


機械学習はさまざまな分野で大きな成功を収めており、高品質な機械学習モデルが多数登場し続けています。しかし、一般のユーザーにとって、自分の業務に適したモデルを見つけることは簡単ではありません。ましてや、新しいモデルをゼロから構築することは簡単ではありません。この問題を解決するために、南京大学の周志華教授は「ラーニングウェア」と呼ばれるパラダイムを提案し、モデルと規制の考え方を通じて、ユーザーが学習できるようにするラーニングウェア市場(現在はラーニングウェアベースシステムと呼ばれています)が構築されました。 unify ニーズを満たすモデルを選択して導入します。現在、ラーニングウェア パラダイムは、Beimingwu という名前の最初のオープンソース基本プラットフォームを導入しました。このプラットフォームは、豊富なモデル ライブラリと展開ツールをユーザーに提供し、機械学習モデルの使用とカスタマイズをより簡単かつ効率的にできるようにします。 Beimingwu を通じて、ユーザーは機械学習の力をより効果的に活用して、さまざまな実際的な問題を解決できます。

古典的な機械学習パラダイムでは、高性能モデルをゼロからトレーニングするには、大量の高品質なデータ、専門家が必要です。経験とコンピューティング リソースが必要であり、時間とコストがかかる作業であることは間違いありません。また、既存モデルの再利用にはいくつかの問題もあります。たとえば、特定のトレーニング済みモデルをさまざまな環境に適応させることは困難であり、トレーニング済みモデルを徐々に改善している間に壊滅的な忘却が発生する可能性があります。したがって、これらの課題に対処するためのより効率的かつ柔軟な方法を見つける必要があります。
データのプライバシーと所有権の問題は、開発者間のエクスペリエンスの共有を妨げるだけでなく、データに敏感なシナリオに大規模なモデルを適用する能力を制限します。研究ではこれらの問題に焦点が当てられることがよくありますが、実際にはそれらは同時に発生し、相互に影響を与えることがよくあります。
自然言語処理とコンピュータ ビジョンの分野では、主流の大規模モデル開発パラダイムが目覚ましい成果を上げていますが、いくつかの重要な問題はまだ解決されていません。これらの問題には、無制限の計画外のタスクとシナリオ、環境の絶え間ない変化、壊滅的な忘れ、高いリソース要件、プライバシーへの懸念、ローカライズされた展開要件、パーソナライズとカスタマイズの要件が含まれます。したがって、潜在的なタスクごとに対応する大規模なモデルを構築することは、非現実的な解決策です。これらの課題に対処するには、より柔軟でカスタマイズ可能なモデル アーキテクチャを採用したり、さまざまなタスクや環境の変化に適応するために転移学習や増分学習などの手法を使用したりするなど、対処するための新しい方法や戦略を見つける必要があります。複数のアプローチと戦略を統合することによってのみ、これらの複雑な問題をより適切に解決できます。
