


「若者初のマルチモーダル大型モデル」Vary-toyが登場!
モデル サイズは 2B 未満で、コンシューマー グレードのグラフィック カードでトレーニングでき、GTX1080ti 8G の古いグラフィック カードでも簡単に実行できます。
ドキュメント画像を Markdown 形式に変換したいですか?以前は、テキスト認識、レイアウトの検出と並べ替え、数式テーブルの処理、テキストのクリーニングなどの複数の手順が必要でした。
これで必要なコマンドは 1 つだけです:
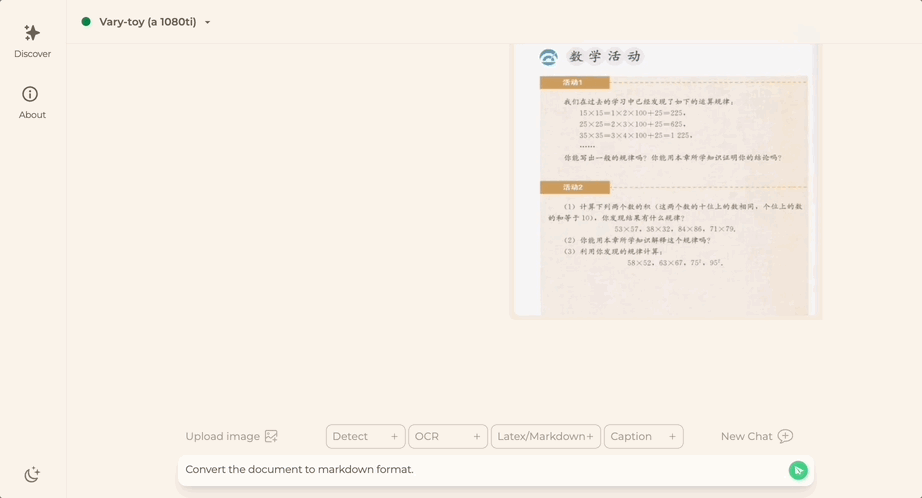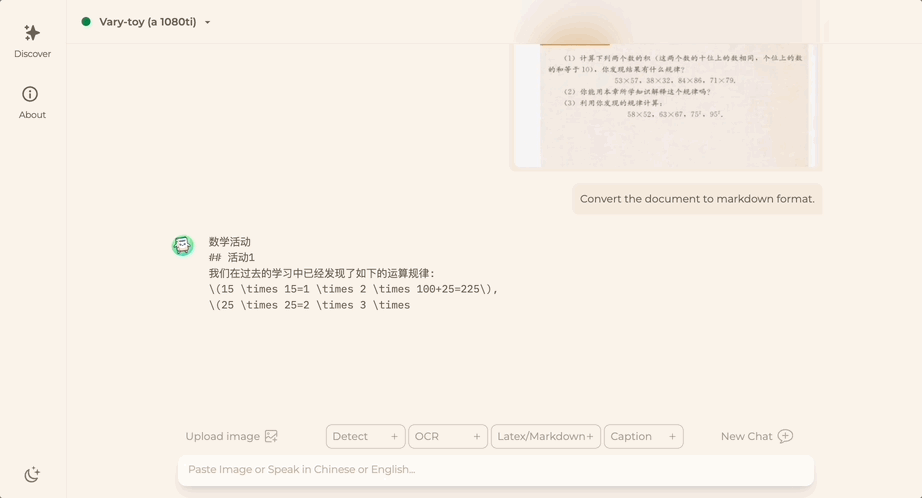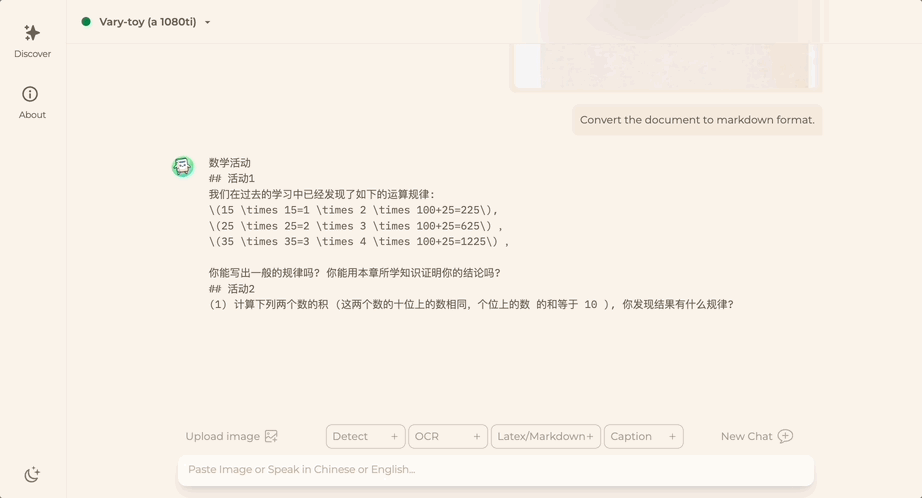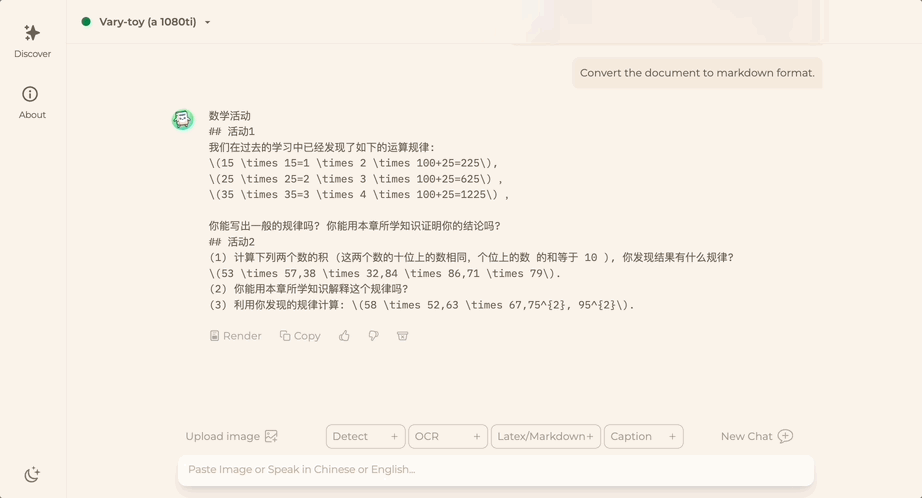
中国語でも英語でも、画像内のテキストの大部分を抽出できます。数分で:

画像上の物体検出でも特定の座標を得ることができます:

