大型モデルの分野におけるトランスフォーマーの地位は揺るぎません。ただし、モデルの規模が拡大し、シーケンスの長さが増加するにつれて、従来の Transformer アーキテクチャの限界が明らかになり始めます。幸いなことに、Mamba の出現により、この状況は急速に変わりつつあります。その卓越したパフォーマンスはすぐに AI コミュニティにセンセーションを巻き起こしました。 Mamba の出現は、大規模なモデルのトレーニングとシーケンス処理に大きな進歩をもたらしました。その利点は AI コミュニティに急速に広がり、将来の研究と応用に大きな期待をもたらしています。
先週の木曜日、Vision Mamba (Vim) の導入により、ビジュアル ベーシック モデルの次世代のバックボーンとなる大きな可能性が実証されました。わずか 1 日後、中国科学院、ファーウェイ、彭城研究所の研究者は、VMamba:グローバルな受容野と線形複雑性を備えた視覚的な Mamba モデルを提案しました。 この作品は、視覚的なマンバ モデル Swin の瞬間の到来を示します。

- 論文のタイトル: VMamba: ビジュアル状態空間モデル
#ペーパーアドレス: https://arxiv.org/abs/2401.10166-
#CNN と Visual Transformer (ViT) は、現在最も主流の 2 つの基本的なビジュアル モデルです。 CNN は線形の複雑さを持っていますが、ViT はより強力なデータ フィッティング機能を備えていますが、その代わりに計算の複雑さが高くなります。
研究者らは、ViT にはグローバルな受容野と動的重みがあるため、強力なフィッティング能力があると考えています。 Mamba モデルに触発されて、研究者たちは、線形複雑さの下で両方の優れた特性を備えたモデル、つまり Visual State Space Model (VMamba) を設計しました。
大規模な実験により、VMamba がさまざまな視覚的なタスクで適切にパフォーマンスを発揮することが証明されました。 下の図に示すように、VMamba-S は ImageNet-1K 上で 83.5% の精度を達成します。これは Vim-S より 3.2%、Swin-S より 0.5% 高くなります。