機械学習のタスクを解決するために、南京大学の周志華教授は 2016 年にラーンウェアの概念を提案しました。ラーニングウェアをベースとした新たなパラダイムを創造し、その基本プラットフォームとしてラーニングウェアドックシステムを提案しました。このシステムの目標は、世界中の開発者によって提出された機械学習モデルに均一に対応し、モデル機能を使用して潜在的なユーザーのタスクのニーズに基づいて新しいタスクを解決することです。このイノベーションは、機械学習の分野に新たな可能性と機会をもたらします。
ラーニングウェア パラダイムの核となる設計は次のとおりです。さまざまなタスクからの高品質モデルにとって、ラーニングウェアは統一された形式を持つ基本ユニットです。ラーニングウェアは、モデル自体と、モデルの特性を何らかの表現で説明する仕様で構成されます。開発者はモデルを自由に提出でき、ラーニング ドック システムは仕様の生成を支援し、ラーニング ドックに学習ソフトウェアを保存します。このプロセスでは、開発者はトレーニング データをラーニング ドックに開示する必要はありません。将来的には、ユーザーはラーニングウェア システムに自分のデータを漏らすことなく、ラーニングウェア ベース システムに要件を送信し、ラーニングウェアを見つけて再利用することで独自の機械学習タスクを解決できるようになります。この設計により、モデルの共有とタスク解決がより効率的、便利になり、プライバシーも安全になります。
学習ウェア パラダイムのための予備的な科学研究プラットフォームを確立するために、周志華教授のチームは最近、将来の学習ウェア パラダイム研究のための初のオープンソース学習プラットフォームである Beimingwu を構築しました。パーツ ベース システム 。関連する論文は出版されており、長さは 37 ページです。
技術レベルでは、Beimingwu システムは、スケーラブルなシステムとエンジン アーキテクチャの設計、および広範なエンジニアリングの実装と最適化を通じて、将来の学術ソフトウェア関連のアルゴリズムとシステム研究の基礎を築きました。さらに、システムは全プロセスのベースライン アルゴリズムも統合し、基本的なアルゴリズム評価シナリオを構築します。これらの機能により、システムは学習ウェアのサポートを提供できるだけでなく、多数の学習ウェアをホストし、学習ウェアのエコシステムを確立する可能性も提供します。