この研究は共同で提案されましたMegvii、国立科学技術大学、華中科学技術大学の研究者による。
報告書によると、Vary-toy は小規模ではありますが、LVLM (大規模視覚言語モデル) に関する現在の主流研究のほぼすべての機能をカバーしています。: 文書 OCR 認識 (文書OCR )、視覚的な位置決め(視覚的なグラウンディング)、画像の説明(画像キャプション)、視覚的な質問応答(VQA)。

現在、Vary-toy のコードとモデルはオープンソースであり、試用できるオンライン デモが用意されています。

ネチズンは関心を示しましたが、老·GTX1080 にも注目し、次のように感じました。 ##「縮小版」 Vary
実際、Vary チームは昨年 12 月には Vary の最初の研究成果「Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models」を発表しました。 
Vary と比較すると、Vary-toy は小さいだけでなく、より強力な視覚語彙
を訓練します。新しい語彙はモデルをドキュメント レベルの OCR に制限しなくなりました。より普遍的で包括的な視覚語彙。ドキュメント レベルの OCR だけでなく、一般的な視覚ターゲットの検出も実行できます。 それでは、これはどのように行われるのでしょうか?Vary-toy のモデル構造と学習プロセスは下図に示すとおりであり、学習は大きく 2 つの段階に分かれています。
まず、最初の段階では、Vary-tiny 構造を使用して、元の Vary よりも優れたビジュアル語彙を事前にトレーニングします。オリジナルの Vary の問題を解決します。Vary はドキュメント レベルの OCR にのみ使用するため、ネットワーク容量が無駄になり、SAM 事前トレーニングの利点が十分に活用されないという問題があります。
次に、第 2 段階では、第 1 段階でトレーニングされた視覚語彙が、マルチタスク トレーニング/SFT の最終構造にマージされます。
ご存知のとおり、包括的な機能を備えた VLM を作成するには、優れたデータ比率が不可欠です。 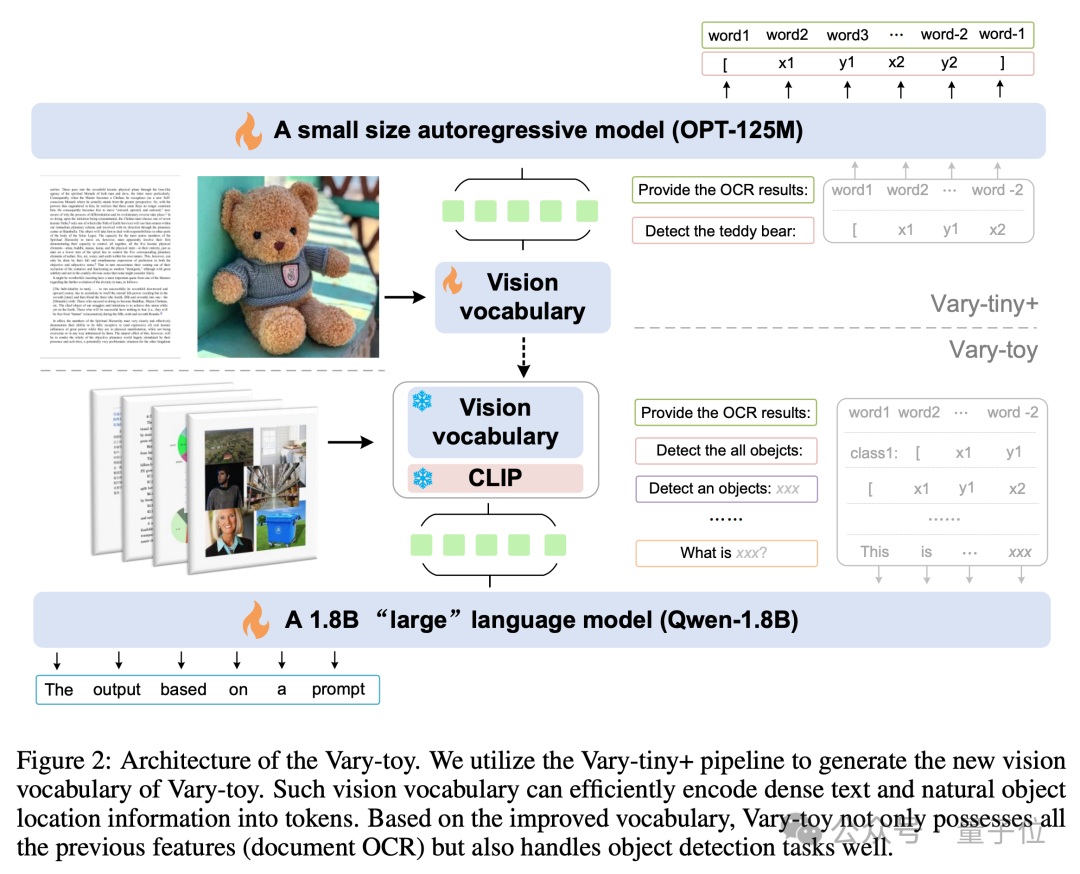
