


強化学習アルゴリズム (強化学習、RL) のトレーニング プロセスでは、通常、それをサポートするために環境と対話する大量のサンプル データが必要です。しかし、現実の世界では、UAV の空戦訓練や自動運転訓練など、多数のインタラクション サンプルを収集するのに非常に費用がかかることや、サンプリング プロセスの安全性が確保できないことがよくあります。この問題により、多くの実際のアプリケーションにおける強化学習の範囲が制限されます。したがって、研究者たちは、この問題を解決するために、サンプルの効率と安全性のバランスをとる方法を探求することに熱心に取り組んできました。考えられる解決策の 1 つは、シミュレーターまたは仮想環境を使用して大量のサンプル データを生成し、現実世界の状況におけるコストとセキュリティのリスクを回避することです。さらに、トレーニングプロセス中の強化学習アルゴリズムのサンプル効率を向上させるために、一部の研究者は表現学習テクノロジーを使用して、将来の状態信号を予測するための補助タスクを設計しました。このようにして、アルゴリズムは、元の環境状態から将来の決定に関連する特徴を抽出してエンコードできます。このアプローチの目的は、環境に関するより多くの情報を学習し、意思決定のためのより良い基盤を提供することで、強化学習アルゴリズムのパフォーマンスを向上させることです。このようにして、アルゴリズムはトレーニング プロセス中にサンプル データをより効率的に使用し、学習プロセスを加速し、意思決定の精度と効率を向上させることができます。
このアイデアに基づいて、この研究では、将来の複数のステップの 状態シーケンスの周波数領域分布
を予測し、長期的な将来の決定を捉える補助タスクを設計しました。特徴を作り、それによってアルゴリズムのサンプル効率を向上させます。この研究のタイトルは「表現学習のためのフーリエ変換による状態シーケンス予測」であり、NeurIPS 2023 で公開され、Spotlight として承認されました。
# 著者リスト: Ye Mingxuan、Kuang Yufei、Wang Jie*、Yang Rui、Zhou Wengang、Li Houqiang、Wu Feng

論文リンク: https://openreview.net/forum?id=MvoMDD6emT
