


GPT-4 の伝説的な「魔法の武器」である MoE (Mixed Expert) アーキテクチャは、自分でも使用できます。
Hugging Face には、完全な MoE システムをゼロから構築する方法を共有した機械学習の第一人者がいます。

このプロジェクトは著者によって MakeMoE と呼ばれており、アテンションの構築から完全な MoE モデルの形成までのプロセスを詳しく説明します。
著者によると、MakeMoE は OpenAI 創設メンバーである Andrej Karpathy の Makemore にインスピレーションを受け、それに基づいています。
makemore は、自然言語処理と機械学習の教育プロジェクトであり、学習者がいくつかの基本モデルを理解し、実装できるようにすることを目的としています。
同様に、MakeMoE は、学習者が段階的な構築プロセスでハイブリッド エキスパート モデルをより深く理解するのにも役立ちます。
それでは、この「手もみガイド」では具体的にどのようなことが書かれているのでしょうか?
Karpathy の makemore と比較すると、MakeMoE は、孤立したフィードフォワード ニューラル ネットワークを専門家のまばらな混合物に置き換えると同時に、必要なゲート ロジックを追加します。
同時に、プロセス内で ReLU アクティベーション関数を使用する必要があるため、makemore のデフォルトの初期化メソッドは Kaiming He メソッドに置き換えられます。

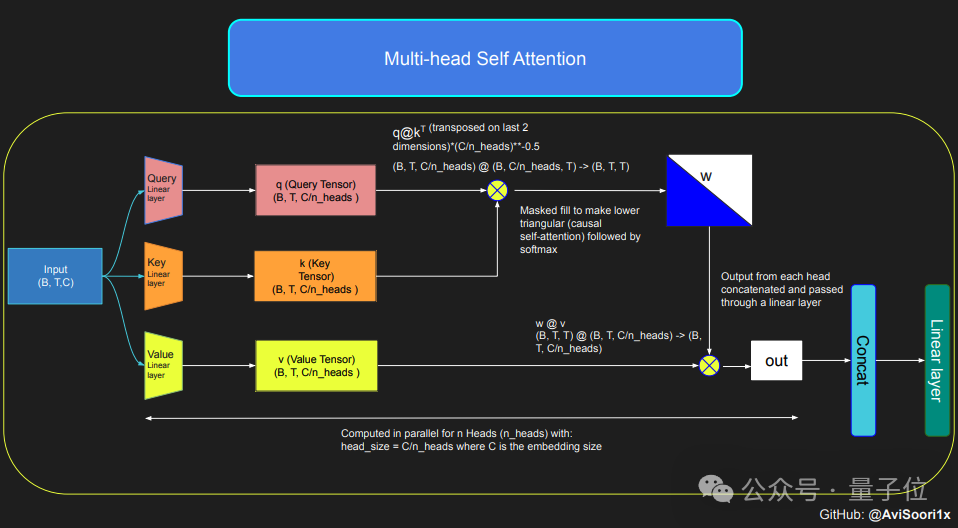
MoE モデルを作成したい場合は、まず自己注意のメカニズムを理解する必要があります。
モデルはまず、線形変換を通じて入力シーケンスをクエリ (Q)、キー (K)、および値 (V) で表されるパラメーターに変換します。