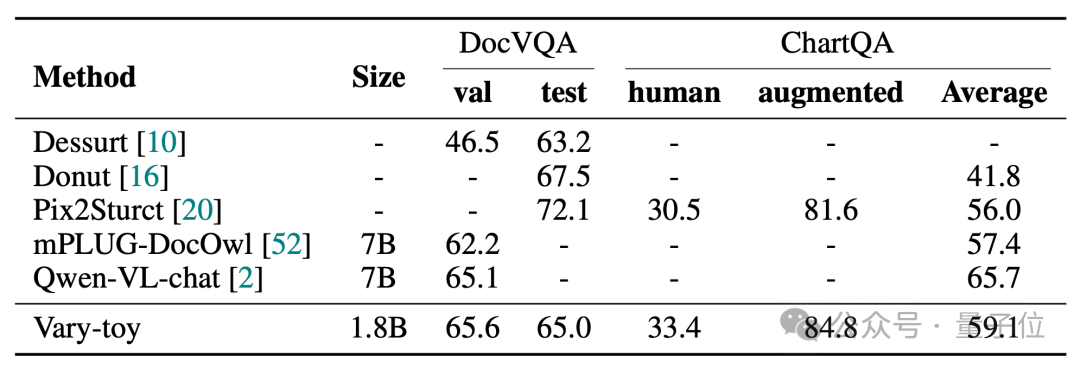
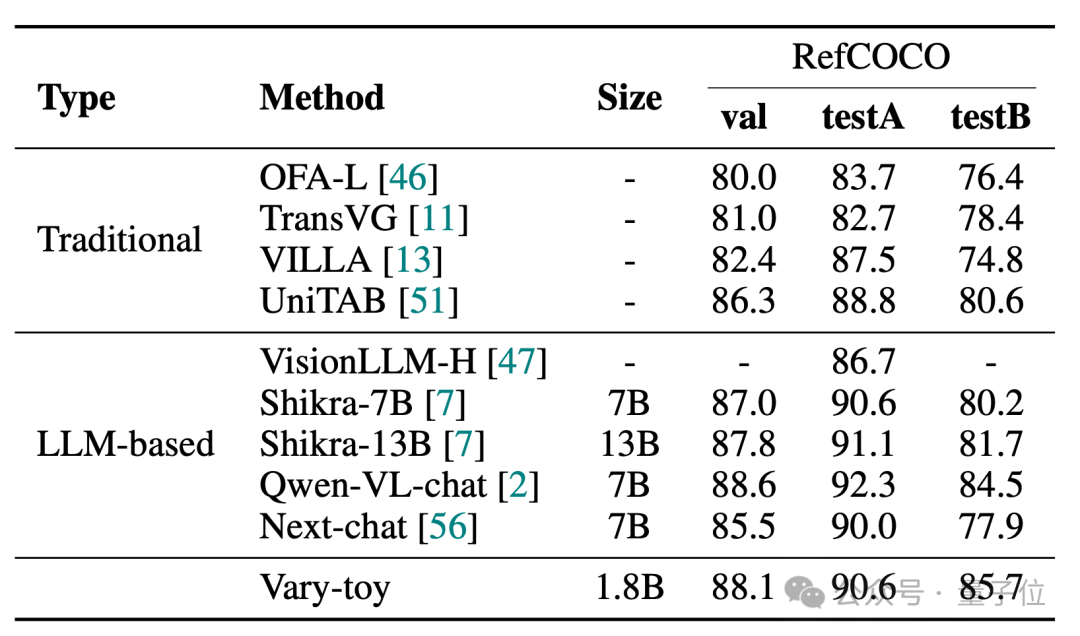
Vary-toy は、DocVQA で 65.6% の ANLS、ChartQA で 59.1%、RefCOCO で 88.1% の精度を達成できます:
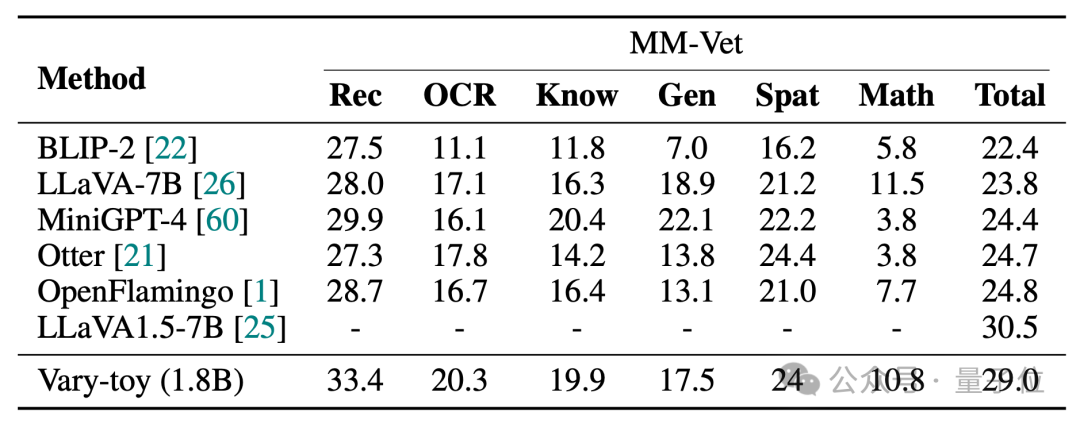
MMVet の精度は 29% に達し、ベンチマーク スコアや視覚化効果の点でも、2B 未満の Vary-toy は、一部の人気の 7B モデルのパフォーマンスにさえ匹敵します。
プロジェクト リンク:
[1]https://arxiv.org/abs/2401.12503
[3] https://varytoy.github.io/
以上がマルチモーダルな大型モデルはオープンソースでオンラインの若者に好まれています: 1080Ti を簡単に実行の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