コードリンク: https://github.com/MIRALab-USTC/ RL-SPF /
研究の背景と動機
サンプル効率を向上させるために、研究者は表現学習に注目し始めており、トレーニングによって得られた表現が環境の元の状態から豊富で有用な特徴情報を抽出できることを期待しています。状態空間での探索効率を向上させ、ロボットのパフォーマンスを向上させます。
#表現学習に基づく強化学習アルゴリズム フレームワーク
逐次意思決定タスクでは、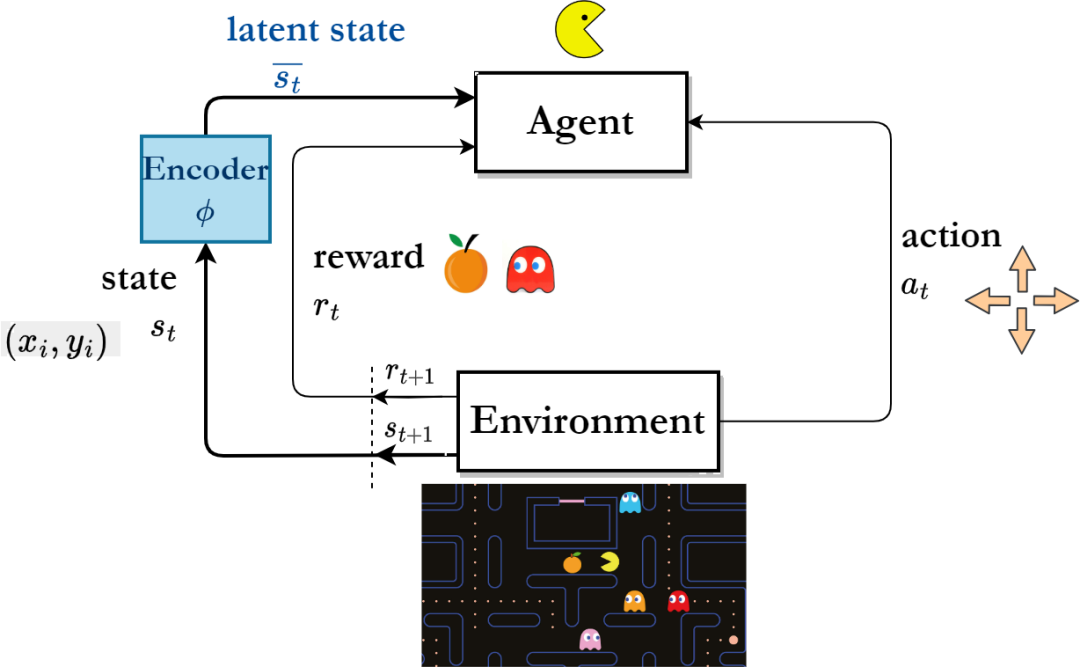 「長期シーケンスシグナル」
「長期シーケンスシグナル」
既存の 2 つの方法のうち、1 つの方法は、
シングルステップ確率伝達モデルを学習して複数のステップの状態を間接的に予測することで、ある瞬間の将来の状態を段階的に生成します。シーケンス [6,7]。ただし、このタイプの方法では、予測シーケンスの長さが増加するにつれて各ステップでの予測誤差が蓄積されるため、トレーニングされた確率伝達モデルの高精度が必要になります。
別のタイプの方法は、将来の複数のステップの状態シーケンスを直接予測することで表現学習 [8] を支援します ただし、このタイプの方法では、複数のステップの実際の状態 シーケンスは、予測タスクのラベルとして、大量のストレージを消費します。したがって、環境の状態列から長期的な意思決定に有益な将来情報をどのように効率的に抽出し、制御ロボットの継続学習におけるサンプル効率を向上させるかが解決すべき課題となっている。
上記の問題を解決するために、我々は状態系列 (State Sequences P##) の周波数領域予測に基づく表現学習手法を提案します。 Fウーリエ変換、
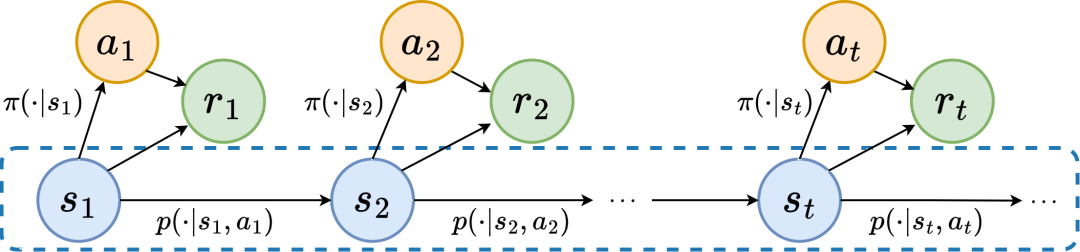
SPF による #予測)、そのアイデアは、「状態シーケンスの周波数領域分布」 を使用して、状態シーケンス データの傾向とパターンを明示的に抽出することです。これにより、長期的な将来の情報を効率的に抽出するための表現を支援します。 状態列には 「2 種類の構造情報」が存在することを理論的に証明しました。 1 つは 戦略のパフォーマンス に関連するトレンド情報であり、もう 1 つは 状態の周期性 に関連する定期的な情報です。 