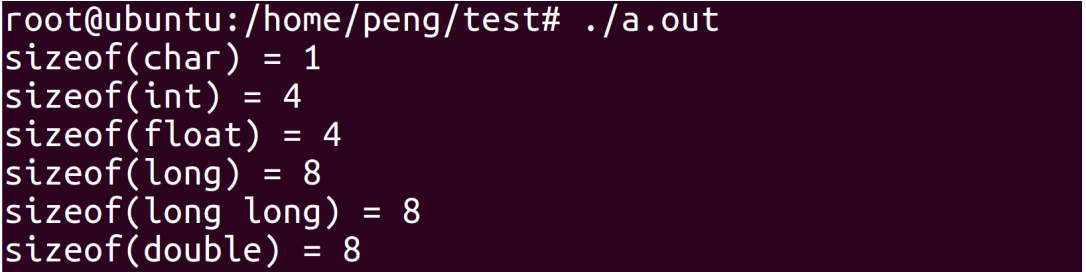
在64位操作系统下查看基本数据类型占用的字节数:
#include
int main()
{
printf("sizeof(char) = %ld\n", sizeof(char));
printf("sizeof(int) = %ld\n", sizeof(int));
printf("sizeof(float) = %ld\n", sizeof(float));
printf("sizeof(long) = %ld\n", sizeof(long));
printf("sizeof(long long) = %ld\n", sizeof(long long));
printf("sizeof(double) = %ld\n", sizeof(double));
return 0;
}
ログイン後にコピー
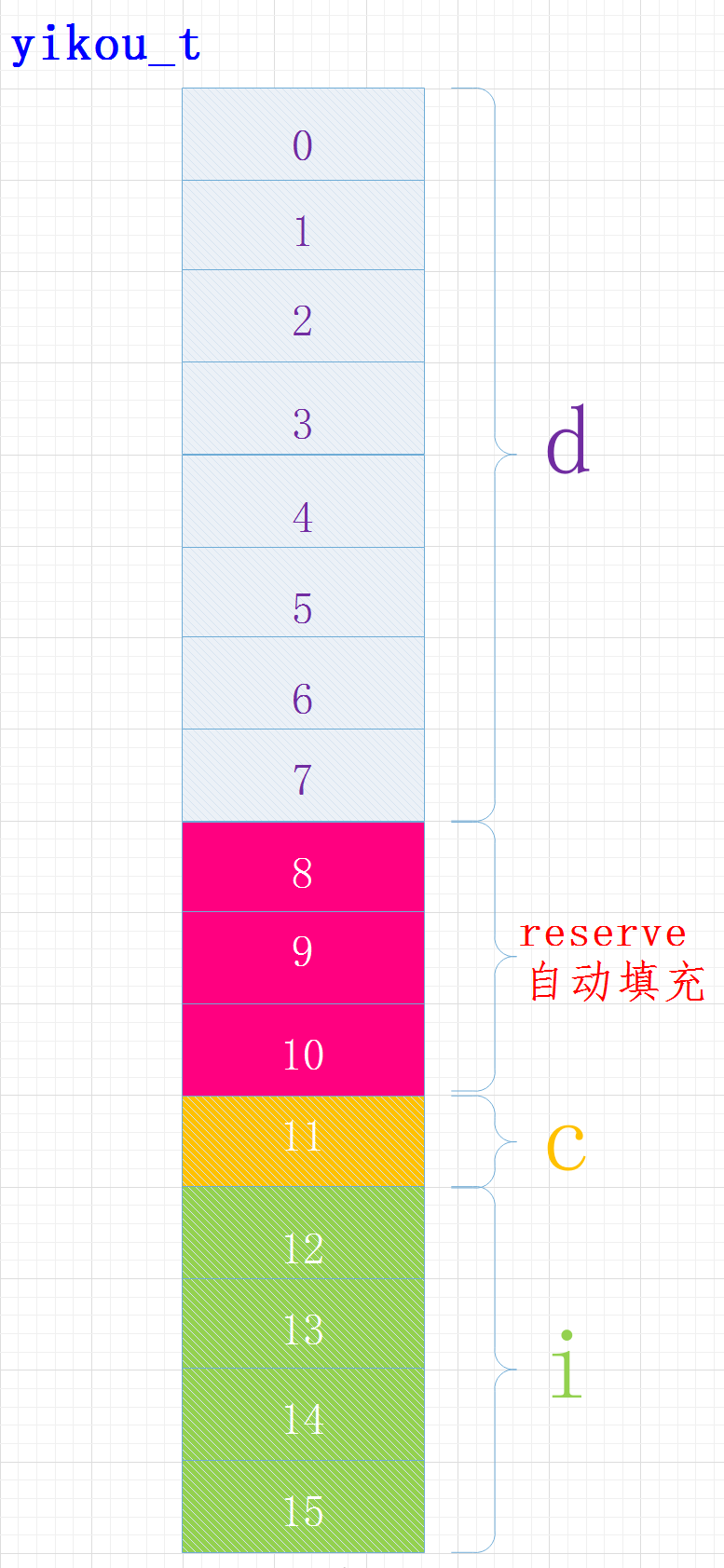
例2:结构体占用的内存大小–默认规则
考虑下面的结构体占用的位数
struct yikou_s
{
double d;
char c;
int i;
} yikou_t;
ログイン後にコピー
执行结果
sizeof(yikou_t) = 16
ログイン後にコピー
在内容中各变量位置关系如下:
其中成员C的位置还受字节序的影响,有的可能在位置8
编译器给我们进行了内存对齐,各成员变量存放的起始地址相对于结构的起始地址的偏移量必须为该变量类型所占用的字节数的倍数, 且结构的大小为该结构中占用最大空间的类型所占用的字节数的倍数。
对于偏移量:变量type n起始地址相对于结构体起始地址的偏移量必须为sizeof(type(n))的倍数结构体大小:必须为成员最大类型字节的倍数
