


アテンションフリーな大型モデル Eagle7B: RWKV をベースに推論コストを 10 ~ 100 分の 1 に削減
AI トラックでは、最近小型モデルが大きな注目を集めています。数千億のパラメータを持つモデルと比較すると、Model.たとえば、フランスの AI スタートアップ企業がリリースした Mistral-7B モデルは、すべてのベンチマークで Llama 2 を 13B 上回り、コード、数学、推論では Llama 1 を 34B 上回りました。
大規模モデルと比較して、小規模モデルには、低いコンピューティング能力要件やデバイス側で実行できる機能など、多くの利点があります。
#最近、オープン ソースの非営利団体 RWKV から、7.52B パラメーター Eagle 7B という新しい言語モデルが登場しました。これには次の特徴があります。


現在、RWKV は第 6 世代 RWKV-6 まで反復されており、Transformer と同様のパフォーマンスとサイズを備えています。将来の研究者は、このアーキテクチャを使用して、より効率的なモデルを作成できます。
RWKV の詳細については、「Transformer 時代の RNN の再構築、RWKV は非 Transformer アーキテクチャを数百億のパラメータに拡張する」を参照してください。
RWKV-v5 Eagle 7B は、制限なく個人用または商用目的で使用できることは言及する価値があります。
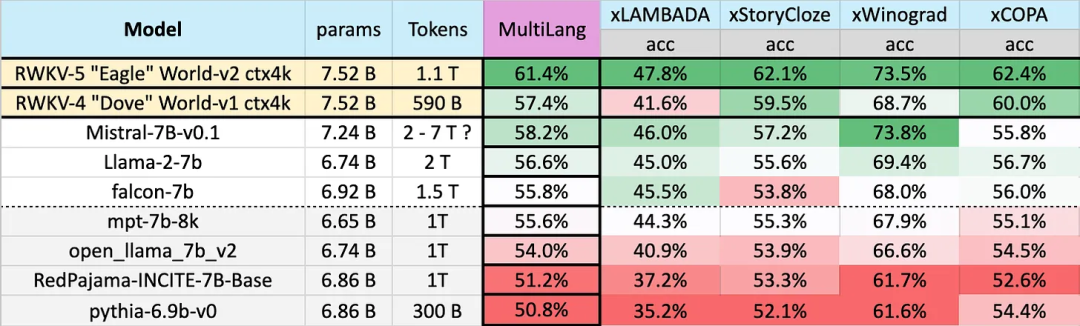
23 言語でのテスト結果
複数言語でのさまざまなモデルのパフォーマンスは次のとおりです。ベンチマークには、xLAMBDA、xStoryCloze、xWinograd、xCopa が含まれます。
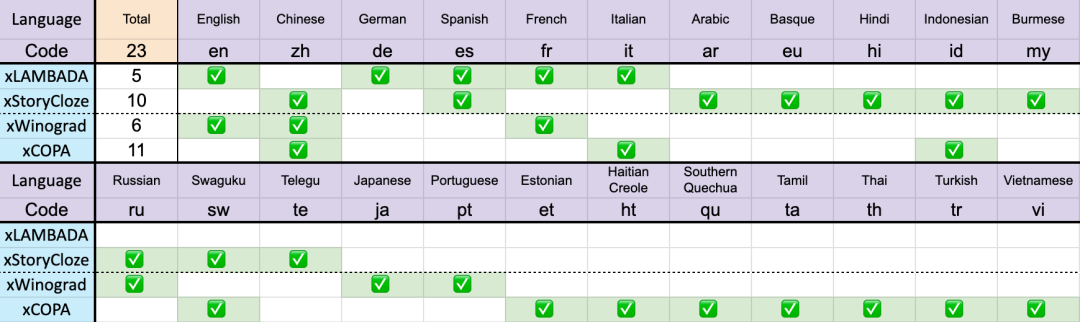 合計 23 言語
合計 23 言語
これらのベンチマークには、ほとんど常識的な推論が組み込まれており、v4 から v5 への RWKV アーキテクチャの多言語パフォーマンスの大幅な飛躍が示されています。ただし、多言語ベンチマークがないため、この研究では一般的に使用される 23 言語での能力しかテストできず、残りの 75 以上の言語での能力はまだ不明です。
英語でのパフォーマンス
英語でのさまざまなモデルのパフォーマンスは、常識的な推論を含む 12 のベンチマークを通じて判断されます。そして世界の知識。