#メソッドの紹介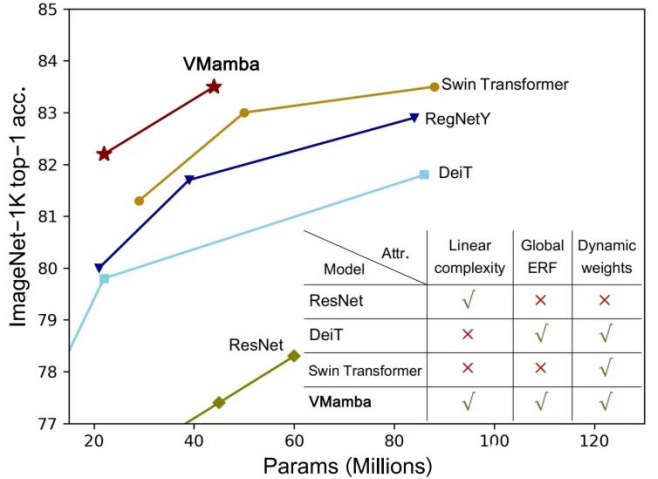
成功VMamba 鍵となるのは、もともと自然言語処理 (NLP) タスクを解決するために設計された S6 モデルの使用です。 ViT のアテンション メカニズムとは異なり、S6 モデルは、1D ベクトルの各要素を以前のスキャン情報と相互作用させることにより、二次複雑性を線形性に効果的に軽減します。この対話により、大規模なデータを処理する際の VMamba の効率が向上します。したがって、S6 モデルの導入は、VMamba の成功の強固な基盤を築きました。 
ただし、視覚信号 (画像など) にはテキストシーケンスのような自然な秩序性がないため、S6 のデータ スキャン方法を単純に視覚信号に対して直接実行することはできません。この目的のために、研究者はクロススキャン スキャン機構を設計しました。 クロススキャン モジュール (CSM) は、4 方向のスキャン戦略、つまり、特徴マップの 4 つの隅から同時にスキャンする戦略を採用しています (上の図を参照)。
この戦略により、フィーチャ内の各要素が他のすべての場所からの情報をさまざまな方向に統合し、線形の計算の複雑さを増加させることなくグローバルな受容野を形成することが保証されます。
CSM に基づいて、著者は 2D 選択的スキャン (SS2D) モジュールを設計しました。上の図に示すように、SS2D は 3 つのステップで構成されます。 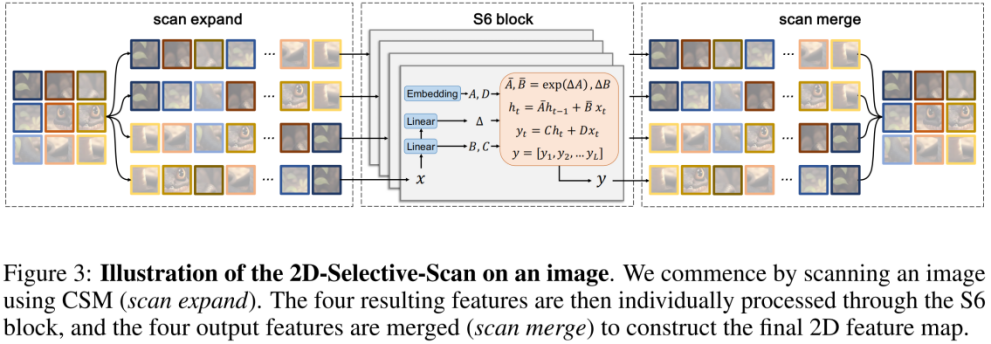
#scan Expand 2D フィーチャを 4 つの異なる方向 (左上、右下、左下、上) にフラット化する右) は 1D ベクトルです。
- S6 ブロックは、前のステップで取得した 4 つの 1D ベクトルを独立して S6 オペレーションに送信します。
- スキャン マージは、取得された 4 つの 1D ベクトルを 2D 特徴出力に融合します。