2 つの構造情報を詳細に分析する前に、まず状態シーケンスを生成するマルコフ決定を紹介します。プロセス (マルコフ決定プロセス、MDP)。 連続制御問題における古典的なマルコフ決定プロセスを検討します。これは 5 つのタプルで表すことができます。その中で、 は対応する状態とアクション空間、 は報酬関数、 は環境の状態遷移関数、 は状態の初期分布、 は割引係数です。また、状態におけるポリシーのアクション分布を表すために を使用します。 時刻におけるエージェントの状態を として記録し、選択されたアクションを として記録します。エージェントがアクションを行った後、環境は次の状態に移行し、インテリジェンスにフィードバックされます。身体のご褒美。エージェントと環境の間の相互作用中に得られる状態とアクションに対応する軌跡を として記録し、その軌跡は分布に従います。 強化学習アルゴリズムの目標は、将来の期待累積リターンを最大化することです。現在の戦略と環境モデルの下での平均累積リターンを を使用して表し、 と略します。これは次のように定義されます。 現在の戦略のパフォーマンスを示します。 次に、依存関係を含む状態シーケンスの 「最初の構造的特徴」 を紹介します。状態シーケンスと対応する報酬シーケンスの間で、 現在の戦略のパフォーマンス傾向を示すことができます。 上記の構造に触発されて、この構造的な依存関係の存在をさらに証明するために次の定理を証明します。
定理 1 : 報酬関数が状態にのみ関連する場合、任意の 2 つの戦略と について、それらのパフォーマンスの差は、これら 2 つの戦略によって生成される状態シーケンス分布の違いによって制御できます。 ##上記の式において、 は指定されたポリシーおよび遷移確率関数の下での状態系列の確率分布を表し、ノルムを表します。 上記の定理は、2 つの戦略間のパフォーマンスの差が大きければ大きいほど、対応する 2 つの状態シーケンス間の分布の差も大きくなることを示しています。これは、良い戦略と悪い戦略が 2 つのまったく異なる状態シーケンスを生成することを意味します。これは、状態シーケンスに含まれる長期的な構造情報が、優れたパフォーマンスを伴う検索戦略の効率に潜在的に影響を与える可能性があることをさらに示しています。 