論文のタイトル: Beimingwu: A Learnware Dock System
論文のアドレス: https://arxiv .org/pdf/2401.14427.pdf
北明呉ホームページ: https://bmwu.cloud/
北明呉オープンソース ウェアハウス :https: //www.gitlink.org.cn/beimingwu/beimingwu
コア エンジン オープン ソース ウェアハウス: https://www.gitlink.org.cn/beimingwu/learnware
ラーニングウェア パラダイムに基づいて、ユーザーが新しいタスクを解決するためのモデル開発を簡素化します。データ効率が達成され、専門知識は必要なく、元のデータは漏洩しません。
完全で統合されたスケーラブルなシステム エンジン アーキテクチャ設計を提案;
統合されたユーザー インターフェイスを備えたオープンソースの学習ソフトウェア ベース システムを開発;
フルプロセスのベースライン アルゴリズムの実装とさまざまなシナリオの評価。
ラーンウェア パラダイムの概要
ラーンウェア パラダイムは、2016 年に Zhou Zhihua 教授のチームによって提案され、2024 年の論文「Learnware: small 「model do big」で要約し、さらにデザインを進めます。このパラダイムの簡略化されたプロセスを以下の図 1 に示します。 あらゆる種類と構造の高品質な機械学習モデルの場合、その開発者または所有者は、トレーニングされたモデルを自発的に学習ベース システム (以前は学習ベース システムと呼ばれていました) に送信できます。 .パーツマーケット)。
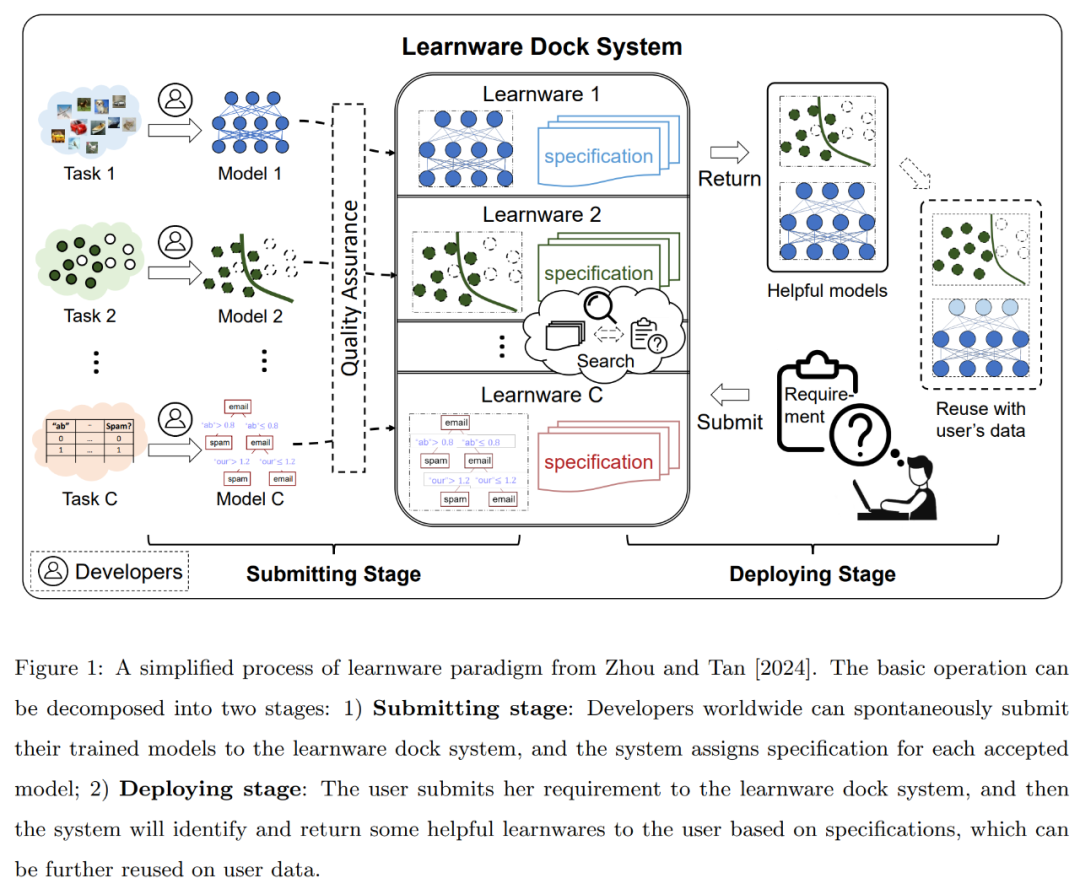
上で紹介したように、ラーニングウェア パラダイムは、優れたパフォーマンスを持つ既存のモデルを均一に収容、整理、利用して、すべてのユーザーの努力を均一に活用するためのラーニングウェア ベース システムを確立することを提案しています。新しいユーザータスクを解決するためのコミュニティは、トレーニングデータとトレーニングスキルの不足、壊滅的な忘却、継続的な学習の達成の難しさ、データのプライバシーまたは所有権化、オープン性などの主要な懸案問題のいくつかにも対処する可能性があります。無駄なトレーニングの繰り返しによる二酸化炭素排出量など