#上の図は、この記事で提案する VMamba の構造図です。 VMamba の全体的なフレームワークは主流のビジュアル モデルに似ていますが、主な違いは基本モジュール (VSS ブロック) で使用される演算子にあります。 VSS ブロックは、上で紹介した 2D 選択的スキャン操作、つまり SS2D を使用します。 SS2D は、VMamba が
線形複雑さ 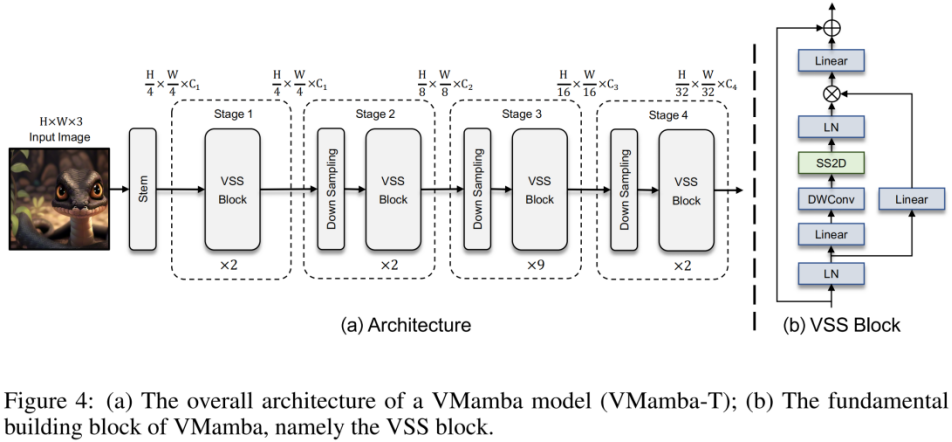 のコストで
のコストで
グローバル受容野を達成することを保証します。
#実験結果
ImageNet 分類
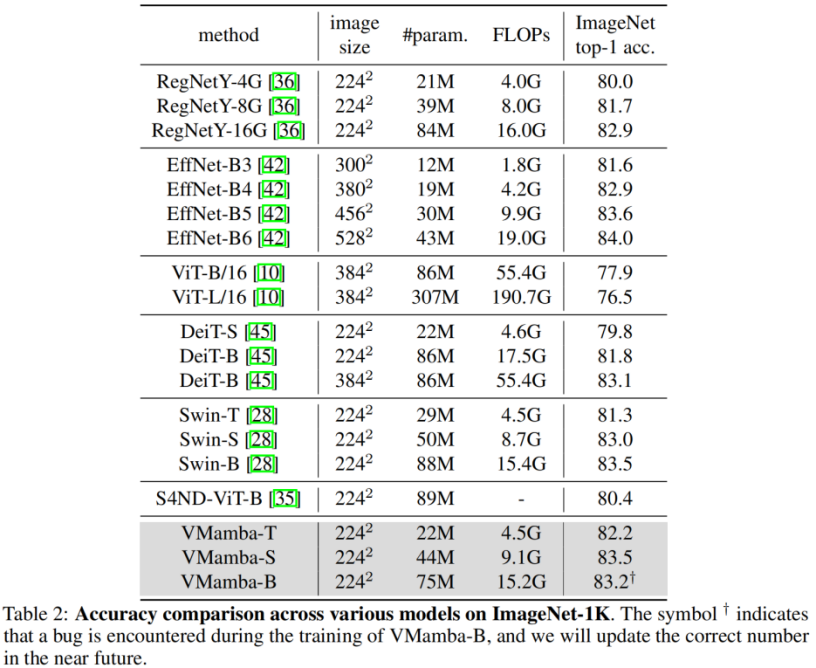
#合格 比較実験結果を見ると、同様のパラメータ量と FLOP の下で、
VMamba-T は - 82.2% のパフォーマンスを達成し、次のことを確認するのは難しくありません。 RegNetY-4G は 2.2%、DeiT-S は 2.4%、Swin-T は 0.9% に達しました。
VMamba-S は - 83.5% のパフォーマンスを達成し、RegNetY-8G を 1.8%、Swin-S を 0.5% 上回りました。
VMamba-B は - 83.2% のパフォーマンスを達成しました (バグがあります。正しい結果はできるだけ早く Github ページで更新されます)。 RegNetYより0.3%高いです。
これらの結果は、Vision Mamba (Vim) モデルよりもはるかに優れており、VMamba の可能性を完全に検証しています。
COCO ターゲットの検出
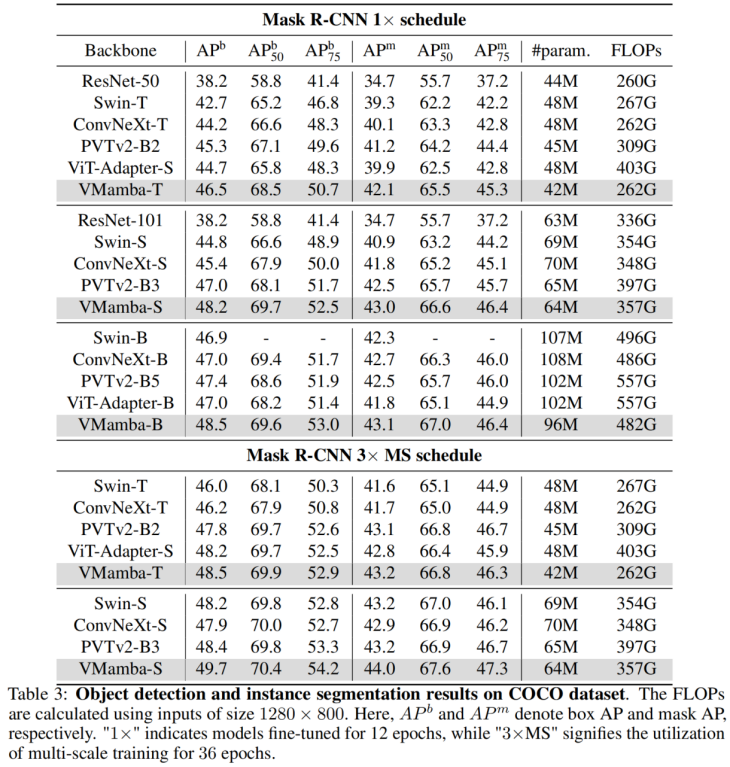
COOCO データ セットでは、VMamba も優れたパフォーマンスの維持: 12 エポックの微調整の場合、VMamba-T/S/B はそれぞれ 46.5%/48.2%/48.5% mAP に達し、Swin-T/S/B を 3.8%/3.6%/1.6% 上回りました。 mAP、ConvNeXt-T/S/B を 2.3%/2.8%/1.5% mAP 上回ります。これらの結果は、VMamba が下流のビジュアル実験で完全に機能することを検証し、主流の基本的なビジュアル モデルを置き換える可能性を示しています。