これらのパラメーターは、各トークンを生成するときにモデルがシーケンス内の各位置にどれだけの注意を払うかを決定する注意スコアを計算するために使用されます。
テキスト生成時のモデルの自己回帰特性を確実にするため、つまり、すでに生成されたトークンに基づいて次のトークンのみを予測できるようにするために、作成者は マルチヘッド因果自己注目のマシンメカニズム。
このメカニズムは、マスクを使用して未処理の位置の注意スコアを負の無限大に設定し、これらの位置の重みがゼロになるようにします。
マルチヘッド因果関係により、モデルは、各ヘッドがシーケンスの異なる部分に焦点を当てながら、このような注意計算を複数並行して実行できます。
セルフアテンション メカニズムの構成が完了したら、エキスパート モジュールを作成できます。ここでの「エキスパート モジュール」は、多層パーセプトロンです。
各エキスパート モジュールには、非線形活性化関数 (ReLU など) を介して埋め込みベクトルをより大きな次元にマッピングする線形層と、ベクトルを元の埋め込み次元にマッピングし直す別の線形層が含まれています。 。
この設計により、各エキスパートは入力シーケンスのさまざまな部分の処理に集中できるようになり、ゲート ネットワークを使用して各トークンの生成時にどのエキスパートをアクティブにするかを決定できます。
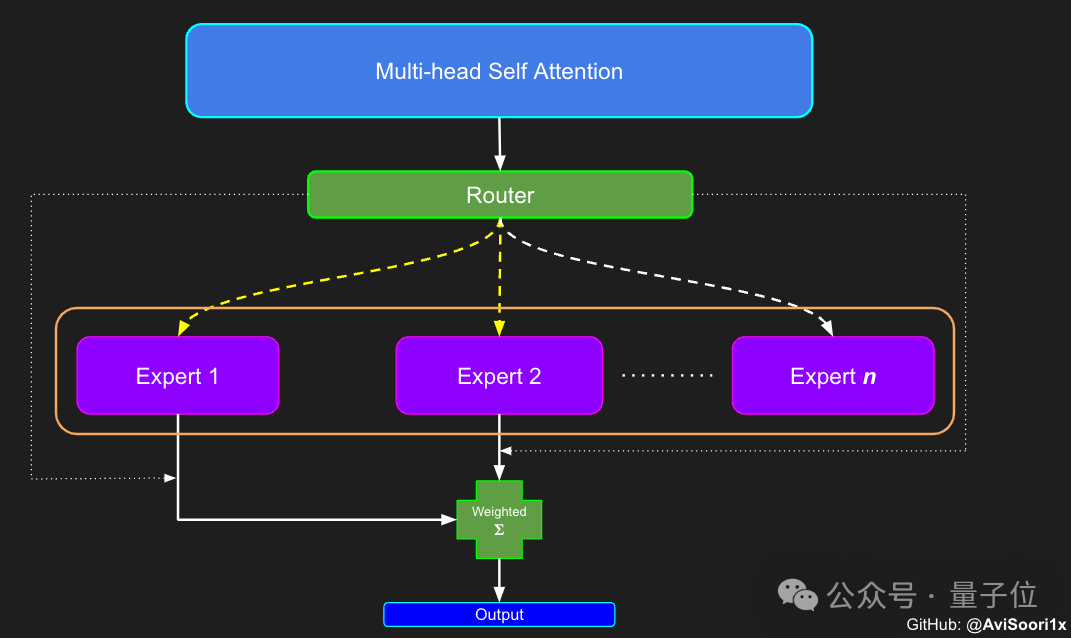
#したがって、次のステップは、専門家の配置と管理のためのコンポーネントであるゲート制御ネットワークの構築を開始することです。
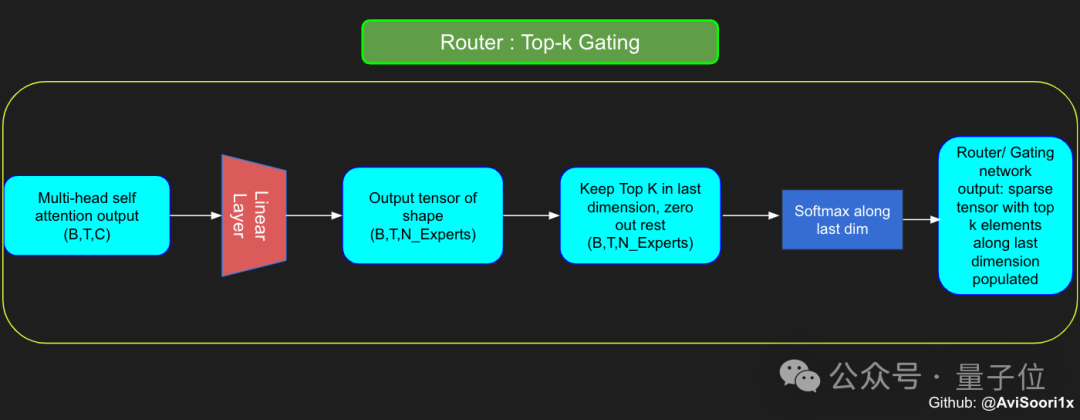
ここでのゲート ネットワークも線形層を通じて実装されており、セルフ アテンション層の出力をエキスパート モジュールの数にマッピングします。