最近、ラーニングウェア パラダイムとその中心となるアイデアがますます注目を集めています。しかし、重要な質問であり、主な課題は次のとおりです。学習ベース システムが数千、さらには数百万のモデルに対応できることを考慮すると、新しいユーザーのタスクに最も役立つ学習ピースまたは学習ピースのセットをどのように特定して選択するか?明らかに、実験のためにユーザー データをシステムに直接送信するとコストがかかり、ユーザーの元のデータが公開されてしまいます。
学習ソフトウェア パラダイムの核となる設計はプロトコルにあり、最近の研究は主に Reduced kernel Mean Embedding (RKME) プロトコルに基づいています。
既存の理論的および実証的な分析と研究により、プロトコルベースのラーニングウェア識別の有効性が証明されていますが、ラーニングウェアベースシステムの実装は依然として不足しており、新しいプロトコルベースのアーキテクチャが必要という大きな課題に直面しています。現実世界の多様なタスクとモデルに対応し、ユーザーのタスク要件に応じて多数の学習教材を均一に検索して再利用します。
研究者らは、提出、ユーザビリティ テスト、組織、管理、識別、導入、学習ウェアの再利用を含むプロセス全体のサポートを提供する最初の学習ウェア ベース システムである Beimingwu を構築しました。
Beimingwu を使用して学習タスクを解決する
学習ウェア パラダイムに基づいた最初のシステム実装である Beimingwu は、新しいタスクの機械学習モデルを構築するプロセスを大幅に簡素化します。これで、ラーニングウェア パラダイムのプロセスに従ってモデルを構築できます。また、統合学習ソフトウェア構造、統合アーキテクチャ設計、統合ユーザー インターフェイスの恩恵を受けて、北明武で提出されたすべてのモデルは統合された識別と再利用を実現します。
興味深いのは、新しいユーザー タスクが与えられたときに、このタスクを解決できる学習ソフトウェアが Beimingwu にあれば、ユーザーはわずか数行のコードでそれを簡単に入手して導入できることです。大量のデータと専門知識が必要ですが、独自の生データを漏洩しません。
以下の図 2 は、Beimingwu を使用して学習タスクを解決するコード例です。

以下の図 3 は、統計プロトコルの生成、学習ソフトウェアの識別、読み込みと再利用を含む、Beimingwu を使用するワークフロー全体を示しています。エンジニアリング実装と統一インターフェイス設計に基づいて、各ステップは一連のキーコードを通じて実現できます。

研究者らは、学習タスクを解決する際に、Beimingwu に基づく学習ソフトウェア パラダイムを使用したモデル開発プロセスには次のような大きな利点があると述べています。
大量のデータやコンピューティング リソースは必要ありません。