 結果から、RWKV の v4 アーキテクチャから v5 アーキテクチャへの大きな飛躍が再びわかります。 v4 は以前は 1T トークン MPT-7b に負けていましたが、v5 はベンチマーク テストで追いつき始めており、場合によっては (LAMBADA、StoryCloze16、WinoGrande、HeadQA_en、Sciq の一部のベンチマーク テストでも) Falcon や llama2 を超えることもあります。
結果から、RWKV の v4 アーキテクチャから v5 アーキテクチャへの大きな飛躍が再びわかります。 v4 は以前は 1T トークン MPT-7b に負けていましたが、v5 はベンチマーク テストで追いつき始めており、場合によっては (LAMBADA、StoryCloze16、WinoGrande、HeadQA_en、Sciq の一部のベンチマーク テストでも) Falcon や llama2 を超えることもあります。
さらに、v5 のパフォーマンスは、おおよそのトークン トレーニング統計を考慮すると、予想される Transformer のパフォーマンス レベルと一致し始めます。
以前、ミストラル 7B は 7B スケール モデルでのリードを維持するために 2 ~ 7 兆トークンのトレーニング方法を使用していました。この研究では、このギャップを埋めて、RWKV-v5 Eagle 7B が llama2 のパフォーマンスを上回り、ミストラルのレベルに達することを期待しています。
次の図は、3,000 億トークン ポイント付近の RWKV-v5 Eagle 7B のチェックポイントが pythia-6.9b と同様のパフォーマンスを示していることを示しています。
##これは、RWKV-v4 アーキテクチャに関する以前の実験 (パイルベース) と一致しており、RWKV のような線形トランスフォーマーはパフォーマンス レベルがトランスフォーマーと同様であり、同じ数のトークンを持っています。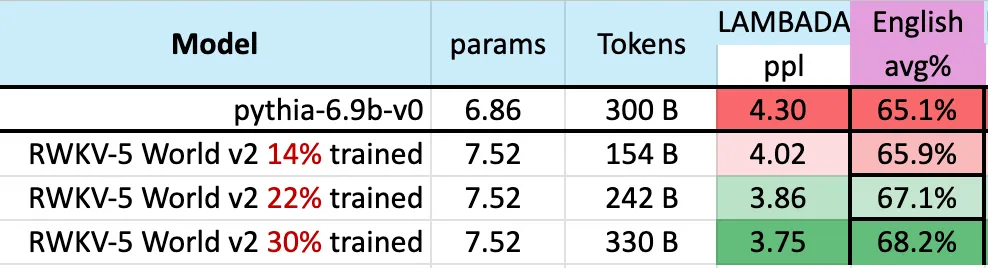
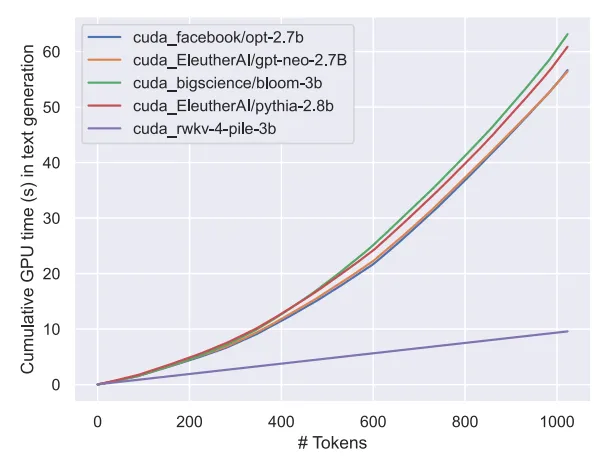
# 予想どおり、このモデルの登場は、(評価ベンチマークの観点から)これまでで最も強力なリニアトランスの登場を示しています。
以上がアテンションフリーの大型モデル Eagle7B: RWKV に基づいて、推論コストが 10 ~ 100 分の 1 に削減の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



