


マルチモーダル大規模モデル (LMM) が進歩し続けるにつれて、LMM のパフォーマンスを評価する必要性も高まっています。特に中国語環境では、LMM の高度な知識と推論能力を評価することがより重要になります。
これに関連して、中国語のさまざまなタスクにおける基本モデルの専門家レベルのマルチモーダル理解能力を評価するために、香港科学大学 M-A-P オープンソース コミュニティウォータールー大学とテクノロジー、および Zero-One Everything は共同で CMMMU (中国の大規模多分野、多峰性の理解と推論) ベンチマークを開始しました。このベンチマークは、中国語での大規模な多分野のマルチモーダルな理解と推論のための包括的な評価プラットフォームを提供することを目的としています。このベンチマークを使用すると、研究者はさまざまなタスクでモデルをテストし、マルチモーダルな理解能力を専門レベルと比較できます。この共同プロジェクトの目標は、中国語の多様な理解と推論の分野の発展を促進し、関連研究に標準化された参考資料を提供することです。
CMMMU は、芸術、ビジネス、健康と医学、科学、人文社会科学、テクノロジーとエンジニアリングを含む 6 つの主要カテゴリの科目をカバーしており、30 以上の下位分野の科目が含まれています。下図はサブ分野科目ごとの出題例を示しています。 CMMMU は、中国の文脈における最初のマルチモーダル ベンチマークの 1 つであり、LMM の複雑な理解と推論能力を検査する数少ないマルチモーダル ベンチマークの 1 つです。

##データ収集##データ収集は 3 つの段階に分かれています。まず、研究者らは、Web ページや書籍など、著作権ライセンス要件を満たす各主題の問題ソースを収集しました。このプロセスでは、データの多様性と正確性を確保するために、質問ソースの重複を避けるために懸命に取り組みました。 次に、研究者らは、さらなるアノテーションを得るために質問ソースをクラウドソーシングのアノテーターに転送しました。すべてのアノテーターは学士以上の学位を持った個人であり、注釈付きの質問と関連する説明を確実に検証できます。アノテーションのプロセス中、研究者はアノテーターにアノテーションの原則に厳密に従うことを要求します。たとえば、回答に画像を必要としない質問を除外し、可能な限り同じ画像を使用する質問を除外し、回答に専門知識を必要としない質問を除外します。 最後に、データセット内の各被験者の質問数のバランスをとるために、研究者は特に被験者の質問数を減らしました。そうすることで、データセットの完全性と代表性が保証され、その後の分析と研究がより正確かつ包括的に行われるようになります。
データセットのクリーニング