char: 偏移量必须为sizeof(char) 即1的倍数
int: 偏移量必须为sizeof(int) 即4的倍数
float: 偏移量必须为sizeof(float) 即4的倍数
double: 偏移量必须为sizeof(double) 即8的倍数
ログイン後にコピー
例3:调整结构体大小
我们将结构体中变量的位置做以下调整:
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
ログイン後にコピー
执行结果
sizeof(yikou_t) = 24
ログイン後にコピー
各变量在内存中布局如下:
当结构体中有嵌套符合成员时,复合成员相对于结构体首地址偏移量是复合成员最宽基本类型大小的整数倍。
例4:#pragma pack(4)
#pragma pack(4)
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
sizeof(yikou_t) = 16
ログイン後にコピー
例5:#pragma pack(8)
#pragma pack(8)
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
sizeof(yikou_t) = 24
ログイン後にコピー
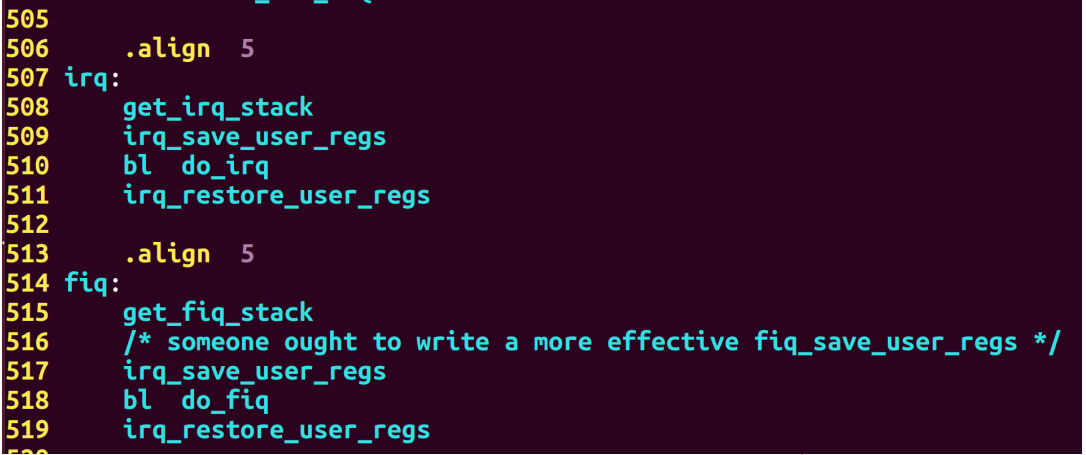
例6:汇编代码
举例:以下是截取的uboot代码中异常向量irq、fiq的入口位置代码:
六、汇总实力
有手懒的同学,直接贴一个完整的例子给你们:
#include
main()
{
struct A {
int a;
char b;
short c;
};
struct B {