# 大量の機械学習の専門知識は必要ありません。
多様なモデルは統一されたシンプルなローカル展開を提供します;
プライバシー保護: ユーザーの元のデータを漏洩しません。
現在、Beimingwu には、初期段階のオープンソース データセットに基づいて構築された 1,100 の学習ツールしかありません。多くのシナリオをカバーしているわけではなく、多数の特定の目に見えないシナリオを処理する能力はありません。シナリオはまだ限られています。スケーラブルなアーキテクチャ設計に基づいて、Beimingwu はラーニングウェア パラダイムの研究プラットフォームとして使用でき、ラーニングウェア関連の研究に便利なアルゴリズム実装と実験設計を提供します。
同時に、基本的な実装とスケーラブルなアーキテクチャのサポートに依存し、継続的に提出される学習教材と継続的に改善されたアルゴリズムにより、システムのタスク解決能力が強化され、既存の十分にトレーニングされたモデルのシステムの再利用が強化されます。開発者の当初の目標を超えて、新しいタスクを解決する能力。将来的には、学習ウェアのベース システムが継続的に進化することで、壊滅的な忘れを起こすことなく、増加するユーザー タスクに対応できるようになり、自然に生涯学習が可能になるでしょう。
Beimingwu の設計
この文書のセクション 4 では、Beimingwu システムの設計について説明します。図 4 に示すように、システム全体には、学習ソフトウェア ストレージ、システム エンジン、システム バックグラウンド、およびユーザー インターフェイスの 4 つのレベルが含まれています。このセクションでは、最初に各層の概要を紹介し、次にプロトコル設計に基づいてシステムのコア エンジンを紹介し、最後にシステムに実装されているアルゴリズムを紹介します。
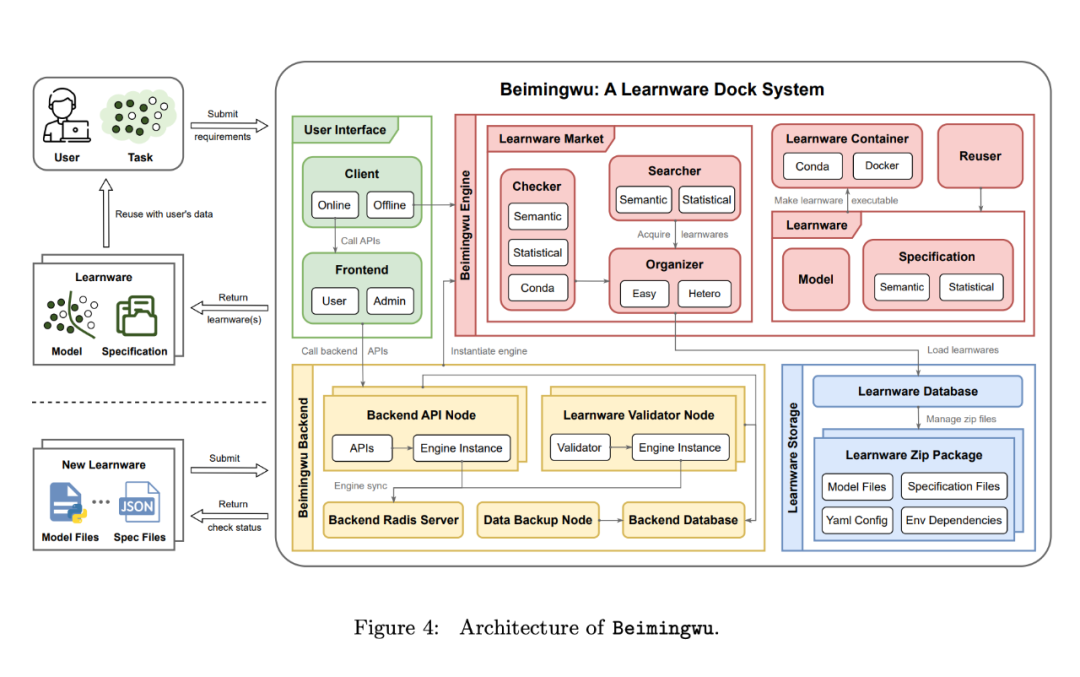
まず、各レイヤーの概要を確認します:
ラーニングウェア ストレージ レイヤー。 Beimingwu では、学習教材は圧縮パッケージに保存されています。これらの圧縮パッケージには、主にモデルファイル、仕様ファイル、モデル実行環境依存関係ファイル、学習ソフトウェア構成ファイルの 4 種類のファイルが含まれています。
これらの学習ウェア圧縮パッケージは、学習ウェア データベースによって集中管理されます。データベース内の学習項目テーブルには、学習項目 ID、保存パス、学習項目のステータス (未検証、検証済みなど) などの主要な情報が格納されます。このデータベースは、Beimingwu の後続のコア エンジンが学習情報にアクセスするための統合インターフェイスを提供します。