CMMMU のデータ品質をさらに向上させるために、研究者は厳格なデータ品質管理プロトコルに従います。 。まず、各質問は論文の著者の少なくとも 1 人によって個人的に検証されます。次に、データ汚染の問題を回避するために、いくつかの LLM が OCR テクノロジーに頼らずに回答できる質問も選別しました。これらの対策により、CMMMU データの信頼性と正確性が保証されます。
データセットの概要
CMMMU には合計 12,000 の質問があり、少数のサンプルの開発セットに分割されています。検証セットとテストセット。少数サンプルの開発セットには各科目につき約 5 つの質問が含まれ、検証セットには 900 の質問が含まれ、テスト セットには 11,000 の質問が含まれます。問題は病理図、楽譜図、回路図、化学構造図など39種類の絵から出題されます。問題は、知的難易度ではなく論理的な難易度に基づいて、簡単 (30%)、中級 (58%)、難しい (12%) の 3 つの難易度に分かれています。質問の統計の詳細については、表 2 と表 3 を参照してください。 #######################################実験########## ##チームは、主流のさまざまな中国語と英語のバイリンガル LMM と、CMMMU 上のいくつかの LLM のパフォーマンスをテストしました。クローズド ソース モデルとオープン ソース モデルの両方が含まれます。評価プロセスでは、微調整または少数ショット設定の代わりにゼロショット設定を使用して、モデルの生の機能をチェックします。 LLM は、画像 OCR 結果のテキストを入力として使用する実験も追加しました。すべての実験は、NVIDIA A100 グラフィックス プロセッサで実行されました。
#主な結果
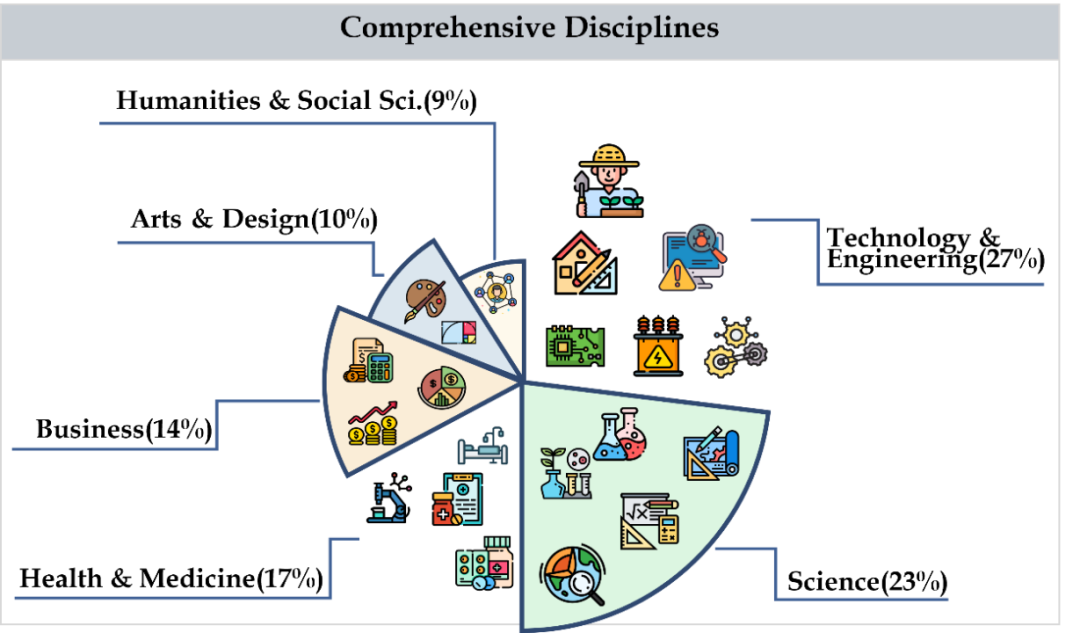
表 4 に実験結果を示します。
いくつかの重要な発見は次のとおりです:
-CMMMU は MMMU よりも困難であり、これは MMMU が非常に優れている場合です。挑戦的な前提。
中国語のコンテキストにおける GPT-4V の精度はわずか 41.7% ですが、英語のコンテキストにおける精度は 55.7% です。これは、既存の言語間汎化手法が、最先端のクローズドソース LMM にとっても十分ではないことを示しています。
#- MMMU と比較すると、国内の代表的なオープンソース モデルと GPT-4V の差は比較的小さいです。