char b;
int a;
short c;
};
struct AA {
// int a;
char b;
short c;
};
struct BB {
char b;
// int a;
short c;
};
#pragma pack (2) /*指定按2字节对齐*/
struct C {
char b;
int a;
short c;
};
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
#pragma pack (1) /*指定按1字节对齐*/
struct D {
char b;
int a;
short c;
};
#pragma pack ()/*取消指定对齐,恢复缺省对齐*/
int s1=sizeof(struct A);
int s2=sizeof(struct AA);
int s3=sizeof(struct B);
int s4=sizeof(struct BB);
int s5=sizeof(struct C);
int s6=sizeof(struct D);
printf("%d\n",s1);
printf("%d\n",s2);
printf("%d\n",s3);
printf("%d\n",s4);
printf("%d\n",s5);
printf("%d\n",s6);
}
ログイン後にコピー





 还受字节序的影响,有的可能在位置8
还受字节序的影响,有的可能在位置8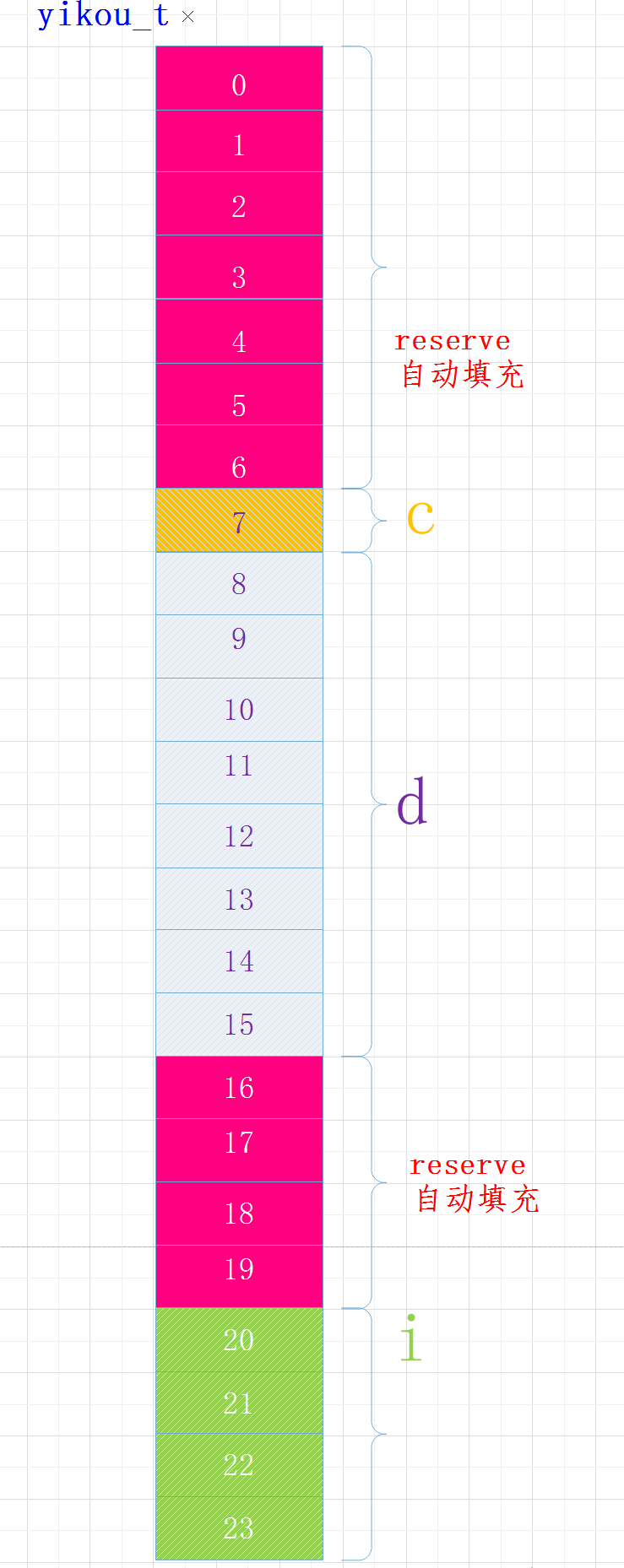















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