ADE20K セマンティック セグメンテーション
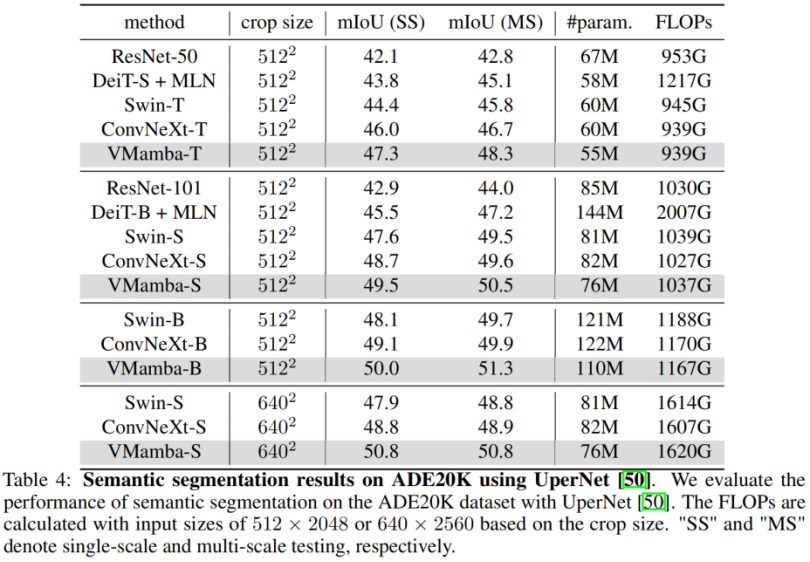
ADE20K では、VMamba も優れたパフォーマンスを示します。 VMamba-T モデルは、512 × 512 の解像度で 47.3% の mIoU を達成し、これは ResNet、DeiT、Swin、ConvNeXt を含むすべての競合他社を上回るスコアです。この利点は、VMamba-S/B モデルでも引き続き維持できます。
分析実験
有効受容野
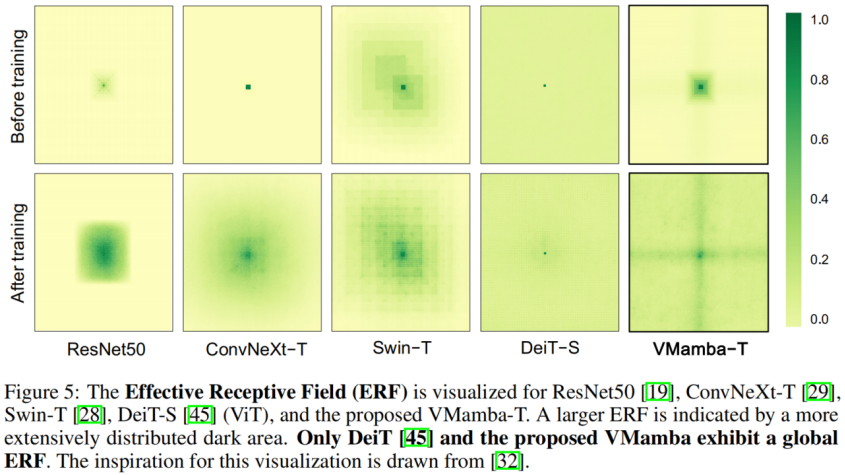
VMamba はグローバルな有効受容野を備えており、この機能を備えているのは他のモデルの中で DeiT だけです。ただし、DeiT のコストは二次計算量であるのに対し、VMamaba は線形計算量であることに注意してください。
#入力スケール スケーリング
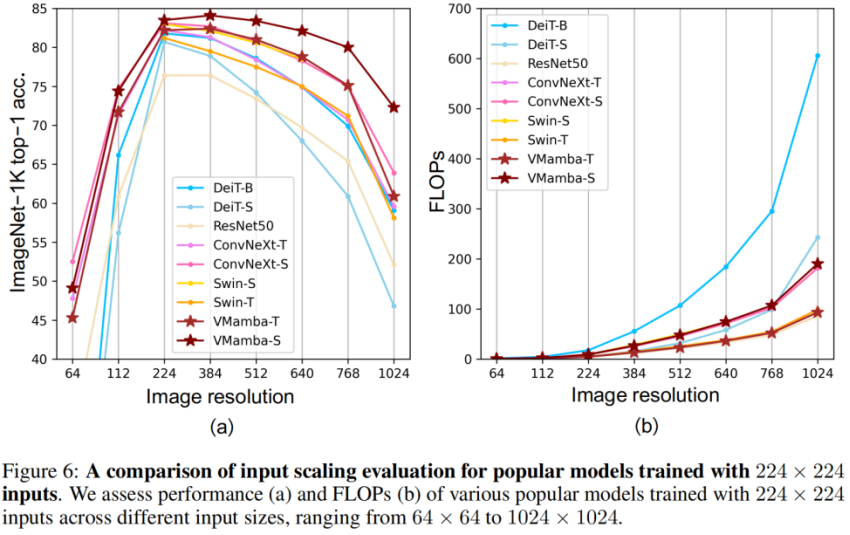
上の図 (a) VMamba は、さまざまな入力画像サイズの下で (微調整なしで) 最も安定したパフォーマンスを示すことが示されています。興味深いことに、入力サイズが 224 × 224 から 384 × 384 に増加するにつれて、VMamba のみがパフォーマンスの大幅な向上を示し (VMamba-S は 83.5% から 84.0% に)、入力画像サイズの性別の変化に対する堅牢性が強調されています。
-
上の図 (b) は、入力が大きくなるにつれて VMamba シリーズ モデルの複雑さが直線的に増加することを示しており、これは CNN モデルと一致しています。
以上がビジュアル Mamba モデルの Swin の瞬間、中国科学院、ファーウェイなどが VMamba を立ち上げの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