さらに、データベースは SQLite (開発環境や実験環境での簡単なセットアップに適しています) または PostgreSQL (運用環境での安定した展開に推奨) を使用して構築でき、どちらも同じインターフェイスを使用します。
コア エンジン レイヤー。 Beimingwu のシンプルさと構造を維持するために、著者らはコア コンポーネントとアルゴリズムを多数のエンジニアリングの詳細から分離しました。これらの抽出されたコンポーネントは、Beimingwu のコア エンジンである学習ソフトウェア Python パッケージとして使用できるようになります。
このエンジンはシステムの中核として、学習ウェアの提出、ユーザビリティ テスト、編成、識別、展開、再利用など、学習ウェア パラダイムのすべてのプロセスをカバーします。バックグラウンドとフォアグラウンドとは独立して実行され、ソフトウェア関連のタスクや研究実験を学習するための包括的なアルゴリズム インターフェイスを提供します。
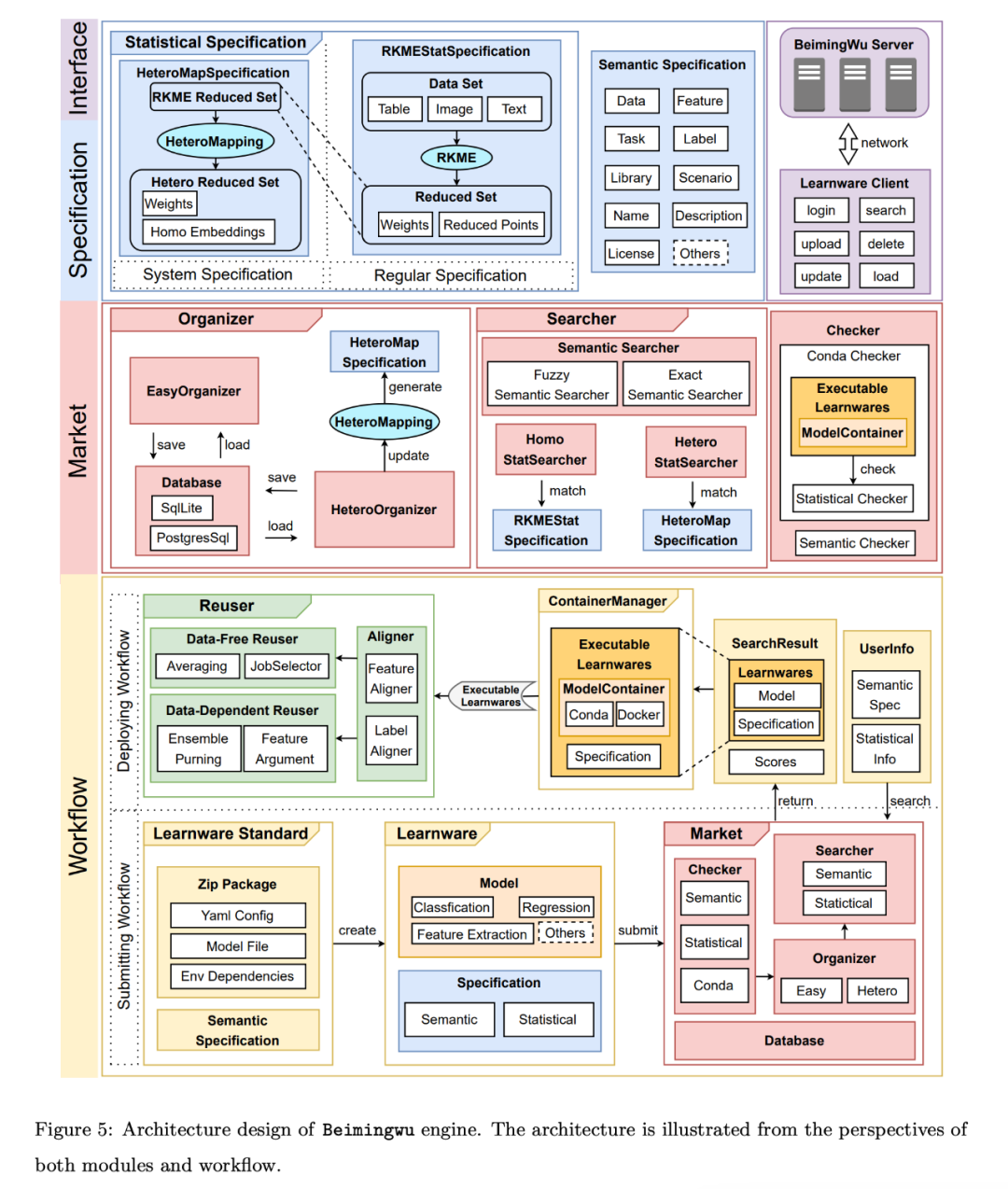
さらに、仕様はエンジンの中核コンポーネントであり、意味論的および統計的な観点から各モデルを表し、学習ソフトウェア システム内のさまざまな重要なコンポーネントを接続します。開発者がモデルを送信するときに生成される仕様に加え、エンジンはシステム知識を使用して学習ソフトウェアの新しいシステム仕様を生成することもできるため、学習ソフトウェアの管理が強化され、その機能がさらに特徴付けられます。
Hugging Face などの既存のモデル管理プラットフォームは受動的にモデルを収集してホストするだけで、ユーザーがモデルの機能とタスクとの関連性を判断できるのとは対照的に、Beimingwu はそのエンジンを使用して学習教材を能動的に管理します。新しいシステムアーキテクチャを採用。このアクティブな管理は収集と保管に限定されず、システムはプロトコルに従って学習教材を整理し、ユーザーのタスク要件に応じて関連する学習教材を照合し、対応する学習ソフトウェアの再利用および展開方法を提供します。
コア モジュールの設計は次のとおりです:
システム バックエンド層。 Beimingwu の安定した展開を実現するために、著者はコア エンジン層に基づいてシステム バックエンドを開発しました。複数のモジュールの設計と大量のエンジニアリング開発を通じて、Beimingwu はオンラインで安定して展開できるようになり、フロントエンドとクライアントに統合されたバックエンド アプリケーション プログラム インターフェイスを提供できるようになりました。