MMMU 上の Qwen-VL-Chat と GPT-4V の差は 13.3% ですが、MMMU 上の BLIP2-FLAN-T5-XXL と GPT-4V の差は 13.3% です。は21.9%です。驚くべきことに、Yi-VL-34B は、CMMMU 上のオープンソース バイリンガル LMM と GPT-4V の間のギャップを 7.5% まで狭めます。これは、中国環境では、オープンソース バイリンガル LMM が GPT-4V と同等であることを意味します。これは、オープンソース コミュニティにおける有望な開発です。
# - オープンソース コミュニティでは、中国の専門家向けのマルチモーダル汎用人工知能 (AGI) を追求する取り組みが始まったばかりです。
チームは、最近リリースされた Qwen-VL-Chat、Yi-VL-6B、Yi-VL-34B を除き、すべてオープンソースのバイリンガル LMM であると指摘しました。コミュニティは、CMMMU の頻繁な選択に匹敵する精度しか達成できません。
#さまざまな質問の難易度と質問の種類の分析
- さまざまな質問の種類
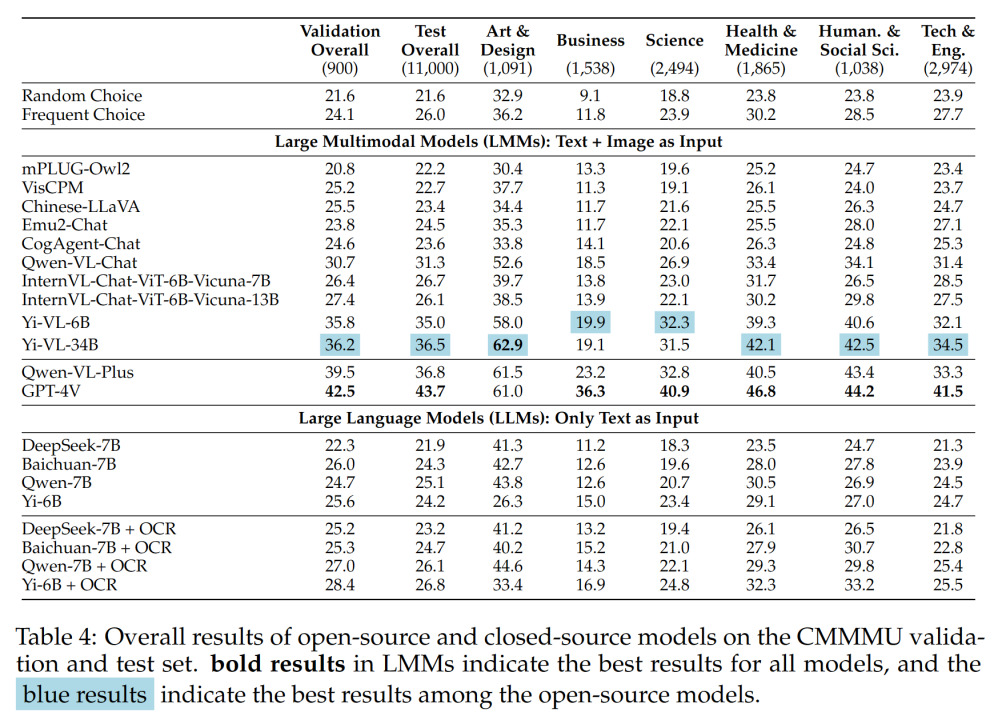
Yi-VL シリーズ、Qwen-VL-Plus、GPT-4V の違いは主に、多肢選択式の質問に答える能力の違いによるものです。#さまざまな質問タイプの結果を表 5 に示します。
 #- 異なる質問の難易度
#- 異なる質問の難易度
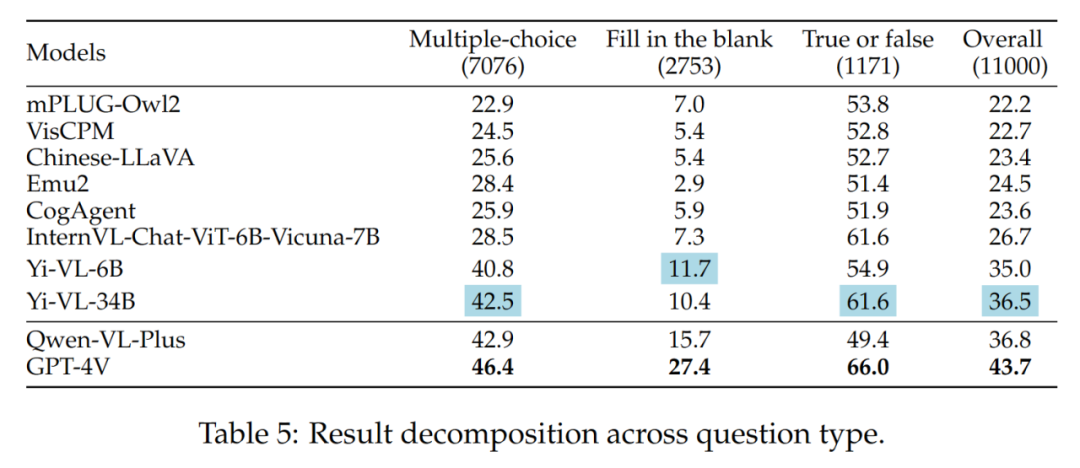
結果で注目に値するのは、中程度の問題や難しい問題に直面した場合に最適なオープンソース LMM (つまり Yi-VL-34B) と GPT-4V が存在するということです。さらに大きなギャップ。これは、オープンソース LMM と GPT-4V の主な違いが、複雑な条件下での計算と推論の能力であるという強力な証拠です。
さまざまな問題の難易度の結果を表 6 に示します。
 エラー分析
エラー分析
##研究者たちは、GPT-4V の誤った回答を注意深く分析しました。以下の図に示すように、主なエラーの種類は、認識エラー、知識不足、推論エラー、回答拒否、注釈エラーです。これらのエラー タイプを分析することは、現在の LMM の機能と制限を理解するための鍵であり、将来の設計とトレーニング モデルの改善の指針にもなります。
- 認識されたエラー (26%): 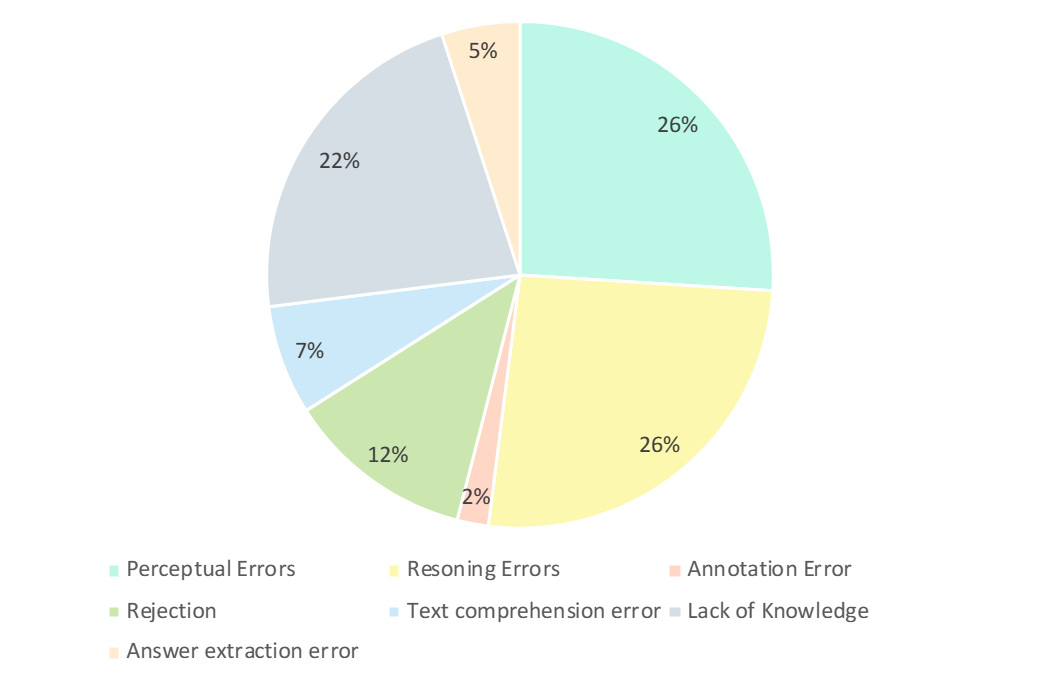
認識されたエラーは、生成されたエラーの例ですby GPT-4V 主な理由の 1 つ。一方で、モデルが画像を理解できない場合、画像の根底にある認識にバイアスが生じ、誤った応答につながります。一方、モデルがドメイン固有の知識、暗黙の意味、または不明瞭な式のあいまいさに遭遇すると、ドメイン固有の知覚エラーが発生することがよくあります。この場合、GPT-4V はテキスト情報ベースの回答 (質問や選択肢など) に依存する傾向があり、視覚的な入力よりもテキスト情報を優先するため、マルチモーダル データの理解に偏りが生じます。 - 推論エラー (26%) :