この線形層の出力はスコア ベクトルであり、各スコアは現在処理されているトークンに対する対応するエキスパート モジュールの重要性を表します。
ゲート ネットワークは、このスコア ベクトルの上位 k の値を計算してそのインデックスを記録し、その中から上位 k の最大スコアを選択して、対応するエキスパート モジュールの出力に重みを付けます。
トレーニング プロセス中のモデルの探索性を高めるために、作成者はすべてのトークンが同じ専門家によって処理される傾向を避けるためにノイズも導入しました。
このノイズは通常、ランダムなガウス ノイズを分数ベクトルに追加することによって実現されます。
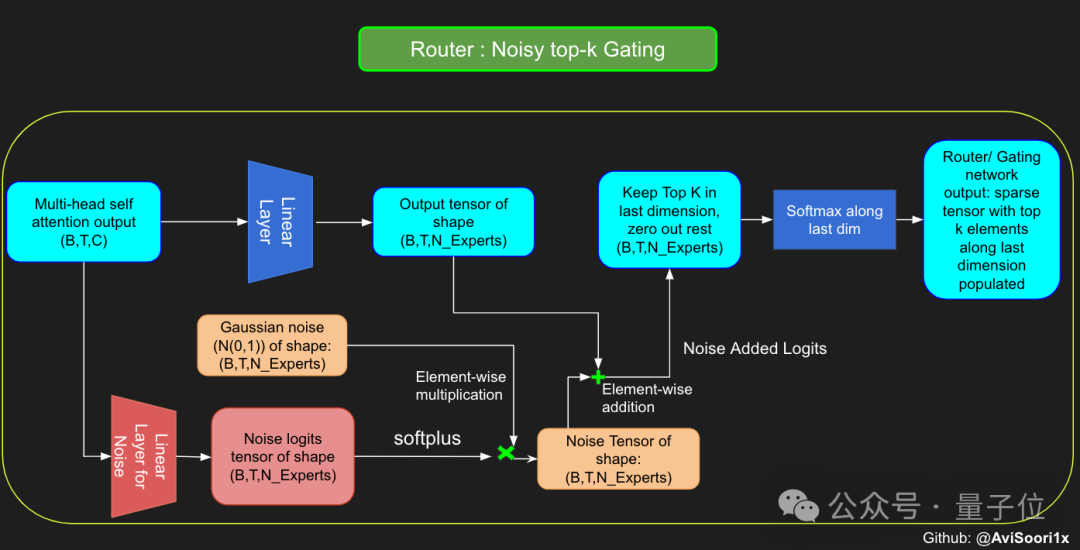
結果を取得した後、モデルは最初の k 値と、対応するトークンの上位 k 人のエキスパートの出力を選択的に乗算し、それらを加算して、モデル出力を形成するための加重合計。
最後に、これらのモジュールを組み合わせて MoE モデルを作成します。
上記のプロセス全体について、作成者は対応するコードを提供しています。詳細については、元の記事で学ぶことができます。
さらに、著者は各モジュールの学習中に直接実行できるエンドツーエンドの Jupyter ノートも作成しました。
興味があるなら、すぐに学びましょう!
元のアドレス: https://huggingface.co/blog/AviSoori1x/makemoe-from-scratch
ノート バージョン (GitHub): https://github. com/AviSoori1x/makeMoE/tree/main
以上がMoE 大規模モデル作成ガイド: ゼロベースの手動構築方法、マスターレベルのチュートリアルが公開の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