システムの効率的かつ安定した動作を確保するために、著者は、非同期学習ソフトウェアの検証、複数のバックエンド ノードにわたる高い同時実行性、インターフェイス レベルなど、システムのバックエンド層で多くのエンジニアリングの最適化を実行しました。権限管理、バックエンドデータベースの読み書き、システムデータの分離と自動バックアップ。
ユーザー インターフェイス層。 Beimingwu ユーザーの使用を容易にするために、著者は、ネットワーク ベースのブラウザ フロントエンドとコマンド ライン クライアントを含む、対応するユーザー インターフェイス層を開発しました。
Web ベースのフロントエンドにはユーザー バージョンと管理者バージョンの両方があり、さまざまなユーザー インタラクションとシステム管理ページが提供されます。さらに、Beimingwu システムへのスムーズなアクセスのためのマルチノード展開もサポートしています。
コマンド ライン クライアントは、ラーニングウェアの Python パッケージと統合されています。対応するインターフェイスを呼び出すことで、ユーザーはフロントエンド経由でバックエンド オンライン API を呼び出し、学習ソフトウェアの関連モジュールとアルゴリズムにアクセスできます。
実験評価
セクション 5 では、著者はテーブル、画像、テキスト データに対する仕様生成を評価するためのさまざまな種類の基本的な実験シナリオ、学習用のベンチマーク アルゴリズムを構築します。ピースの識別と再利用。
表形式データの実験
さまざまな表形式データ セットで、著者は最初に、ユーザー タスクと同じ特徴空間を持つ学習ソフトウェア システムの識別と再利用を評価しました。学習ソフトの性能。さらに、表形式のタスクは通常、異なる特徴空間から得られるため、著者らは、異なる特徴空間からの学習アーティファクトの特定と再利用も評価しました。
同種のケース
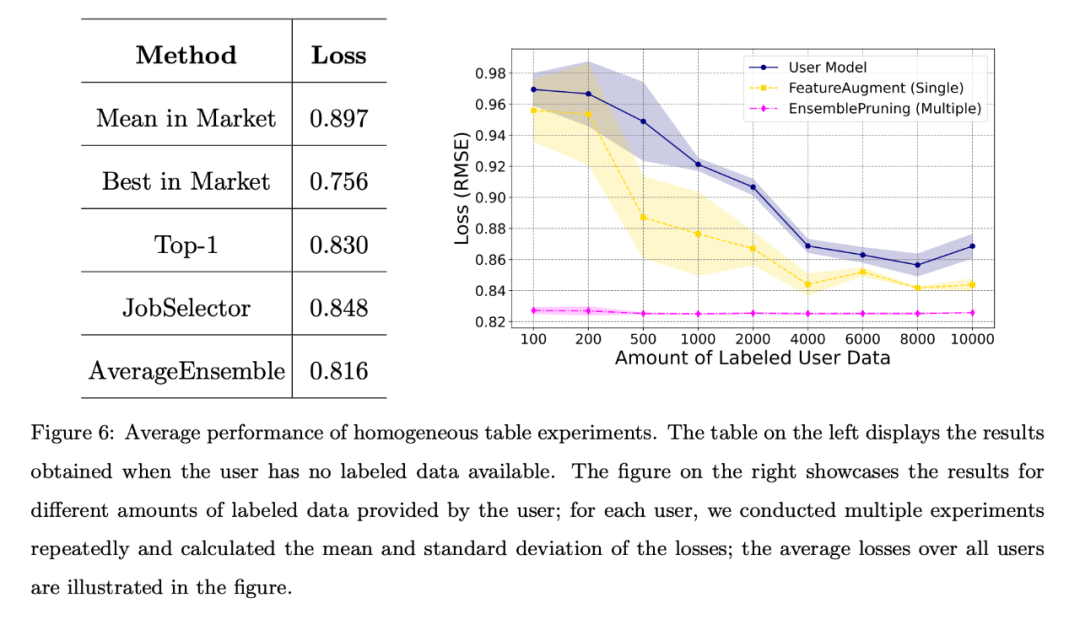
同種のケースでは、PFS データセット内の 53 のストアが 53 の独立したユーザーとして機能します。各ストアは独自のテスト データをユーザー タスク データとして利用し、統一された特徴量エンジニアリング アプローチを採用しています。これらのユーザーは、タスクと同じ特徴空間を共有する同種の学習項目をベース システムで検索できます。
ユーザーがラベル付きデータを持たないか、ラベル付きデータの量が限られている場合、著者はさまざまなベースライン アルゴリズムを比較しました。その結果、全ユーザーの平均損失が図 6 に示されています。左の表は、市場から学習ウェアをランダムに選択して導入するよりも、データフリーのアプローチの方がはるかに優れていることを示しています。右のグラフは、ユーザーのトレーニング データが限られている場合、単一または複数の学習ウェアを特定して再利用する方が、ユーザーがトレーニングしたものよりも優れていることを示しています。モデルのパフォーマンスが向上しました。