一方、特定の条件下では、次の定理に示すように、状態シーケンスの周波数領域分布の違いが、対応するポリシーのパフォーマンスの違いの上限を与える可能性もあります。 定理 2 : 状態空間が有限次元で、報酬関数が状態に関連する n 次の多項式である場合、任意の 2 つの戦略に対して、 、それらのパフォーマンスの違いは、次の 2 つの戦略によって生成された状態シーケンスの周波数領域分布の違いによって制御されます: 上の式で、 はべき乗のフーリエ関数を表します。ストラテジによって生成された状態シーケンスのシーケンス。フーリエ関数の成分を表します。 この定理は、 がまだ含まれていることを示しています。 #定期情報 規則的なパターン。 実際のシナリオのタスクの多くでは、エージェントの環境自体の状態遷移関数が周期的であるため、エージェントも周期的な動作を示します。産業用組立ロボットを例にとると、ロボットは部品を組み立てて最終製品を作成するように訓練されています。戦略訓練が安定に達すると、Togetter で部品を効率的に組み立てることができる周期的なアクション シーケンスを実行します。 上記の例から着想を得て、有限状態空間において、遷移確率行列が特定の仮定を満たした場合、対応する状態シーケンスがエージェント内で安定に達することを証明するために、いくつかの理論的分析を提供します。この戦略は 「漸近周期性」 を示す可能性があります。特定の定理は次のとおりです: #定理 3: の有限状態遷移行列の場合次元状態空間 、サイクル クラスがあると仮定すると、対応する状態遷移部分行列は次のようになります。この行列の法 1 の固有値の数が であると仮定すると、任意の状態の初期分布について、状態分布は周期 で漸近的な周期性を示します。 MuJoCo タスクでは、戦略トレーニングが安定に達すると、エージェントも周期的な動きを示します。以下の図は、一定期間にわたる MuJoCo タスクにおける HalfCheetah エージェントの状態シーケンスの例を示しており、明らかな周期性が観察されます。 (MuJoCo タスクの周期的状態シーケンスのその他の例については、この文書の付録のセクション E を参照してください)。 MuJoCo タスク 一定期間内の状態によって示される周期性 手法の紹介 前のパートでは、状態シーケンスの周波数領域の分布が戦略のパフォーマンスを反映できることを理論的に証明しました。