


教師なし学習では、機械はラベルなしのデータを使用して、監視なしで自律的に学習します。マシンは、ラベルのないデータ内のパターンを発見し、それに応じて反応しようとします。
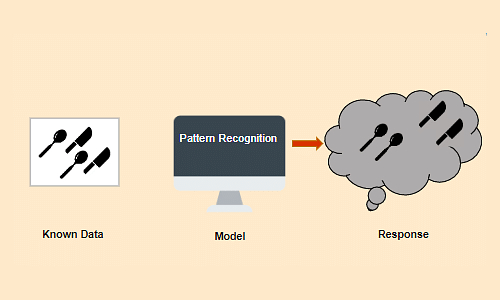
以下に示すように、前の例に基づいており、今回はスプーンかナイフかを事前にマシンに伝えません。マシンは指定されたデータを認識し、パターンや類似性などの特性に基づいてデータをグループ化します。
 #教師なし学習の種類
1. クラスタリング
クラスタリングとは、オブジェクトを類似したメソッドに分割することです。相互に似ていますが、別のクラスに属するオブジェクトとは異なります。
たとえば、ある電気通信会社は、パーソナライズされた通話プランとデータ プランを提供することで顧客離れを削減しました。彼らは顧客の行動を研究し、モデルを使用して同様の特性を持つ顧客をセグメント化します。その後、適切なプロモーションやイベントなどのさまざまな戦略を採用して、顧客離れを最小限に抑え、利益を最大化します。そうすることで、顧客のニーズをより適切に満たし、顧客満足度を向上させ、顧客ロイヤルティと顧客維持率を向上させることができます。パーソナライズされたソリューションを通じて、電気通信会社は既存顧客を効果的に維持し、新規顧客を引き付けて、長期的なビジネス目標を達成できます。
2. アソシエーション
アソシエーションは、コレクション内のアイテムが同時に出現する確率を発見するために使用されるルールベースの機械学習です。
たとえば、顧客 A がパン、牛乳、果物、小麦を買うためにスーパーマーケットに行くとします。別の顧客Bがパン、牛乳、米、バターを買いに来ます。さて、顧客 C が来たとき、パンを買うなら、おそらく牛乳も欲しくなるでしょう。したがって、顧客行動の購入パターンに基づいて関係を構築し、顧客 C に牛乳の購入を勧めることができます。これにより売上が増加し、顧客のニーズが満たされます。
教師なし学習の実用化
1. 商品分析
アルゴリズムに基づいた機械学習モデルです。別のアイテムを購入すると、アイテムのグループの可能性が減少または増加します。
2. 意味的クラスタリング
意味的に類似した単語は、類似したコンテキストを共有します。人々は独自の方法で Web サイトにクエリを投稿します。セマンティック クラスタリングは、同じ意味を持つこれらすべての応答を 1 つのクラスターにグループ化し、顧客が探している情報を迅速かつ簡単に見つけられるようにします。情報の検索、優れた閲覧体験、理解において重要な役割を果たします。
3. 需要と供給の最適化
機械学習モデルは、需要を予測し、供給を維持するために使用されます。また、需要が高い場所に店舗をオープンしたり、過去のデータや行動に基づいてより効率的な配送を実現する根本原因を最適化するためにも使用されます。
4.事故が発生しやすい領域を特定する
教師なし機械学習モデルを使用して、事故が発生しやすい領域を特定し、事故の強度に基づいて安全対策を導入できます。
#教師なし学習の種類
1. クラスタリング
クラスタリングとは、オブジェクトを類似したメソッドに分割することです。相互に似ていますが、別のクラスに属するオブジェクトとは異なります。
たとえば、ある電気通信会社は、パーソナライズされた通話プランとデータ プランを提供することで顧客離れを削減しました。彼らは顧客の行動を研究し、モデルを使用して同様の特性を持つ顧客をセグメント化します。その後、適切なプロモーションやイベントなどのさまざまな戦略を採用して、顧客離れを最小限に抑え、利益を最大化します。そうすることで、顧客のニーズをより適切に満たし、顧客満足度を向上させ、顧客ロイヤルティと顧客維持率を向上させることができます。パーソナライズされたソリューションを通じて、電気通信会社は既存顧客を効果的に維持し、新規顧客を引き付けて、長期的なビジネス目標を達成できます。
2. アソシエーション
アソシエーションは、コレクション内のアイテムが同時に出現する確率を発見するために使用されるルールベースの機械学習です。
たとえば、顧客 A がパン、牛乳、果物、小麦を買うためにスーパーマーケットに行くとします。別の顧客Bがパン、牛乳、米、バターを買いに来ます。さて、顧客 C が来たとき、パンを買うなら、おそらく牛乳も欲しくなるでしょう。したがって、顧客行動の購入パターンに基づいて関係を構築し、顧客 C に牛乳の購入を勧めることができます。これにより売上が増加し、顧客のニーズが満たされます。
教師なし学習の実用化
1. 商品分析
アルゴリズムに基づいた機械学習モデルです。別のアイテムを購入すると、アイテムのグループの可能性が減少または増加します。
2. 意味的クラスタリング
意味的に類似した単語は、類似したコンテキストを共有します。人々は独自の方法で Web サイトにクエリを投稿します。セマンティック クラスタリングは、同じ意味を持つこれらすべての応答を 1 つのクラスターにグループ化し、顧客が探している情報を迅速かつ簡単に見つけられるようにします。情報の検索、優れた閲覧体験、理解において重要な役割を果たします。
3. 需要と供給の最適化
機械学習モデルは、需要を予測し、供給を維持するために使用されます。また、需要が高い場所に店舗をオープンしたり、過去のデータや行動に基づいてより効率的な配送を実現する根本原因を最適化するためにも使用されます。
4.事故が発生しやすい領域を特定する
教師なし機械学習モデルを使用して、事故が発生しやすい領域を特定し、事故の強度に基づいて安全対策を導入できます。
以上が教師なし学習: 概念、種類、および応用の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