異種のケース
市場のソフトウェアとユーザーのタスクの類似性に応じて、異種のケースはさらに異なる機能エンジニアリングと異なるタスクのシーンに分類できます。 。
さまざまな特徴量エンジニアリング シナリオ: 図 7 の左側に示されている結果は、ユーザーにアノテーション データが不足している場合でも、システム内の学習ソフトウェア、特に複数の学習ソフトウェア手法を再利用する AverageEnsemble が強力なパフォーマンスを発揮できることを示しています。 。
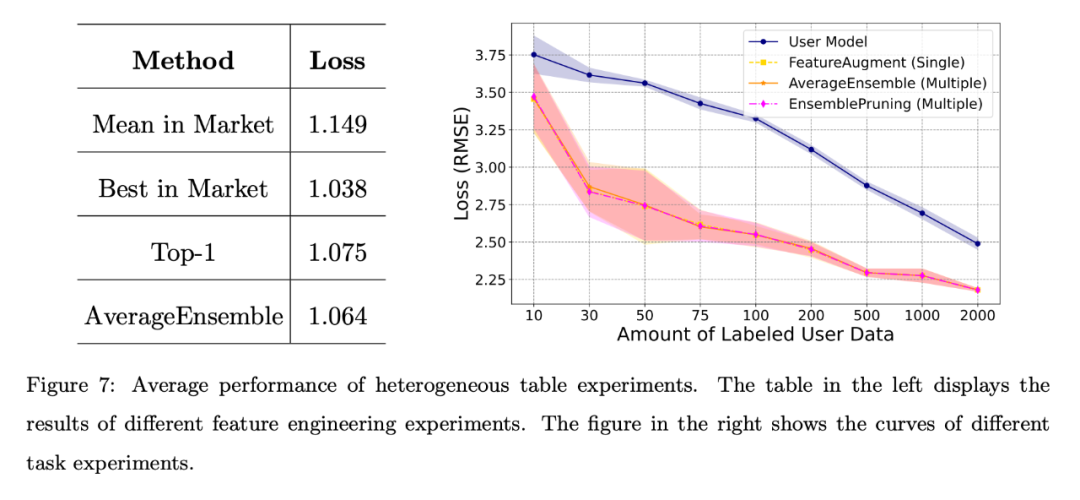
さまざまなミッションシナリオ。図 7 の右側は、ユーザーが自己学習したモデルといくつかの学習ウェア再利用手法の損失曲線を示しています。明らかに、異種学習コンポーネントの実験的検証は、ユーザーの注釈付きデータの量が限られている場合に有益であり、ユーザーの特徴空間との整合性を高めるのに役立ちます。
画像およびテキスト データの実験
さらに、著者は画像データ セットに対するシステムの基本的な評価を実行しました。
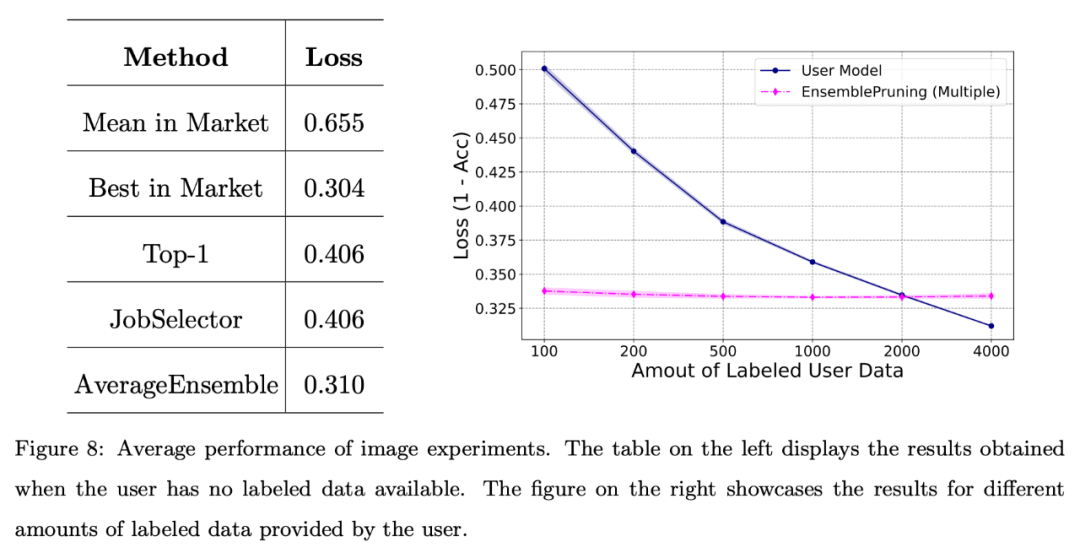
図 8 は、ユーザーが注釈付きデータの不足に直面している場合、または限られた量のデータしか持っていない場合 (インスタンスが 2000 未満) に、学習ベース システムを活用すると良好なパフォーマンスが得られることを示しています。
#最後に、著者はベンチマーク テキスト データ セットでシステムの基本評価を実行します。統合された特徴抽出機能による特徴空間の調整。
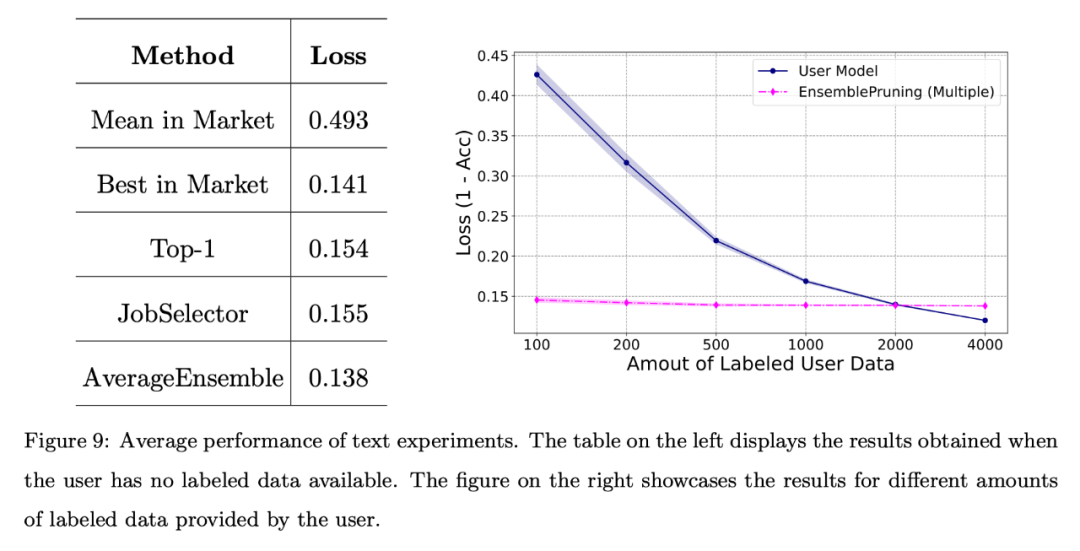
結果を図 9 に示します。同様に、注釈データが提供されない場合でも、学習ウェアの識別と再利用によって達成されるパフォーマンスは、システム内の最高の学習ウェアと同等です。さらに、学習ベース システムを活用すると、モデルを最初からトレーニングする場合と比較してサンプルが約 2,000 少なくなります。
研究の詳細については、元の論文を参照してください。
以上がビッグモデルの時代に、NTU 周志華氏はソフトウェアの研究に没頭しており、彼の最新論文がオンラインで公開されていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