周波数領域で周波数成分を分析することにより、状態シーケンスの周期的特徴を明示的に捉えることができます。 という補助タスクを設計して、抽出された状態シーケンスの性的情報の構造。 次に、この補助タスクのモデル化を紹介します。現在の状態とアクションを考慮して、予想される将来の状態シーケンスを次のように定義します。 私たちの補助タスクは、予想される状態シーケンスを予測するために表現をトレーニングします。上記の離散時間フーリエ変換 (DTFT)、つまり 上記のフーリエ変換式は、次の再帰形式として書き直すことができます。
##それら、 は状態空間の次元、 は予測された状態シーケンスのフーリエ関数の離散化点の数です。 その中には、損失関数を最適化する必要がある表現エンコーダー (エンコーダー) とフーリエ関数予測器 (プレディクター) のニューラル ネットワーク パラメーターと、サンプル データを保存するためのエクスペリエンス プールが含まれます。 さらに、上記の再帰式が圧縮マップとして表現できることを証明できます。 定理 4 : 関数ファミリーを表し、ノルムを次のように定義します。 ## ここで、 は行列の行ベクトルを表します。マッピングを として定義すると、それが圧縮マッピングであることが証明できます。 圧縮マッピングの原理に従って、演算子を繰り返し使用して実際の状態シーケンスの周波数領域分布を近似することができ、表形式の設定で収束が保証されます。 さらに、私たちが設計した損失関数は現時点と次の瞬間の状態にのみ依存するため、将来的に複数のステップの状態データを保存する必要はありません 実装が簡単でストレージ容量が少ないという利点があります。
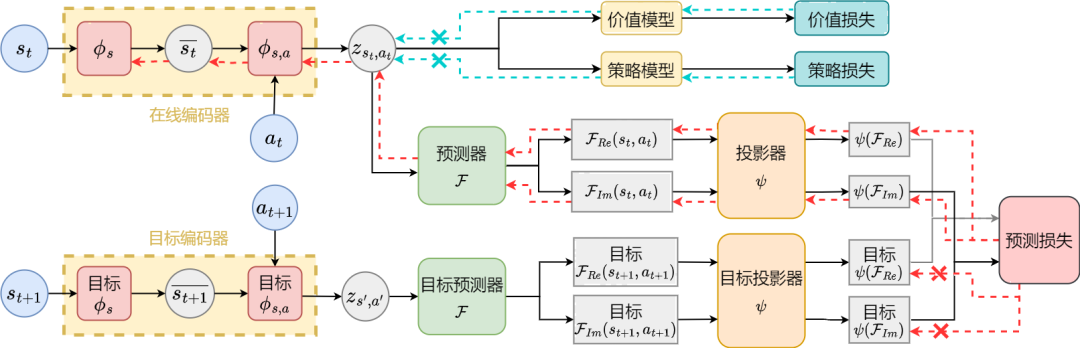
状態系列周波数領域予測に基づく表現学習法(SPF)のアルゴリズムフレームワーク図 損失関数を最小化することで表現エンコーダとフーリエ関数予測器を最適化および更新し、予測器の出力が実際の状態シーケンスのフーリエ変換に近似できるようにします。表現エンコーダは、将来の長期状態シーケンスに関する構造情報を含む特徴を抽出します。 