推論エラーは、GPT-4V が誤った例を生成するもう 1 つの主要な要因です。モデルが画像やテキストによって伝えられる意味を正しく認識したとしても、複雑な論理的および数学的推論が必要な問題を解決する際の推論中にエラーが発生する可能性があります。通常、このエラーは、モデルの論理的および数学的推論能力が弱いことが原因で発生します。 - 知識の欠如 (22%): 専門知識の欠如も、GPT-4V に対する不正解の理由の 1 つです。 CMMMU は LMM エキスパート AGI を評価するためのベンチマークであるため、さまざまな分野やサブフィールドにおける専門家レベルの知識が必要です。したがって、LMM に専門家レベルの知識を注入することも、取り組むことができる方向の 1 つです。 #- 回答拒否 (12%): モデルが回答を拒否することもよくあります。分析を通じて、彼らはモデルが質問に答えることを拒否したいくつかの理由を指摘しました: (1) モデルが画像から情報を認識できなかった; (2) それは宗教問題または個人的な実生活情報に関わる質問であり、モデルは(3) 質問に性別や主観的な要素が含まれる場合、モデルは直接的な回答を提供することを避けます。 - エラー: 残りのエラーには、テキスト理解エラー (7%)、注釈エラー (2%)、回答抽出エラーが含まれます。 (5%)。これらのエラーは、複雑な構造の追跡機能、複雑なテキスト ロジックの理解、応答生成の制限、データ注釈のエラー、応答一致抽出で遭遇する問題など、さまざまな要因によって発生します。 CMMMU ベンチマークは、高度な汎用人工知能 (AGI) の開発における大きな進歩を示しています。 CMMMU は、最新の大規模マルチモーダル モデル (LMM) を厳密に評価し、基本的な知覚スキル、複雑な論理的推論、特定の領域における深い専門知識をテストするように設計されています。この研究では、中国語と英語のバイリンガル文脈における LMM の推論能力を比較することで、その違いを指摘しました。この詳細な評価は、モデルが各分野の経験豊富な専門家の熟練度にどの程度達していないかを判断する上で重要です。 結論
以上が中国の LMM 体格に適した最新のベンチマーク CMMMU: 30 を超えるサブディビジョンと 12,000 の専門家レベルの質問が含まれていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