元の状態とアクションを表現エンコーダーに入力し、得られた特徴を強化学習アルゴリズムのアクター ネットワークと批評家ネットワークへの入力として使用し、アクター ネットワークを最適化します。古典的な強化学習アルゴリズムと批評家ネットワーク。 実験結果 (注: このセクションでは実験結果の一部のみを抜粋しています。より詳細な結果については、セクション 6 とセクション 6 を参照してください。 .) アルゴリズム性能比較
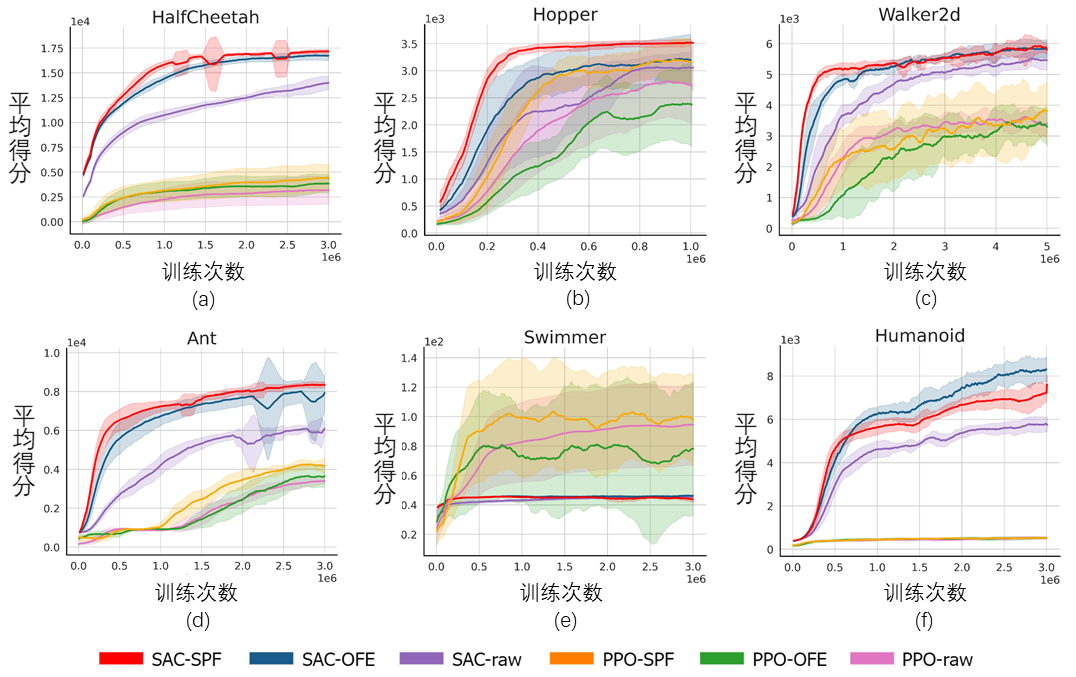
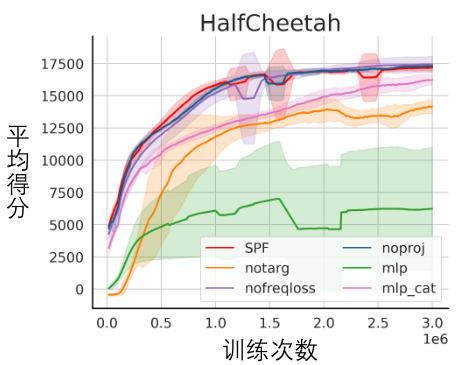
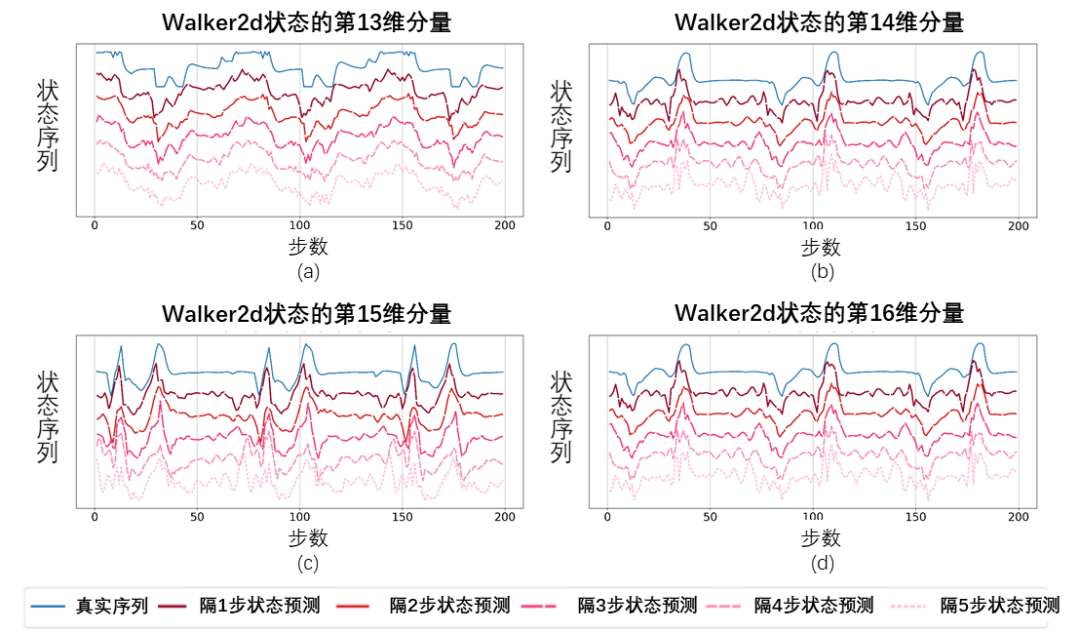
上の図は、6 つの MuJoCo タスクにおける、私たちが提案する SPF 手法 (赤線とオレンジ線) と他の比較手法のパフォーマンス曲線を示しています。結果は、私たちの提案手法が他の手法と比較して 19.5% のパフォーマンス向上を達成できることを示しています。 SPF 法の各モジュールについてアブレーション実験を実施し、SPF 法を使用しない方法と比較しました。プロジェクター モジュール (noproj) を使用し、ターゲット ネットワーク モジュールを使用しない場合 (notarg)、予測損失を変更する場合 (nofreqloss)、および特徴エンコーダー ネットワーク構造を変更する場合 (mlp、mlp_cat) のパフォーマンスを比較します。 #HalfCheetah タスクでテストされた、SAC アルゴリズムに適用された SPF メソッドのアブレーション実験結果図 SPF法を使用します訓練された予測器は状態シーケンスのフーリエ関数を出力し、逆フーリエ変換##を渡します#復元された 200 ステップのステータス シーケンスと実際の 200 ステップのステータス シーケンスを比較します。 Walker2d タスクでテストされた、フーリエ関数の予測値に基づいて復元された状態シーケンスの概略図。このうち、青い線は実際の状態シーケンスの模式図、5 本の赤い線は復元された状態シーケンスの模式図で、下と薄い赤の線はより長い履歴状態を使用して復元された状態シーケンスを表します。 状態列の構造情報の解析
マルコフ決定プロセス
トレンド情報
ここで、状態シーケンスに存在する 「第 2 の構造的特徴」
を紹介します。状態信号間の時間依存性、つまり、長期間にわたって状態シーケンスによって表示される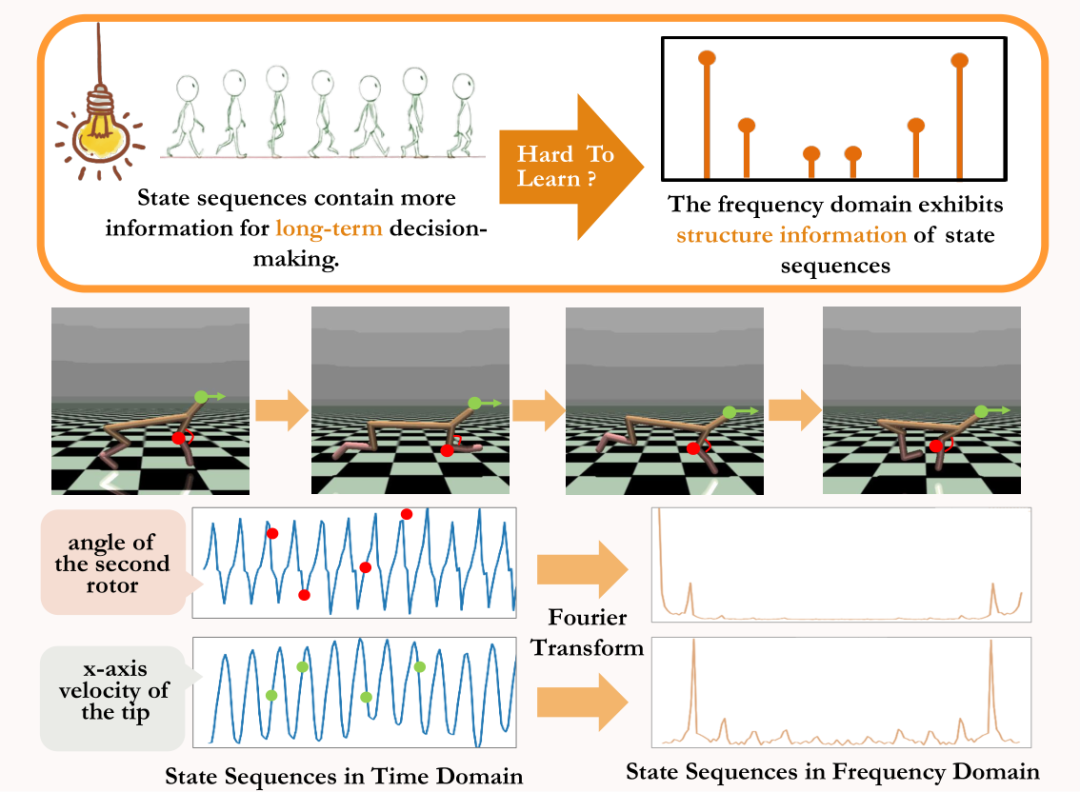 時間領域では時系列によって示される情報は比較的分散していますが、周波数領域では規則的な情報が存在します。シーケンスはより集中して表示されます。周波数領域で周波数成分を分析することにより、状態シーケンスに存在する周期的特性を明示的に捉えることができます。
時間領域では時系列によって示される情報は比較的分散していますが、周波数領域では規則的な情報が存在します。シーケンスはより集中して表示されます。周波数領域で周波数成分を分析することにより、状態シーケンスに存在する周期的特性を明示的に捉えることができます。
上記の分析に触発されて、
「無限ステップの将来状態シーケンスのフーリエ変換を予測する」
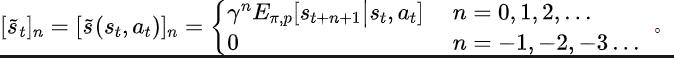
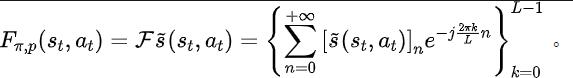
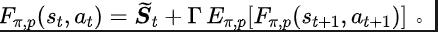
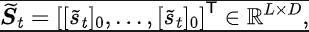 Q 学習の Q 値ネットワークを最適化する TD 誤差損失関数 [9] からインスピレーションを得て、次の損失関数を設計しました。
Q 学習の Q 値ネットワークを最適化する TD 誤差損失関数 [9] からインスピレーションを得て、次の損失関数を設計しました。 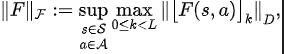
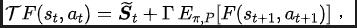
ここで、この論文のメソッド (SPF) のアルゴリズム フレームワークを紹介します。
MuJoCo シミュレーション ロボット制御環境で SPF 手法をテストし、比較しました。次の 6 つのメソッド:
アブレーション実験
可視化実験
以上が中国科学技術大学は、パフォーマンスを 20% 向上させ、サンプル効率を最大化する「状態系列周波数領域予測」手法を開発しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



